Paul Campos forwards along this quote from University of Michigan economist Justin Wolfers:
The income of the average American will double approximately every 39 years. And so when my kids are my age, average income will be roughly double what it is today. Far from being fearful for my kids, I’m envious of the extraordinary riches their generation will enjoy.
I don’t know where to begin with this one! OK, let me begin with what Campos reports: “a quick glance at the government’s historical income tables shows me that the 20th percentile of household income is currently $30,000, while it was $24,000 39 years ago (constant dollars obvi) which is . . . far from doubling.”
This got me curious so I googled *government historical income tables*. Google isn’t entirely broken: the very first link was right here from the U.S. Census. . . . Scrolling down, it looks like we want “Table H-3. Mean Household Income Received by Each Fifth and Top 5 Percent,” which gives a convenient Excel file. Wolfers was writing about “the income of the average American,” which I guess is shorthand for the middle fifth of income. Household income for that category is recorded as $74,730 in 2022 and $55,390 (in 2022 dollars) in 1983, so . . . yeah, not doubling.
On the other hand, Wolfers is talking about his kids, and that’s a different story. They’re at the 99th percentile, not the 50th percentile. And the 99th percentile has done pretty well during the past 39 years! How well? I’m not quite sure. The Census page doesn’t have anything on the top 1%. They do have data on the top 5%, though. Average income in this group was 499,900 in 2022 and 230,600 (in 2022 dollars) . . . hey, that is pretty close to that doubling reported by Wolfers.
But this won’t quite work for Wolfers’s kids either, because regression to the mean. If you’re at the top 1%, your kids are likely to be lower on the relative income ladder than you. I’m sure Wolfers’s kids will do just fine. But maybe they won’t see a doubling of income, compared to what they’re growing up with.
OK, that’s household income. The Census also has a page with trends of family (rather than household) income. Let’s again go to the middle quantile, which is our closest to “the average American”: It’s $93,130 in 2022 and $65,280 (in 2022 dollars) in 1983. Again, not a doubling.
I did some searching and couldn’t find any Census tables for quantiles of individual income, so I guess maybe that’s what doubled in the past 39 years? I’m skeptical, but Wolfers is the economist, and I’m pretty sure his calculations are based on some hard numbers.
Beyond all that, though, there are two other things that bother me about Wolfers’s quote:
1. “Approximately every 39 years”: what kind of ridiculous hyper-precision is this? Incomes go up and down, there are booms and recessions, not to mention inflation and currency fluctuations. In what sense could you possibly make a statement with this sort of precision?
I’m reminded of the story about the tour guide who told people that the Grand Canyon was 5,000,036 years old. When asked how he came up with the number, the grizzled guide replied that, when he started in the job they told him the canyon was 5 million years old, and that was 36 years ago.
2. “The income of the average American will . . .”: Hey, you’re talkin bout the future here. Show some respect for uncertainty! Economists know about that, right? Do you want to preface that sentence with, “If current trends continue” or “According to our models” or . . . something like that?
I guess we can check back in 39 years.
I’m kinda surprised that an economist would write an article, even for a popular audience, that would imply that future income growth is a known quantity. Especially given that elsewhere he argues, or at least implies, that there are major economic consequences depending on which party is in power. If we don’t even know who’s gonna win the upcoming election, and that can affect the economy, how can we possibly know what will happen in the next 39 years?
And here’s another, where Wolfers reports, “For the first time in forever, real wage gains are going to those who need them most.” If something as important as this is happening “for the first time in forever,” then, again, how can you know what will happen four decades from now? All sorts of policy changes might occur, right?
