Tex and Jimmy sent me links to this study by Gilbert Burnham, Riyadh Lafta, Shannon Doocy, and Les Roberts estimating the death rate in Iraq in recent years. (See also here and here for other versions of the report). Here’s the quick summary:
Between May and July, 2006, we did a national cross-sectional cluster sample survey of mortality in Iraq. 50 clusters were randomly selected from 16 Governorates, with every cluster consisting of 40 households. Information on deaths from these households was gathered.
Three misattributed clusters were excluded from the final analysis; data from 1849 households that contained 12 801 individuals in 47 clusters was gathered. 1474 births and 629 deaths were reported during the observation period. Pre-invasion mortality rates were 5·5 per 1000 people per year (95% CI 4·3–7·1), compared with 13·3 per 1000 people per year (10·9–16·1) in the 40 months post-invasion. We estimate that as of July, 2006, there have been 654 965 (392 979–942 636) excess Iraqi deaths as a consequence of the war, which corresponds to 2·5% of the population in the study area. Of post-invasion deaths, 601 027 (426 369–793 663) were due to violence, the most common cause being gunfire.
And here’s the key graph:
Well, they should really round these numbers to the nearest 50,000 or so, But that’s not my point here. I wanted to bring up some issues related to survey sampling (a topic that is on my mind since I’m teaching it this semester):
Cluster sampling
The sampling is done by clusters. Given this, the basic method of analysis is to summarze each cluster by the number of people and the number of deaths (for each time period) and then treat the clusters as the units of analysis. The article says they use “robust variance estimation that took into account the correlation,” but it’s really simpler than that. Basically, the clusters are the units. With that in mind, I would’ve liked to have seen the data for the 50 clusters. Strictly speaking, this isn’t necessary, but it would’ve fit in easily enough in the paper (or, certainly, in the technical report) and that would make it easy to replicate that part of the analysis.
Ratio estimation
I couldn’t find in the paper the method that was used to extrapolate to the general population, but I assume it was ratio estimation (reporting deaths from 629/12801 = 4.9%, and if you then subtract the deaths before the invasion, and multiply by 12/42 (since they’re counting 42 months after the invasion), I guess you get the 1.3% reported in the abstract). For pedagical purposes alone, I would’ve liked to see this mentioned as a ratio esitmate, (especially since this information goes into the standard error).
Inicidentally, the sampling procedure gives an estimate of the probability that each household in the sample is selected, and from this we should be able to get an estimate of the total popilation and total #births, and compare to other sources.
I also saw a concern that they would oversample large households, but I don’t see why that would happen from the study design; also, the ratio estimation should fix any such problem, at least to first order. The low nonresponse numbers are encouraging if they are to be believed.
It’s all over but the attributin’
On an unrelated note, I think it’s funny for people to refer to this as the “Lancet study” (see, for example, here for some discussion and links). Yes, the study is in a top journal, and that means it passed a referee process, but it’s the authors of the paper (Burnham et al.) who are responsible for it. Let’s just say that I woldn’t want my own research referred to as the “JASA study on toxivology” or the “Bayesian Analysis report on prior distributions” or the “AJPS study on incumbency advantage” or whatever.
I pity you, Andrew. Tim Lambert (Deltoid, on Scienceblogs.com) had a comment about the first Lancet article on Iraq death rates: "it's like flypaper for innumerates". Your opinion of the general statistical knowledge of Americans will now take a hit.
Any thoughts on the fact that the authors of both the first and second Lancet papers have refused to release the underlying data?
When authors refuse to share data with you, does that make you more or less trusting of their analysis?
Could someone point me to data on "low nonresponse numbers"? I can't find any listing of the response rate in either the Lancet article itself or the various summaries, slightly expanded versions, etc. I've seen of it.
Yeah, I've been trying to get people to credit the authors and not the journal by referring to it as "Burnham et al." throughout the blogosphere, but thus far it's been futile. Glad to see you pushing this point.
Les Roberts did release the data for the 2004 study (Tim Lambert links to it) and I haven't seen any refusal by Gilbert Burnham to release the data from this time round.
