For some reason, Aleks doesn’t blog anymore; he just sends me things to blog. I guess he’s decided his time is more usefully spent doing other things. I, however, continue to enjoy blogging as an alternative to real work and am a sucker for all the links Aleks sends me (except for the videos, which I never watch).
Aleks’s latest find is a program called Eureqa that implements a high-tech curve-fitting method of Michael Schmidt and Hod Lipson. (And, unlike Clarence Thomas, I mean “high-tech” in a good way.) Schmidt and Lipson describe their algorithm as “distilling free-form natural laws from experimental data,” which seems a bit over the top, but the basic idea seems sound: Instead of simply running a linear regression, the program searches through a larger space of functional forms, building models like Tinker Toys by continually adding components until the fit stops improving:
I have some thoughts on the limitations of this approach (see below), but to get things started I wanted to try out an example where I suspected this new approach would work well where more traditional statistical methods would fail.
The example I chose was a homework assignment that I included in a couple of my books. Here’s the description:
I give students the following twenty data points and ask them to fit y as a function of x1 and x2.
y x1 x2
15.68 6.87 14.09
6.18 4.4 4.35
18.1 0.43 18.09
9.07 2.73 8.65
17.97 3.25 17.68
10.04 5.3 8.53
20.74 7.08 19.5
9.76 9.73 0.72
8.23 4.51 6.88
6.52 6.4 1.26
15.69 5.72 14.62
15.51 6.28 14.18
20.61 6.14 19.68
19.58 8.26 17.75
9.72 9.41 2.44
16.36 2.88 16.1
18.3 5.74 17.37
13.26 0.45 13.25
12.1 3.74 11.51
18.15 5.03 17.44
16.8 9.67 13.74
16.55 3.62 16.15
18.79 2.54 18.62
15.68 9.15 12.74
4.08 0.69 4.02
15.45 7.97 13.24
13.44 2.49 13.21
20.86 9.81 18.41
16.05 7.56 14.16
6 0.98 5.92
3.29 0.65 3.22
9.41 9 2.74
10.76 7.83 7.39
5.98 0.26 5.97
19.23 3.64 18.89
15.67 9.28 12.63
7.04 5.66 4.18
21.63 9.71 19.32
17.84 9.36 15.19
7.49 0.88 7.43[If you want to play along, try to fit the data before going on.]
The usual solution
Students will fit a linear regression model, which in this case fits well, with an R-squared of 97%.
The true model
Actually, however, the data were simulated from the “Pythagorean” model, y^2 = x1^2 + x2^2. (We used the following code in R, using the runif command, which draws a random sample from a uniform distribution:
x1 <- runif (n=20, min=0, max=10) x2 <- runif (n=20, min=0, max=20) y <- sqrt (x1^2 + x2^2) It is striking that the linear model, y = 0.71 + 0.49 x1 + 0.86 x2, fits these data so well. What is the point of this example? At one level, it shows the power of multiple regression---even when the data come from an entirely different model, the regression can fit well. There is also a cautionary message, showing the limitations of any purely data-analytic method for finding true underlying relations. As we tell the students, if Pythagoras knew about multiple regression, he might never have discovered his famous theorem.
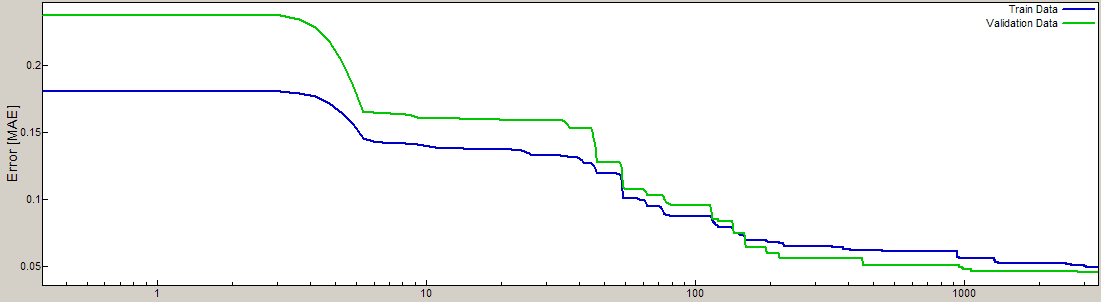
Anyway, I threw these data into the program, stood back, and watched it run. It’s all very professionally done: there’s a link to download and set up the program, then it took me about 5 minutes to figure out how to enter my data and set up the model y = f (x1, x2), then I clicked two buttons and it started to go. It has a cool dynamic display that shows how the model fit is improving in real time. After a minute of running time the program appeared to be stuck, but then it really started to move.
So far it’s been about a half hour, and the fit continues to improve (see the image above, which actually comes from this example). The program still hasn’t found the perfect fit (y = sqrt (x1^2 + x2^2)) so I assume that’s just not in the default menu. (There’s probably a way to add the square root function to the possibilities, but that would be cheating.) Still, the program’s doing something. I’m curious what the ultimate model will look like. I assume it will predict pretty well, at least for cases near to the observed data.
The program is still running after 50 minutes. At this point, I think it would be cheating for me to alter my impressions, so I’ll post what I have so far, then post again (including my more general thoughts on the applicability of such equation-fitting methods) after the program stops. If it’s still running when I get up in the morning, I’ll stop it manually and take a look.
If you see how efficient of a writer Andrew is, my time is better spend finding more interesting stuff to send him!
My guess is that Clarence Thomas preferred high-tech to the traditional low-tech method.
Andrew, care to share how long it took you to write this post?