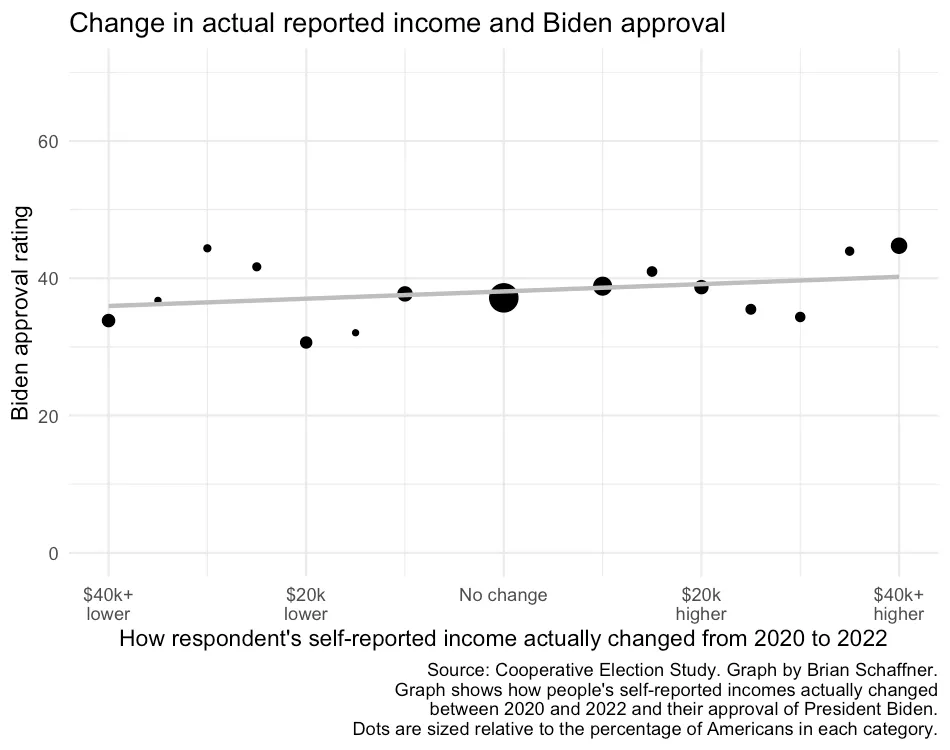
That said, I agree with Campos that Wolfers’s column has value. It’s interesting to read the column in conjunction with the accompanying newspaper comments, as this gives some sense of the differences between averages and individual experiences. Wolfers’s column is all about how individuals can feel one way even as averages are going in a different direction, and that’s interesting. I will say that the even the comments that are negative about the economy are much less negative than you’d see in a recession. In a recession, you see comments about people losing everything; here, the comments are more along the lines of, “It’s supposed to be an economic boom, but we’re still just getting by.” But, sure, if there’s an average growth of 2%, say, then (a) 2% isn’t that much, especially if you have a child or you just bought a new house or car, and (b) not everybody’s gonna be at that +2%: this is the average and roughly half the people doing worse than that. The point is that most people are under economic constraints, and there are all sorts of things that will make people feel these constraints—including things like spending more money, which from an economic consumption standpoint is a plus, but also means you have less cash on hand.
So, lots of paradoxes here at the intersection of politics, economics, and psychology: some of the components of economic growth can make people feel strapped—if they’re focusing on resource constraints rather than consumption.
Aaaaand, the response!
I sent the above to Wolfers, who first shared this note that someone sent to him:
It seems like you were getting a lot of hate in the comments section from people who thought you had too positive a view of the economy—which seemed to just further your point: people feel like the economy is doing awful even though it really isn’t.
I agree. That’s one of the things I was trying to get at in my long paragraph above. People have this idea that a positive economy would imply that their economic constraints will go away—but even if there really is a 2% growth, that’s still only 2%, and you can easily see that 2% disappear cos you spent it on something. From the economist’s perspective, if you just spent $2000 on something nice, that’s an economic plus for you, but from the consumer’s point of view, spending that $2000 took away their financial cushion. The whole thing is confusing, and I think it reflects some interaction between averages, variations, and people’s imagination of what economic growth is supposed to imply for them.