I thought the survey looked okay (I happen to disagree about the interpretation, but that's not a question of statistical methodology) and was surprised by the
Iraq Body Count's response; they draw a set of surprising conclusions from the Burnham et al. conclusions, and argue that this means the survey must have been dealing with "unrepresentative data". I've said that if they're right, they are effectively accusing somebody — presumably the Iraqi data-collectors or data-providers — of lying, but they don't say that. I'd love to see your comments on (parts of) their reasoning.
1) Les Roberts only release the data is summary form, nowhere near enough detail to only for any replication, much less check for irregularities. Burnham has also refused to release the data, at least so far.
2) The "low nonresponse numbers" come from page 4.
Those strike me as awfully low non-response rates. I commentator at Crooked Timbers claims:
3) I would be curious to hear Andrew's (and other's) opinion of this. Have you ever heard of a face-to-face household survey (on any topic, in any country) with such low non-response rates?
David Kane is overstating a legitimate point by claiming they didn't release the data in the past. They released cluster level data, which is almost entirely adequate for replicating the modelling, as Andrew suggests above. What he wants is micro-data to mount a critique of the data collection. That is legitimate and desirable, but raises more ethical problems (respondent confidentiality and researcher safety).
By "almost entirely adequate" for modelling I mean that while we can't fit exactly the same models and get exactly the same p.e.s, we can fit at least fit analogous models treating the clusters as observation pairs (one before, one after). If the results don't tally there's a problem. My experiments conformed quite closely to the published figures, even giving a slightly narrower CI.
Well, it all depends on what you mean by "almost entirely adequate." After all, they release some data in the graphs and tables in the paper itself. For some people/purposes, that's enough. They did release some cluster level data. Can you replicate the published results from that data? No. Can you get close, perhaps.
But the central claim made in 2004 was that there 8,000 — 194,000 confidence interval rejected the null hypothesis of no increase in excess deaths. Obviously, anytime your result is barely statistically significant, a small change in the model might make it go away.
I never wanted/demanded to see data that would identify any individual respondent or endanger anyone. As I wrote at CT, Roberts could have said to me (and others):
“Just give me a couple months so we can remove identifying information and you can see the data.”
or
“You need to sign this non-disclosure agreement (and have it signed by a Harvard attorney).”
or
“There is an IRB document that prevents us from sharing any data with anyone and here is a copy of that document.”
But he (and his co-authors) said none of those things. They hedged a couple times and then stopped replying to my e-mails. Others tried to get data from them and were similarly unsuccessful. Draw your own conclusions.
As an example of why looking at the raw data is important, at least one team reported outlier/unbelievable data from Falluja. If the data gathered by that team was, elsewhere, very different from data gather by other teams, I would want to see the analysis ignoring data from the suspect team. Without access to the results by survey team (with all identifying information removed) there is no way for anyone to check the integrity of the results.
Scientists, like Andrew, who want their results to be as accurate as possible, release their data to any credentialed requester. Why didn't Roberts?
The Iraq Living Conditions Survey had a response rate of 98.5% for a survey that was much longer than the Lancet one.
Tom, the Iraq Body Count people seem to be making at least two questionable assumptions – first, that their media-report-based tally of the deaths is anything but an extreme lower bound, and second, that the various governements of Iraq from 2003-present are at all interested in having a good public accounting for the deaths.
To give some background, read this post at Lenin's Tomb: http://leninology.blogspot.com/2006/10/counting-d…
He references some interesting articles such as:
http://www.usatoday.com/news/world/iraq/2003-12-1… ("Iraq's Health Ministry ordered to stop counting civilian dead from war") from 2003, during the US occupation).
Continuing with the second assumption, please recall that Sadr's militia is running the Health Ministry. I wouldn't trust their statistics; I don't know why the IBC does.
Refusal to provide the original data has become more or less standard practice in highly charged fields like environmental science and public health. That is the product of many years of experience with "hit squad" attacks by opposition-funded consultants, some of whom simply lie about the data, or, in more sophisticated examples, manipulate the data in all sorts of erroneous ways (I've seen outlier manipulation, breaking the data into smaller chunks, then noting that it was no longer "significant," and even such things as averaging ratios).
Given even a few such experiences, researchers soon learn that complaints about not making the data available are easier to deal with than outright deception. The demand to see the data is not to support the scientific process; it is to open up for public attack in the popular press.
