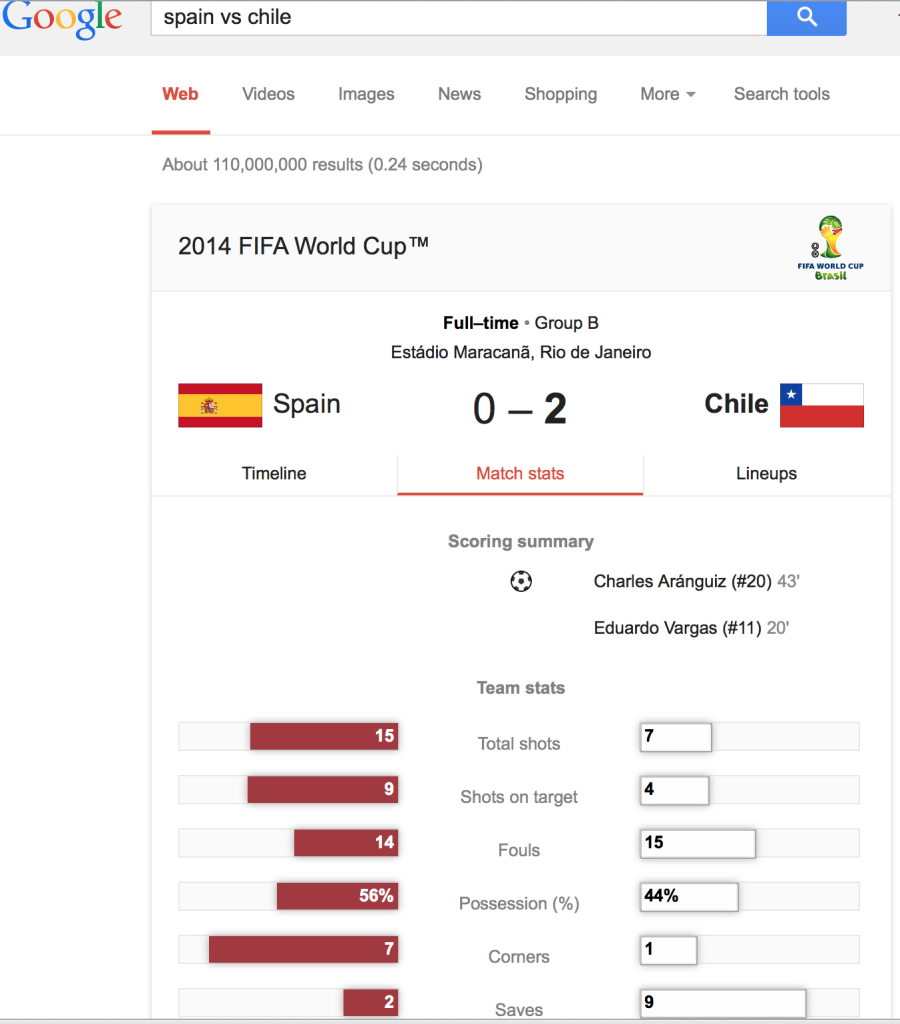
I can’t figure out what’s the deal with the bars for Corners. The bar labeled “7” is much less than 7 times the bar labeled “1.” At first I was guessing that maybe they’re not counting the numbered part in the bar width (which would be a pretty weird choice) but that wouldn’t work for the Shots on Target bars, cos if you take out the part with the numbers, the bar labeled “9” would be much wider than the bar labeled “4.” So I’m baffled.
It’s no big deal but it seems strange to me that an automatic algorithm would do something like this. If it were a hand-drawn graph I could imagine all sorts of reasons but I can’t figure out how it would end up that someone at Google would program the graph to do this.
I think that for each line, the combined width of the two bars is standardized to be the width of the total space available for ONE of the bars. (See how for each bar, if you laid the left and right hand sides end to end, they would take the space available for a bar on one side?)
Crazy system though. Would make more sense if they were all proportions.
Mind you that doesn’t quite work for the Corners…
I think it’s proportional but with a minimum floor on how short the bar can be. Perhaps for visibility.
If the value in the bar is greater than zero, its width cannot be lower than 25% (can be seen in the source code of the page). Check also Belgium – Algeria for more examples. My guess is they do it so that numbers/percentages are always comfortably within the bar (no matter what specific font/browser/settings people use).
Jirka:
OK, that’s plausible. It seems kinda wack to me. But it’s also the kind of decision that can seem to make sense when you program it, and the problems don’t become clear until it gets used as a default. So I could see how it would happen. And I support of the general strategy of implementing an algorithm and then putting it into use so its flaws will show up.
It’s actually very, very annoying to ensure text will fit inside of some variable sized box. 11 can be smaller than 8, III might be smaller than W, etc. Coding to ensure WWW will fit can give you way too much space.
Anyway they do have my sympathies, though I agree that the bars overall have strange proportions.
So instead of trying to ensure the text fits by forcing a minimum width on the bar, instead *check* if the text fits, and if it doesn’t, move the label outside the bar. That’s what I’d do.
Would a constant width font help?
The original sin is that the comparisons you actually want to make (stats for team A vs stats for team B) aren’t presented Cleveland-ily as comparisons on the same scale (i.e. as pairs of side-by-side or one-over-the-other bars). It seems unlikely that you’d actually want to compare all the statistics for one team against each other (i.e. shots vs fouls vs corners vs saves), or to compare the multivariate profile. Of course there are lots of other design criteria — horizontal labels, efficient use of space, attractiveness …
Tip from the clueless:
The underlying bar represents the whole game-time as 100% – starting with the kick-off
The algorithm “auto-counts” the mentions of certain key words during the assumed geme time window
and – here it might start to hurt for data analysts / vis specialists – adds +1 in the overlying colored bar –
where the end of the bar represents the time stamp of the last occurance as percentage of the whole….
Why do I think this is the crazy scheme underlying this graph: because it’s fully automated and while strange, its an easy way to auto-format the visuals….
* I’m not sure, if it really can be that simple, but who nows :)
Cheers,
gego
missed some a’s and k’s in the ost above