
As a project for Andrew’s Statistical Communication and Graphics graduate course at Columbia, a few of us (Michael Andreae, Yuanjun Gao, Dongying Song, and I) had the goal of giving RStan’s print and plot functions a makeover. We ended up getting a bit carried away and instead we designed a graphical user interface for interactively exploring virtually any Bayesian model fit using a Markov chain Monte Carlo algorithm.
The result is shinyStan, a package for R and an app powered by Shiny. The full version of shinyStan v1.0.0 can be downloaded as an R package from the Stan Development Team GitHub page here, and we have a demo up online here. If you’re not an R user, we’re working on a full online version of shinyStan too.
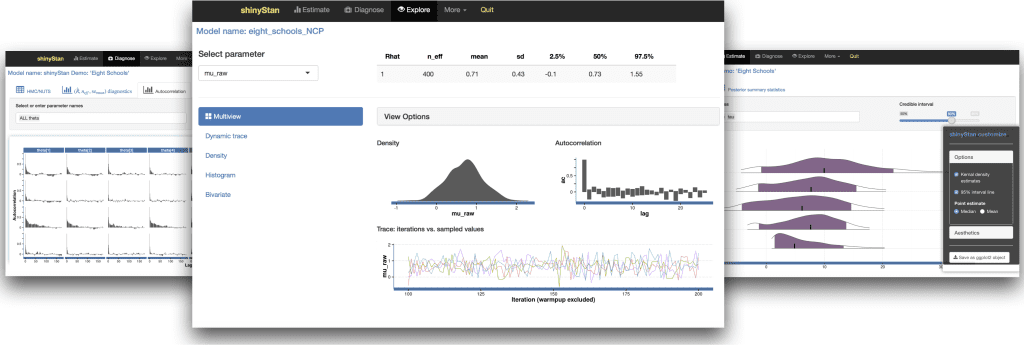
For me, there are two primary motivations behind shinyStan:
1) Interactive visual model exploration
- Immediate, informative, customizable visual and numerical summaries of model parameters and convergence diagnostics for MCMC simulations.
- Good defaults with many opportunities for customization.
2) Convenient saving and sharing
- Store the basic components of an entire project (code, posterior samples, graphs, tables, notes) in a single object.
- Export graphics into R session as ggplot2 objects for further customization and easy integration in reports or post-processing for publication.
There’s also a third thing that has me excited at the moment. That online demo I mentioned above… well, since you’ll be able to upload your own data soon enough and even add your own plots if we haven’t included something you want, imagine an interactive library of your models hosted online. I’m imagining something like this except, you know, finite, useful, and for statistical models instead of books. (Quite possibly with fewer paradoxes too.) So it won’t be anything like Borges’ library, but I couldn’t resist the chance to give him a shout-out.
Finally, for those of you who haven’t converted to Stan quite yet, shinyStan is agnostic when it comes to inputs, which is to say that you don’t need to use Stan to use shinyStan (though we like it when you do). If you’re a Jags or Bugs user, or if you write your own MCMC algorithms, as long as you have some simulations in an array, matrix, mcmc.list, etc., you can take advantage of shinyStan.
If you haven’t stopped reading yet and want a more detailed list of features, release notes are below. But why read the notes when you can try it out right now! And if you do try it out, we’d love your feedback.
How to Get It
Release Notes
shinyStan v1.0.0 ====================================================================== Interactive and customizable plots: ---------------------------------------- * Parameter estimates * Traceplots for individual or multiple parameters * Dynamic trace plots for individual parameters with dygraphs (JavaScript) charting library * Autocorrelation for individual or multiple parameters * Bivariate scatterplots * (New) Trivariate scatter plots (using three.js library) * (New) Distributions of Rhat, effective sample size / total sample size, monte carlo error / posterior sd Customizable tables (via jQuery DataTables) ---------------------------------------- * Posterior summary statistics (can now search table with regular expressions for easier filtering) * Average, max and min of sampler parameters (for NUTS and HMC algorithms) Other features: ---------------------------------------- * In addition to stanfit objects, you can also use arrays of simulations and mcmc.lists with shinyStan * Model code is viewable in the shinyStan GUI * Save notes about your model * Save plots as ggplot2 objects (i.e. not just the image but an object that can be edited with functions from the ggplot2 package) * Glossaries with definitions of terms used in the tables * Generate new quantities as a function of one or two existing parameters Coming soon to your local shinyStan: ---------------------------------------- * Graphical posterior predictive checks * shinyStan online * Deploy a shinyStan app for each of your models online to shinyapps.io (Start an online library of your models) * Add your own custom plots to a shinystan objects so you can really store everything in one object
Wow.
Wow indeed! This is amazing. Thank you for sharing!
Yup — that pretty much sums up our reaction (the Stan dev team’s). The graphics are really nice, and being able to deploy it on the web’s amazing. It’s mind-boggling that this started as a class project for a visualization class last semester; go Andrew for teaching outside the box. So it’s not been around very long; at the clip Jonah’s going, I can only imagine where it’ll be in a year.
Yuanjun’s the grad student who wrote the dense mass estimator for the existing Stan, by the way. And Michael’s an anesthesiology professor (no, that’s not a typo) who’s getting more into stats and will probably be working with us on more projects in the future.
Anyone want to take a stab at a Python version? I don’t know if IPython Notebooks would be amenable to something like this, not really being a Python user.
Cool!
What about adding an option for pacf() under autocorrelation?
Thanks Bill!
