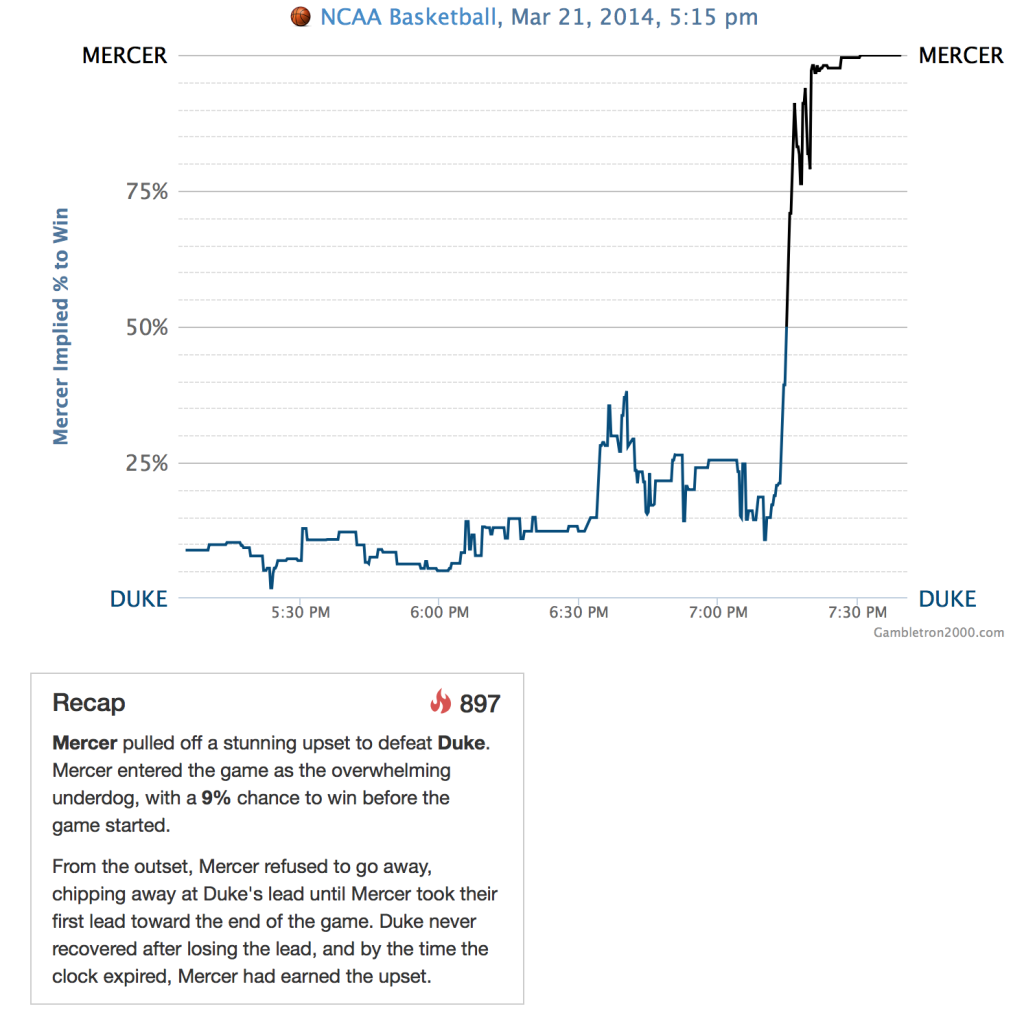
Todd Schneider writes:
Apropos of your recent blog post about modeling score differential of basketball games, I thought you might enjoy a site I built,gambletron2000.com, that gathers real-time win probabilities from betting markets for most major sports (including NBA and college basketball).My original goal was to use the variance of changes in win probabilities to quantify which games were the most exciting, but I got a bit carried away and ended up pursuing a bunch of other ideas, which you can read about in the full writeup hereThis particular passage from the anonymous someone in your post:My idea is for each timestep in a game (a second, 5 seconds, etc), use the Vegas line, the current score differential, who has the ball, and the number of possessions played already (to account for differences in pace) to create a point estimate probability of the home team winning.
reminded me of a graph I made, which shows the mean-reverting tendency of NBA and NFL win probabilities over 2 minute intervals:

Probabilities shouldn’t be mean-reverting. This means that the model isn’t taking into account all the available information. Just correcting for this known mean-reverting effect should improve the accuracy (though not very much, judging by the scale of those axes).
I think your correspondent has discovered the phenomenon known to financial econometricians as “bid-ask bounce”. He’s using the mid-prices to calculate his implied probabilities, but if the quotes are posted as the best bid and offer in a limit order book (or if the market maker adjusts them as if they were), then the mid price is going to move up and down by small amounts as new orders come in on either side.