Commenter numeric writes:
Since you were shilling for yougov the other day you might want to talk about their big miss on Brexit (off by 6% from their eve-of-election poll—remain up 2 on their last poll and leave up by 4 as of this posting).
Fair enough: Had Yougov done well, I could use them as an example of the success of MRP, and political polling more generally, so I should take the hit when they fail. It looks like Yougov was off by about 4 percentage points (or 8 percentage points if you want to measure things by vote differential). It will be interesting to how much this difference was nonuniform across demographic groups.
The difference between survey and election outcome can be broken down into five terms:
1. Survey respondents not being a representative sample of potential voters (for whatever reason, Remain voters being more reachable or more likely to respond to the poll, compared to Leave voters);
2. Survey responses being a poor measure of voting intentions (people saying Remain or Undecided even though it was likely they’d vote to leave);
3. Shift in attitudes during the last day;
4. Unpredicted patterns of voter turnout, with more voting than expected in areas and groups that were supporting Leave, and lower-than-expected turnout among Remain supporters.
5. And, of course, sampling variability. Here’s Yougov’s rolling average estimate from a couple days before the election:
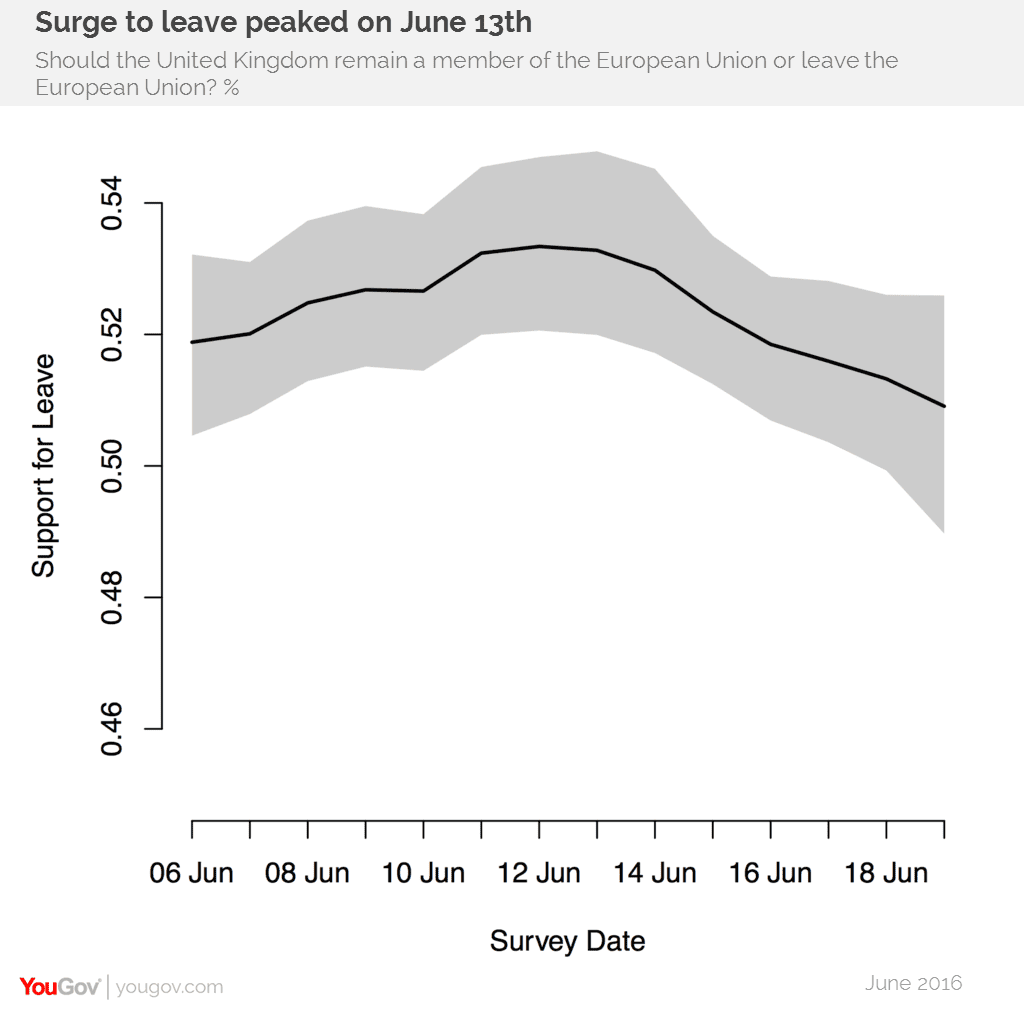
Added in response to comments: And here’s their final result, “YouGov on the day poll: Remain 52%, Leave 48%”:
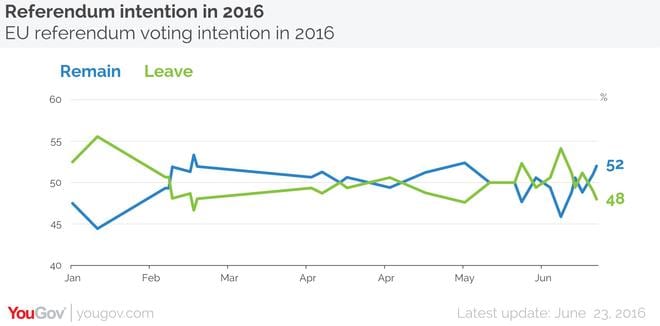
We’ll take this final 52-48 poll as Yougov’s estimate.