And thanks for the suggestion. We can certainly add an option for partial autocorrelations. I’ll open an issue on GitHub so it’s officially on the to-do list.
This is awesome.
Thanks Evan, really glad you like it!
Jonah:
Very interesting but there might be some less standard interactive visual model exploration that shinyStan could facilitate.
For instance, I have run RStan without data to get samples from priors and marginal priors, and also with data to get samples from posteriors and marginal posteriors. With these you could get density estimates for marginal priors and posteriors, divide posterior by prior to at how the data changed the prior probabilities (AKA likelihood or relative belief function). With these, folks could explore how Bayesian analysis is _working_. For instance with the eight schools example, you could specify one of those priors for variance that Andrew has pointed out are poor choices and folks could visually explore why. May not work for really complicated analyses.
If the details are fuzzy, the examples in a paper discussed by Xi’an should provide a clarification https://xianblog.wordpress.com/2013/11/21/hidden-dangers-of-noninformative-priors/
Well, something I’d like to see or might try doing someday.
That’s a cool idea, Keith. Thanks for the suggestion! I really appreciate it.
And thanks for the pointer to Xi’an’s post. I hadn’t read that one. Really interesting.
Is Keith’s idea a place where brushing might be useful? Would one ever want to display priors, marginal priors, posteriors, and marginal posteriors and then to brush through the distributions?
Jonah, I thought more about this last night and tried it a bit with one of my own models. I am still very impressed.
Still, I try to do most of my R work in a literate programming sense, usually using Emacs org-mode where others might use RSTudio, Rmarkdown’, and knitr. I see the advantage of the interactivity of shinyStan; it’s a polished graphical exploration tool that even has XLISP-STAT’s or ggobi’s spinning for the MCMC world (hmm: is there a role for brushing?), and it makes looking at often-desired graphs easy. Exporting ggplot2 objects rather than graphs is great, as is the ability to add and save notes.
What if you added one more feature that I think would make shinyStan work well in a literate programming world: an API? It could be simple–perhaps a “code” button you could press to see the R command(s) that would produce the graphic that’s currently displayed. Then one could copy and paste that into one’s literate program. Those commands could be simple transcripts of the commands shinyStan issued, perhaps you’d prefer a shinystan_api() function that takes arguments that describe the display, or (probably) you have a better idea.
I see precedent for this. As I recall, Rattle, the R data mining GUI, captures a transcript of a session, which you can edit down to the commands needed to insert in a script. If you use the GUI menus in gnuplot, it inserts the associated command at the command prompt rather than simply executing the menu pick.
This in no way is intended to take away from what shinyStan offers; it’s an attempt to connect the iterative, exploratory world with the reproducible research world.
Bill, thanks so much for your detailed comments! I’m very much in favor of ways to “connect the iterative, exploratory world with the reproducible research world.” (That’s a nice way to describe it too, by the way.)
The API idea is something I’ve thought a decent bit about. On one hand it would be pretty easy to allow the user to see the code responsible for generating the displayed graphic. This would be particularly simple for the graphics that don’t have too many customization options.
I’m a bit torn when it comes to doing this for the highly customizable graphics. The code for these plots is flexible enough to allow for all sorts of different choices by the user and to check various other conditions, etc, so the code that actually generates the plot is much more complicated than what would be required to generate that specific plot if you just wanted to code it directly without considering what different users might want. So the user would see all sorts of stuff in the code that didn’t end up being relevant to their plot. I hope I’m making some sense.
On the other hand, maybe showing the more elaborate code isn’t a problem at all, but actually a good thing in that the user can explicitly see how they can tweak it and customize different elements.
Along the lines of what you suggested, another thing we could do is add some of the functions we use to make the plots and tables to the exported functions in the R package. That way, in addition to the GUI, users could use shinyStan in the way people currently use the coda package if they wanted to.
Good questions, Jonah. I think of two issues that could factor into your decision.
First, in an interactive system such as shinyStan, a user might spend some time creating the desired display (more an issue with spinning and other interactive techniques, I presume) and then find it hard to recreate that through the exposed functions. For a somewhat contrived example, the 3D plot requires not only the graph setup but also the three view angles. shinyStan knows those; I don’t want to have to guess them when I’m recreating them in a literate program. Making the full code to create the display available would ensure one could program quickly what one just dragged and clicked into existence.
Second, your time is limited. If you have to develop and maintain both a GUI tool and the corresponding API, you may just be adding to your workload.
Perhaps a combination works? Add a button to expose the code, even if it’s complex. And expose key internal functions you use that might work for most cases. Does that give everyone the best of both worlds?
Yeah, I think the combination you suggest might be the best option.
On a somewhat related note, one thing I’d like to add is an option for users to save any settings they’ve changed from the defaults and then be able to load those settings next time they launch shinyStan. I had this in an early draft of shinyStan but the implementation was a bit hack-ish so I removed it. But I’m planning on reintroducing it when I have a chance to do it well. In some cases it might not be appropriate to use the same settings for different models, but it would let each user create their own set of defaults essentially. So if someone spends a lot of time customizing the plots they could click a button that would store the choices they’ve made in some object (e.g. a named list or whatever) they could then save as an .RData file. Then we could allow a ‘settings’ argument to the launch_shinystan function and populate all the inputs with the user’s settings (and defaults for whatever they haven’t specified).
This relates to the API issue in the sense that the user would have access to all these settings from outside the GUI and I’d make sure the names correspond to arguments in whatever functions we make available.
Also, I just saw that you mentioned shinyStan on your blog. Thanks for the nice words!