This is a cool system, but seems to be more about dynamical systems than about statistical models for a non-time-series dataset, at least that's what the paper is about.
Symbolic regression and artificial life methods for conducting it have been around for a long time though. Perhaps since the late 1980's?
It sounds as if you're gearing up to share an interesting response. I'm curious to see if it's substantially different from those I've heard before from colleagues with a traditional statistical or physics background when they first encountered symbolic regression.
Looking forward to hearing about your sense of it all.
There are two minor things I'd like to clear up for the other readers, though: You mention "the ultimate model". I don't know what Hod and Michael have surfaced in the software package, but they're using a ParetoGP approach which returns a set of models which are mutually nondominated by complexity and error objectives. So there should always be multiple models returned from these searches, ranging from over-fit high-complexity models with many terms, down to over-simplified low-complexity models.
If there's one model in the end, something has gone wrong. Symbolic regression (of this ParetoGP flavor, at least) when applied to unknown datasets is not aiming to identify some kind of ground truth, but rather present a family of useful model frameworks and variable transforms that—taken as a whole—suggest structures for a decision-maker or designer to focus on.
The other thing I'd like to emphasize, if only for the sake of folks who have been doing this a long time and who have seemed to slip through the WIRED cracks, is that symbolic regression has a 15+ year history stretching back long before the Nature paper.
Bah! Yet another miracle tool to "solve all problems" which will fizzle out when meeting hard questions, with no hope of further insights.
And they seem eager to milk out the most funding/profit out of it as it is not Open Source, not too good for improvement prospects.
As Bill Tozier remarked it is not that symbolic regression wasn't known before, it's just marketing…
LOL. I love it when people say "Bah!" At least it's something.
With bemusement, I should let the previous commenter know that I'm preparing a manuscript right now tentatively entitled "Why do users outside the field so often underestimate GP?"
And that I—literally, no exaggeration—admonished Hod, Michael and several others of our colleagues last year at a workshop that bad marketing was our specialty's shortcoming, and that their work would perhaps pave the way for more general understanding of its importance.
In that workshop talk last year I recall drawing an analogy to that old Tom Bayes fellow, you know that preacher fellow nobody has ever heard of, and his esoteric probability calculations that were of academic interest only and of such limited scope.
So maybe marketing, a la Ramsey and Jaynes, is just the ticket.
This post made me think of an old Far Side cartoon (well, I guess they're all old, come to think of it): Einstein is standing at the blackboard, and he has written and then crossed out E=mc^4, E=mc^3, maybe a few others. The janitor (janitress?) has been straightening up and dusting his desk, and she's saying "That's better, everything is squaaaared away, that's right, squaaared away." Einstein's eyes are open really wide.
Phil: I think "janitor" covers both sexes.
Kev: Hey, don't be so mean! Maybe they developed this fancy interface in the hope of being bought out by Mathematica, Microsoft, or Google. That's not such a horrible goal, is it? As a person who's lucky enough to get paid to do whatever I want (which right now is to write blog comments, apparently), I'm the last person to criticize people for trying to make a living from their research.
Michael: It's hard to say. I was interrupted a few times when writing it.
To the others: I try to address your comments in the forthcoming blog, when I describe what happened with the model fit. (I've written it already but I don't want to post too much in one day.)
Kev: Hey, don't be so mean!
I am not mean, I am cynic.
Meanness is meant to do harm, cynicism isn't, even when it does.
Meanness allows for lying, cynicism doesn't.
It is also worth noting that Eureqa has been advertised in WIRED and though it is a "good thing" that WIRED draws our attention to interesting new trends none of what they say should be taken at face value but rather with a huuuuge grain of salt.
On the more general question of "political correctness" I deem that political correctness will bring disasters in all domains where it flourish: removing a regulating feedback (criticism in this case) is never of any good.
But I am too old to care, though not too old, I hope, to miss the times when political correctness will have backfired.
Andrew,
As I mentioned in today's entry, my main concern is how the criticism on the fitness function detailed in "Distilling Free-Form Natural Laws From Experimental Data" by Christopher Hillar and Friedrich Sommer, is (not) being addressed.
Igor.
Comment may not be suitable here, nevertheless a basic question.
from industry perspective how important is curve fitting. Isn't it always more important to think of the exercise as how x1 and x2 might affect y. I had this question, looking at the complex final equation that you have got from the tool.
I have experience of loss forecasting for retail banking products. I am just wondering, would it be advisable for us to use such equations.
Igor,
Christopher Hillar and Friedrich Sommer made a mistake in their reasoning. We privately addressed their comment back in July 2009, but for some reason they are keeping their criticism online.
In summary, an incorrect assumption about variable dependence by Hillar et al. led to a degenerate fitness calculation and their incorrect conclusion. We were able to modify the code posted online by Hillar to perform the correct calculation and yield the correct result by editing three lines of their code. Further, the alternative function proposed by Hillar is inadequate both because of its lack of generality and because of its inability to avoid trivial invariants – the two key challenges addressed in our original paper.
Our full rebuttal is now available online
http://ccsl.mae.cornell.edu/sites/default/files/h…
Thanks
Hod Lipson
uhm, I think that the linear model equation is:
y = 1.315 + 0.151*x1 + 0.807*x2, with R2=97%.
However, it is easy to understand that the model is not perfect, simply observing the qqplot of the residuals :) Not easy to understand what is the real equation..!
I really like your example :D
"An engineer thinks that his equations are an approximation to reality.
A physicist thinks that reality is an approximation to his equations.
A mathematician doesn't care."
(Anonymous)
Definitely a pysicists' view!
More…