David Kane: "As an example of why looking at the raw data is important, at least one team reported outlier/unbelievable data from Falluja. "
Please note that, when this *did* happen in the first survey, the group conducted a with/without analysis; the results most commonly referred to did not include the Fallujah cluster. You're implying a quality problem of a type for which this group has previously shown good faith and competancy.
The response rate for this survey in the Burnham paper is almost identical to the Iraq Living Conditions Survey (ILCS). From the ILCS
"The sample thus consisted of 22,000 households. Of these, 21,668 were actually interviewed." For a response rate of 98.5%.
In the Burnham paper "In 16 (0·9%) dwellings,
residents were absent; 15 (0·8%) households refused to participate." So they did not survey 0.9 + 0.8 = 1.7% for a response rate of 98.3% of households.
I think it validates the results of both surveys this group has done for the results of the second survey to agree with other estimates of preinvasion death rates. And, for the period covered by the first study, for second study to confirm those rates.
First, thanks for all the comments. In answer to David's question, yes, it pisses me off when people don't share their data. I just hate that. James attributes this to issues of scientific controversy, but I've had difficulty getting data from medical researchers too. As I said, it would be nice to at least have enough of the data to reproduce the calculations.
Regarding response rates: I just don't have any sense of what would happen in Iraq. In the U.S., you wouldn't even find people at home at a 98% rate, but I'm sure it's different over there.
Regarding other sampling issues: I don't know exactly how the grid of streets was selected, although assuming they did a ratio estimate, I wouldn't expect small variations in sampling probabilities to have much effect on the results. The definition of "household" is another matter, since I could imagine porous definitions of whether someone lived in the household. Finally, I could also imagine a problem with time trends because of recall and definitional issues. I suppose recall wouldn't be too much of an issue–you wouldn't forget if someone in the household had died–but dates could be misrecalled.
Stata code for my analysis of the first paper's cluster-level data is available here with the data inline. A negative-binomial random effects model fits well, corresponding closely to the published results.
This structure treats each cluster as supplying only two observations, so it is very conservative with respect to within-cluster non-independence. With household-level data you could probably use multi-level approaches to deal with the departure from independence and get more precise estimates.
As an exercise it serves to show that the modelling is reasonably robust, given the data.
Andrew wrote:
It must've pissed off David even more. He's just accused Burnham and Roberts of fraud.
Could you comment on the fact that they don't seem to have collected any demographic data at all on the respondants? Is that as weird as it sounds?
From today's Wall Street Journal.
655,000 War Dead?
A bogus study on Iraq casualties.
http://www.opinionjournal.com/editorial/feature.h…
Re Jane Galt's comment: As a data-greedy social scientist I am always ready to demand more variables and more cases, and that all surveys should support secondary analysis undreamt of by their designers, but even I see some context here. The last time round the most biting criticism of their paper was "the only thing this big CI shows is the necessity of going back and doing it properly with a decent sample size". Given the horrendous difficulties of collecting data in Iraq, I think they can be forgiven for throwing all their resources into answering the one key question.
If you really want to break it down by social class and educational level, not only do you want to spend more time in each household ("how did such a small team do so many interviews? smells fishy!!") you'll also need a much bigger sample.
"Could you comment on the fact that they don't seem to have collected any demographic data at all on the respondants? Is that as weird as it sounds?"
Posted by: Jane Galt
Megan, it is rather wierd. Of course, that's by standards of collecting data in places where the sight of an electric drill is not terrifying, if you get my drift.
Brendan H, the reason for collecting demographic data is not to extrapolate it to the population, but to check on the representativeness of your sample. That's how polls work; they don't just say "We called 1000 people and 647 are voting Democratic, so Democrats win by a landslide!" They check the demographics of the sample against the historic demographics of likely voters, and then adjust their numbers accordingly. My understanding is that this is bog standard for social science research, which is why I'd like Mr Gelman to comment.
The demographic data would not be as useful in this type of study for two reasons.
First, the survey is about the entire household, not the one person interviewed. So, for example, if 70% of the people interviewed were women but women only comprise 55% of the adult population, you still have no evidence of bias — perhaps women are more likely to be at home. So you would need to get demographics on the entire household.