Each one of the above five explanations seems to be reasonable to consider as part of the story. Remember, we’re not trying to determine which of 1, 2, 3, 4, or 5 is “the” explanation; rather, we’re assuming that all five of these are happening. (Indeed, some of these could be happening but in the opposite direction; for example it’s possible that the polls oversampled Remain voters (a minus sign on item 1 above) but that this non-representativeness was more than overbalanced by a big shift in attitudes during the last day (a big plus sign on item 3).
The other thing is that item 5, sampling variability, does not stand on its own. Given the amount of polling on this issue (even within Yougov itself, as indicated by the graph above), sampling variability is an issue to the extent that items 1-4 above are problems. If there were no problems with representativeness, measurement, changes in attitudes, and turnout predictions, then the total sample size of all these polls would be enough that they’d predict the election outcome almost perfectly. But given all these other sources of uncertainty and variation, you need to worry about sampling variability too, to the extent that you’re using the latest poll to estimate the latest trends.
OK, with that as background, what does Yougov say? I went to their website and found this article posted a few hours ago:
Unexpectedly high turnout in Leave areas pushed the campaign to victory
Unfortunately YouGov was four points out in its final poll last night, but we should not be surprised that the referendum was close – we have shown it close all along. Over half our polls since the start of the year we showed Brexit in the lead or tied. . . .
As we wrote in the Times newspaper three days ago: “This campaign is not a “done deal”. The way the financial and betting markets have reacted you would think Remain had already won – yesterday’s one day rally in the pound was the biggest for seven years, and the odds of Brexit on Betfair hit 5-1. But it’s hard to justify those odds using the actual data…. The evidence suggests that we are in the final stages of a genuinely close and dynamic race.”
Just to check, what did Yougov say about this all before the election? Here’s their post from the other day, which I got by following the links from my post linked above:
Our current headline estimate of the result of the referendum is that Leave will win 51 per cent of the vote. This is close enough that we cannot be very confident of the election result: the model puts a 95% chance of a result between 48 and 53, although this only captures some forms of uncertainty.
The following three paragraphs are new, in response to comments, and replace one paragraph I had before:
OK, let’s do a quick calculation. Take their final estimate that Remain will win with 52% of the vote and give it a 95% interval with width 6 percentage points (a bit wider than the 5-percentage-point width reported above, but given that big swing, presumably we should increase the uncertainty a bit). So the interval is [49%, 55%], and if we want to call this a normal distribution with mean 52% and standard deviation 1.5%, then the probability of Remain under this model would be pnorm(52, 50, 1.5) = .91, that is, 10-1 odds in favor. So, when Yougov said the other day that “it’s hard to justify those [Betfair] odds” of 5-1, it appears that they (Yougov) would’ve been happy to give 10-1 odds.
But these odds are very sensitive to the point estimate (for example, pnorm(51.5, 50, 1.5) = .84, which gives you those 5-1 odds), to the forecast uncertainty (for example, pnorm(52, 50, 2.5) = .79), and to any smoothing you might do (for example, take a moving average of the final few days and you get something not far from 50/50).
In short, betting odds in this setting are highly sensitive to small changes in the model, and when the betting odds stay stable (as I think they were during the final period of Brexit), this suggests they contain a large element of convention or arbitrary mutual agreement.