Next came the measurement issue. Wolfers wrote:
But let’s get to the issue you raised, which is how to think about real income growth. Lemme start by being clear that my comment was about average incomes, rather than incomes at any given percentile. After all, if I’m trying to speak to all Americans, I should use an income measure that reflects all Americans. As you know, there are many different income concepts, but I wanted to: a) Use the simplest, most transparent measure; and b) broadest possible income concept; which was c) Not distorted either by changing household composition, or changing distribution. And so that led me to real GDP per capita. (Yes, you might be used to thinking of GDP as a measure of total output, but as you likely know, it’s also a measure of total income… This isn’t an equilibrium condition, but an accounting identity.)
My guess is that if you were trained as a macroeconomist, your starting point for long-run income growth trends would have been to look at GDP per capita.
And indeed, that’s where I started. There’s a stylized fact in macro—which I suspect was first popularized by Bob Lucas many moons ago—that the US economy seems to persistently grow at around 2% per year on a per capita basis, no matter what shocks hit the economy. I went back and updated the data, here, and it’s a shame that I didn’t have the space to include it. The red line shows the trend from regressing log(GDP per capita) on time, and it yields a coefficient of 0.018, which is the source for my claim that the economy tends to grow at this rate. (My numbers are comparable to—but a bit higher than—CBO’s long-term projections, which shows GDP per person growing at 1.3% from 2024-2054.) Then it’s just a bit of arithmetic to figure out that the time it takes to double is every 39 years.
You suggest that saying that it’ll double “approximately every 39 years,” is a bit too precise. I agree! I wish we had better language conventions here, and would love to hear your suggestion. For instance, I was raised to understand that saying inflation is 2-1/2 percent was a useful way of showing imprecision, relative to writing that it’s 2.5%. But we don’t have similar linguistic terms for whole numbers. I could have written “every 40 years,” but then any reader who understands compounding would have been confused as to why I wrote 40 when I meant 39. So we added the “approximately” to give a sense of uncertainty, while reporting the (admittedly rough) point estimate directly.
Let’s pan back to the bigger picture. Yes, there’s uncertainty about the growth of average real incomes. And while we could quibble about the likely growth rate of the US economy over the next several decades, I think that for nearly every reasonable scenario, I’m still going to end up thinking about my kids and being “envious of the extraordinary riches their generation will enjoy.” That’s the thing about compounding growth — it delivers really big gains! Moreover, I think this is a point that too few understand. After all, according to one recent survey, 72 percent of Americans believe that their children will be worse off financially than they are. If you think about historical rates of GDP growth, and the narrow corridor within which we’ve observed decade-to-decade growth rates, it’s almost implausible that this could happen, even if inequality were to rise!
I replied:
Regarding what you said in your column: you didn’t say “average income”; you specifically said, “The income of the average American.” And if you’re gonna be referring to “the average American,” I think it does refer to the 50% percentile or something like that.
Regarding the specifics, if the CBO’s long-term projections are 1.3% growth per year, then you get doubling after 54 years, not 39 years. So I guess you might say something like, “Current projections are for a doubling of GDP over the next 50 years or so.”
Justin responded:
1. I understand that there’s a meaning of “average” that incorporate many measures of central tendency (mean, median, mode, etc), but it’s also often used specifically to refer to a “mean.” See below, for the top google search. Given this, I’m not a fan of using the word “average” ever to refer to a “median” (unless there was some supporting verbiage to describe it more).
2. On 1.3% v. 1.8%: Even at 1.3% growth, in 39 years time, average income will be 65% higher. Point is, that’s “a lot” (as is 100% higher). Also, here’s the graph:

My summary
– If you say “average income,” I agree that this refers to the mean. If you say “average American” . . . well, that’s not clearly defined, as there is no such thing as the “average American,” but if you’re talking about income and you say “average American,” that does sound like the 50% percentile to me.
– I was giving Wolfers a hard time about the making a deterministic statement about the future, but, given the above graph, sure, I guess he has some justification!
– I think there is a slightly cleaner phrasing that would allows him to avoid overprecision and determinism: “Current projections are for a doubling of GDP over the next 50 years or so.” Or, “If trends of the past decades continue, we can expect the income of the average American to double by the end of the century.”
– Yes, I know that this is me being picky. But I’m a statistician: being picky is part of my job! You wouldn’t want it any other way.