Second, even if you collect demographics on the entire household you also need accurate data about the full population to compare this data to and assess for potential bias and/or adjust results. That type of detailed demographic data is not readily available for Iraq — the last census was nearly 10 years ago and a lot has changed (including the dramatic increase in death rates from the war and from sanctions prior to that).
Megan, you might want to read my post above yours.
Jane,
They seem to have gathered some demographic data on the deaths: Table 2 is broken down by age and sex. They also gathered data on the sex of most of the residents of the households (see p.4 of the article). Perhaps they gathered age information but didn't report it in the paper? As NRGguy says, you'd want demographics on the entire household–but this shouldn't be so hard, given that they already had a count of the number of people in the household.
From the perspective of a U.S. survey: yeah, you'd definitely want to record this info. In the surveys with which I'm familiar, the hard part is getting people to participate. Once they're hooked, you usually ask them lots and lots of questions. (The main exception I know of here is exit polling, where you want to get data on lots of voters so you don't want to spend much time on each.) In the Iraq context, if you're really getting 98% response rates, maybe the cost-benefit calculations are different: perhaps you're better off getting basic data from as many households as you can.
Regarding what is standard in research: it may be that sociologists and political scientists are more aware than public health researchers on the utility of adjusting for background variables. But I could be wrong about this.
Speed,
I don't agree with the Stephen Moore article that you linked to. On one hand, I respect his expertise–if he's been doing survey research in Iraq for nearly two years, that's nearly two years more than me! But I don't understand his focus on the number of clusters. He writes:
The total population of the country is essentially irrelevant for the sample size needed. This is a basic statistical principle (it's the sample size (n) that matters, not the population size (N)). Also, I don't quite understand his last comment: "When the question matters this much, it is worth taking the time to get the answer right." If he really thinks this, why didn't he do such a survey himself during his two years in Iraq? [This last point does not in itself invalidate Moore's criticisms of the study, but it makes me feel that there's some link in his argument that I'm missing.]
Finally, with regard to the survey methodology:
Burnham et al. provide lots of detail on the first stage of the sampling (the choice of provinces) but much less detail later on. For example, they should be able to compute the probability of selection of each household (based on the selection of province, administrative unit, street, and household). Then they can see how these probabilities vary and adjust if necessary.
Unfortunately, it is a common problem in research reports in general: to lack details on exact procedures it's surprisingly difficult for people to simply describe exactly what they did. (I'm always telling this to students when they write up their own research: Just say exactly what you did, and you'll be mostly there.) This is a little bit frustrating but unfortunately is not unique to this study.
There is an apparent contradiction in claiming both that the high response rate in the Burnham study is normal for Iraq and that much of the data must be kept secret in order to protect the lives of the people involved. If responding to a survey is so dangerous, then one would expect a lower response rate than 98%. If 98% is fairly normal for Iraq, then it can't really be perceived as being all that dangerous.
Or am I missing something?
Hi –
i think the real problem is that the people doing the "Lancet study" have produced numbers that do not fit with other studies, equally legitimate and robust, and are at least an order of magnitude different. If this study published data that was different by 1000 or so, no one would be getting their knickers in a twist.
What has also been ignored is the fact that the authors do indeed have an agenda, as the authors have spoken out clearly against the war and continue to time their publishing to influence public opinion before an election. That does not disqualify them as such – I would hope not! – but given the fact that their numbers are so vastly different than what others are reporting it raises questions.
And while I do not pretend to be an expert here – the discussions about accuracy of methodology I understand, but am not an expert – when I see multiple studies that give me x and along comes a study that gives me 10x, I usually wonder what makes that difference. Granted that some of the best scientific advances come when an outlier destroys whatever consensus may exist, I'm more than willing to accept that they may have something here.
But whenever I see an outlier like this report, I try and verify whether the analysis meets the environment: if so many Iraqis were dying in excess of normal rates, i.e. as an observable empirical fact, then given the lack of additional empirical reports (unless, of course, one can make the case for the clear repression of such reports), then I think it is legitimate to question the validity of the results when the basis for the report cannot be, so to speak, confirmed.