The “out” here seems to be that last part of Yougov’s statement from the other day: “although this only captures some forms of uncertainty.”
It’s hard to know how to think about other forms of uncertainty, and I think that one way that people handle this in practice is to present 95% intervals and treat them as something more like 50% intervals.
Think about it. If you want to take the 95% interval as a Bayesian predictive interval—and Yougov does use Bayesian inference—then you’d be concluding that the odds are 40-1 that Remain would get more than 48% of the vote the outcome would fall below the lower endpoint of the interval. That’s pretty strong. But that would not be an appropriate conclusion to draw, not if you remember that this interval “only captures some forms of uncertainty.” So you can mentally adjust the interval, either by making it wider to account for these other sources of uncertainty, or by mentally lowering its probability coverage. I argue that in practice people do the latter, that they take 95% intervals as statements of uncertainty, without really believing the 95% part.
OK, fine, but if that’s right, then did the betting markets appear to be taking Yougov’s uncertainties literally with those 5-1 odds? There I’m guessing the problem was . . . other polls. Yougov was saying 51% for Leave, or maybe 52% for Remain, but other polls were showing large leads for Remain. If all the polls had looked like Yougov, and had betters been rational about accounting for nonsampling error, we might have seen something like 3-1 or 2-1 odds in favor, which would’ve been more reasonable (from a prospective sense, given Yougov’s pre-election polling results and our general knowledge that nonsampling error can be a big deal).
Houshmand Shirani-Mehr, David Rothschild, Sharad Goel, and I recently wrote a paper estimating the level of nonsampling error in U.S. election polls, and here’s what we found:
It is well known among both researchers and practitioners that election polls suffer from a variety of sampling and non-sampling errors, often collectively referred to as total survey error. However, reported margins of error typically only capture sampling variability, and in particular, generally ignore errors in defining the target population (e.g., errors due to uncertainty in who will vote). Here we empirically analyze 4,221 polls for 608 state-level presidential, senatorial, and gubernatorial elections between 1998 and 2014, all of which were conducted during the final three weeks of the campaigns. Comparing to the actual election outcomes, we find that average survey error as measured by root mean squared error (RMSE) is approximately 3.5%, corresponding to a 95% confidence interval of ±7%—twice the width of most reported intervals.
Got it? Take that Yougov pre-election 95% interval of [.48,.53] and double its width and you get something like [.46,.56] which more appropriately captures your uncertainty.
That all sounds just fine. But . . . I didn’t say this before the vote? So now the question is not, “Yougov: what went wrong?” or “UK bettors: what went wrong?” but, rather, “Gelman: what went wrong?”
That’s a question I should be able to answer! I think the most accurate response is that, like everyone else, I was focusing on the point estimate rather than the uncertainty. And, to the extent I was focusing on the uncertainty I was implicitly taking reported 95% intervals and treating them like 50% intervals. And, finally, I was probably showing too much deference to the betting line.
But I didn’t put this all together and note the inconsistency between the wide uncertainty intervals from the polls (after doing the right thing and widening the intervals to account for nonsampling errors) and the betting odds. In writing about the pre-election polls, I focused on the point estimate and didn’t focus in on the anomaly.
I should get some credit for attempting to untangle these threads now, but not as much as I’d deserve if I’d written this all two days ago. Credit to Yougov, then, for publicly questioning the 5-1 betting odds, before the voting began.
OK, now back to Yougov’s retrospective:
YouGov, like most other online pollsters, has said consistently it was a closer race than many others believed and so it has proved. While the betting markets assumed that Remain would prevail, throughout the campaign our research showed significantly larger levels of Euroscepticism than many other polling organisations. . . .
Early in the campaign, an analysis of the “true” state of public opinion claimed support for Leave was somewhere between phone and online methodologies but a little closer to phone. We disputed this at the time as we were sure our online samples were getting a much more representative sample of public opinion.
Fair enough. They’re gonna take the hit for being wrong, so they might as well grab what credit they can for being less wrong than many other pollsters. Remember, there still are people out there saying that you can’t trust online polls.
And now Yougov gets to the meat of the question:
We do not hide from the fact that YouGov’s final poll miscalculated the result by four points. This seems in a large part due to turnout – something that we have said all along would be crucial to the outcome of such a finely balanced race. Our turnout model was based, in part, on whether respondents had voted at the last general election and a turnout level above that of general elections upset the model, particularly in the North.
