
We’re working with polling company YouGov to track public opinion, state-by-state and district-by-district, during the 2014 campaign. We’ll be using multilevel regression and poststratification, and implementing it in Stan, and developing the necessary new parts of Stan to get this running scalably and efficiently. And we’ll be making the most detailed, up-to-date election forecasts.
What you’ll be doing if you join us as a postdoc:
– You’ll be in the midst of the most advanced polling team anywhere;
– You’ll be doing cutting-edge statistical research on MRP with deep interactions;
– You’ll be doing basic research in statistical computing, developing fast and scalable deterministic and stochastic algorithms for fitting multilevel models;
– You’ll be working inside Stan, the most advanced general computational framework for Bayesian analysis.
We’re doing research, not just implementing existing methods.
What we need:
– Stats knowledge. You should know your way around Bayesian data analysis;
– Serious computing skills. You should be a skilled C++ programmer;
– Interest in the application area. You should care about public opinion, and it should be important to you that our forecasts are good. When our estimates of opinion for some group in the population don’t make sense, you should notice and be bothered by it.
We have a great team with diverse skills (computing, statistics, political science) that plays nicely together and from whom you can learn a lot. Also lots of opportunity to collaborate with researchers in many different quantitative disciplines through Columbia’s Applied Statistics Center.
The position is a 2-year postdoc working with Andrew Gelman, funded by Yougov and situated in the Applied Statistics Center at Columbia University.
P.S. We’re ready to hire someone right away. Email your application materials to me.
P.P.S. Some relevant clickable images from Yair below. Because pretty pictures from Yair are always a good idea:

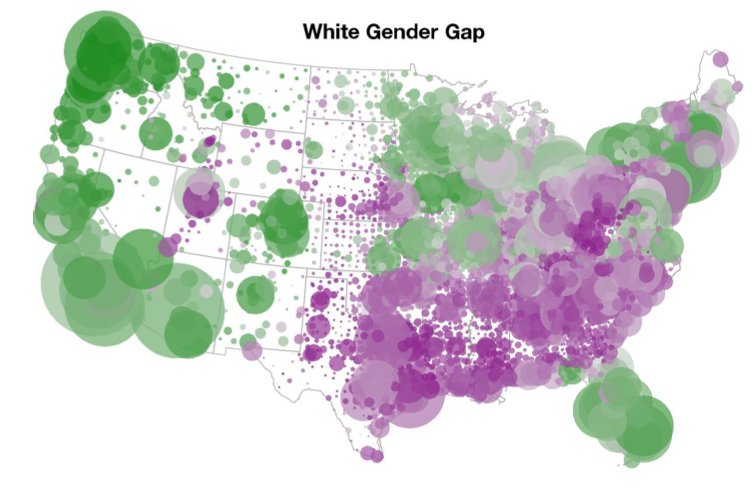
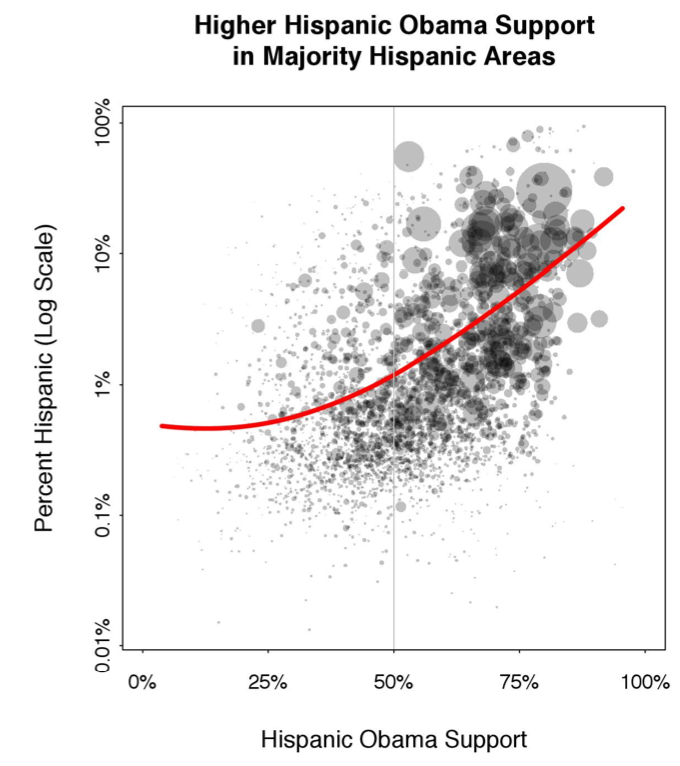

And, believe, me, this is not just generic “big data” number crunching. Lots of modeling and computation are needed to get these estimates. Cos we want to get the right answers, we’re not playing with data.
You can find out more about Stan at:
Stan home page: http://mc-stan.org
If you are a serious programmer, we can probably get you up to speed in C++. The toughest part is that we use a lot of template metaprogramming in order to push operations down to compile time for efficiency and in order to carry out automatic differentiation. You can check out our current code base on GitHub at https://github.com/stan-dev/stan
If you don’t know much about multilevel regression and poststratification (aka MRP or “Mister P”), check out Kastellec, Lax, and Phillips’s primer. Or search past posts on this blog, or just do a general search for [multilevel regression and poststratification].
I want to second Andrew’s comment about the Stan group. I took a job like this one a few years ago with Andrew and am still here because I believe in what we’re doing, I’m still learning more each day, and I really like the team. If you want to make a difference by writing software that people use, this is a great project — we have almost 600 users on our very active mailing list.
See also the (lme4/blme)-fitting MRP R package, https://github.com/malecki/mrp. Its documentation (?mrp) implements, expands, and largely supplants that of the ancient Primer.
This sounds like an incredible Post-Doc. If you could renew this for 2016 — just in time for me to graduate with my Ph.D. — that would be just great.
Did I miss the information on how/when to apply?
Hi, see P.S. above.
Why are the axes that way round in the Hispanic support plot?