In other words, either the Iraqis are dying in droves and there is a conspiracy to repress this, or Iraqis are not dying in the volumes that the report suggests. Occam's razor, anyone?
[Burnham et al did collect demographic data and Roberts told Moore this.] (http://scienceblogs.com/deltoid/2006/10/les_roberts_responds_to_steven.php)
But Moore then wrote his op-ed claiming that they didn't.
I'm still a bit troubled by the response rate. I understand that this figure is not out of place for what gets reported with respect to Iraqi surveys, but it still seems bizzare to me given the war-zone circumstances and the supposed mistrust of strangers and their potentially sectarian reasons for asking you questions.
John F. Opie:
John, part of me wants to be gentle, and part of me wants to smack the entire world, or at least half the blogsphere, upside the head.
Iraq is a war zone. It's extremely dangerous, on the brink of, or fallen off the brink into, civil war. The government's been changed multiple times in 40 months, they're having the devil's own time keeping the lights on, getting oil pumped, cleaning up garbage and sewage, getting food distributed, etc..
Why do people assume it would take a conspiracy to keep these deaths from being noticed by government beancounters?
If the government beancounters could prove that they knew how many people died, within 3-5%, they might well deserve to be fired on the spot for working on such piddling tasks when people who are still alive need help.
Yes, if you could hide 600,000 deaths in the US, in a peaceful, generally safe nation, with modern technology running, and running mostly-smoothly, and a government that could probably hire some literal bean counters, to count beans for some reason or another, then yes, that would be incredibly strange.
But it's not the US we're talking about; it's Iraq.
Show me that they have damn good death certificate tracking, and then I'll wonder why they haven't been counting the death certificates.
Show me that they have good injury tracking, and I'll wonder why we haven't seen enough injuries to account for the number of deaths.
But everyone seems to be assuming that both of those systems are running smoothly, even though Iraq is on the brink of civil war. Everyone seems to think it's a safe assumption.
Why?
Why don't they remember that it's a goldurned war zone?
Five issues:
1. Next-household methodology: The study used next-household to choose households to interview, thus reducing the number of independent sample points to just 47. If I'm not mistaken, the ILCS chose households independently and so had many more sample points. (21,000?)
2. The study states, "Decisions on sampling sites were made by the field manager. The interview team were given the responsibility and authority to change to an alternate location if they perceived the level of insecurity or risk to be unacceptable."
Have the interviewers introduced bias in their manual selection of starting points?
3. The study states, "The third stage consisted of random selection of a main street within the administrative unit from a list of all main streets. A residential street was then randomly selected from a list of residential streets crossing the main street. On the residential street, houses were numbered and a start household was randomly selected. From this start household, the team proceeded to the adjacent residence until 40 households were surveyed."
This restricts start points to residential streets adjoining main streets, eliminating both main streets and residential streets not intersecting main streets. Does this introduce a bias?
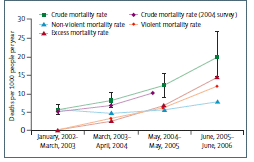
4. The study's Figure 4 claims its results confirmed by comparing "trend" of its rate to "trend" IBC and DoD death numbers.
a. Does it make sense to compare a rate to a value (deaths per year per population to deaths)? Are the authors blowing smoke?
b. Similar "trends" in two or more time-series might confirm they're measuring the same underlying statistic but do not confirm the absolute value. Are the authors blowing smoke?
5. The survey mentions gathering gender and birth dates. However, Moore's WSJ article quotes Roberts as saying no demographic data was gathered. This is contradictory unless both Roberts and Moore mean extended demographic data (education, income, social status, marital status, etc.)
http://www.thelancet.com/webfiles/images/journals…
Clarification of my point 4a above: In the study's Figure 4, The authors seem to compare "trend" of a value to "trend" of a rate representing (crudely) the first derivative of the value. They seem to be saying, "Our study is confirmed because the shape of our time-series of rate looks like the time-series of the value of which the rate is the first derivative." This is a nonsensical comparison. Worse, the value curves are near-linear (implying constant rate) while the rate curve is not constant but dramatically increasing. In the Figure 4, the Lancet survey's rate could not possibly be the time-derivative of the IBC and DoD curves shown.