So they go with explanation 4 above: unexpected patterns of turnout.
They frame this as a North/South divide—which I guess is what you can learn from the data—but I’m wondering if it’s more of a simple Leave/Remain divide, with Leave voters being, on balance, more enthusiastic, hence turning out to vote at a higher-than-expected rate.
Related to this is explanation 3, changes in opinion. After all, that Yougov report also says, “three of YouGov’s final six polls of the campaign showing ‘Leave’ with the edge ranging from a 4% Remain lead to an 8% Leave lead.” And if you look at the graph reproduced above, and take a simple average, you’ll see a win for Leave. So the only way to call the polls as a lead for Remain (as Yougov did, in advance of the election) was to weight the more recent polls higher, that is to account for trends in opinion. It makes sense to account for trends, but once you do that, you have to accept the possibility of additional changes after the polling is done.
And, just to be clear: Yougov’s estimates using MRP were not bad at all. But this did not stop Yougov from reporting, as a final result, that mistaken 52-48 pro-Remain poll on the eve of the vote.
To get another perspective on what went wrong with the polling, I went to the webpage of Nikos Askitas, whose work I’d “shilled” on the sister blog the other day. Askitas had used a tally based on Google search queries—a method that he reported had worked for recent referenda in Ireland and Greece—and reported just before the election a slight lead for Remain, very close to the Yougov poll, as a matter of fact. Really kind of amazing it was so close, but I don’t know what adjustments he did to the data to get there; it might well be that he was to some extent anchoring his estimates to the polls. (He did not preregister his data-processing rules before the campaign began.)
Anyway, Askitas was another pundit to get things wrong. Here’s what he wrote in the aftermath:
Two ways ago observing the rate at which the brexit side was recovering from the murder of Jo Cox I was writing that “as of 16:15 hrs on Tuesday afternoon the leave searches caught up by half a percentage point going from 47% to 47.5%. If trend continues they will be at 53% or Thursday morning”. This was simply regressing the leave searches on each hours passed. When I then saw the first slow down I had thought that it might become 51% or 52% but recovering most of the pre-murder momentum was still possible with only one obstacle in its way: time. When the rate of recovery of the leave searches slowed down in the evening of the 22nd of June and did not move upwards in the early morning of the 23rd I had to call the presumed trend as complete: if your instrument does not pick up measurement variation then you declare the process you are observing for finished. Leave was at 48%.
What explains the difference? Maybe the trend I was seeing early on was indeed still mostly there and there was simply no time to be recorded in search? Maybe the rain damaged the remaineers as it is widely believed? Maybe the pour turnout in Wales? Maybe our tool does not have the resolution it needs for such a close call? or maybe as I was saying elsewhere “I am confident to mostly have identified the referendum relevant searches and I can see that many -but not all- of the top searches are indeed related to voting intent”.
Askitas seems to be focusing more on items 2 and 3 (measurement issues and opinion changes) and not so much on item 1 (non-representativeness of searchers) and item 4 (turnout). Again, let me emphasize the that all four items interact.
Askitas also gives his take on the political outcome:
The principle of parliamentary sovereignty implies that referendum results are not legally binding and that action occurs at the discretion of the parliament alone. Consequently a leave vote is not identical with leaving. As I was writing elsewhere voting leave is hence cheap talk and hence the rational thing to do: you can air any and all grievances with the status quo and it is your vote if you have any kind of ax to grind (and most people do). Why wouldn’t you want to do so? The politicians can still sort it out afterwards. These politicians are now going to have to change their and our ways. Pro European forces in the UK, in Brussels and other European capitals must realize that scaremongering is not enough to stir people towards Europe. We saw that more than half of the Britons prefer a highly uncertain path than the certainty of staying, a sad evaluation of the European path. Pro Europeans need to paint a positive picture of staying instead of ugly pictures of leaving and most importantly they need to sculpt it in 3D reality one European citizen at a time.
P.S. I could’ve just as well titled this, “Brexit prediction markets: What went wrong?” But it seems pretty clear that the prediction markets were following the polls.
P.P.S. Full disclosure: YouGov gives some financial support to the Stan project. (I’d put this in my previous post on Yougov but I suppose the commenter is right that I should add this disclaimer to every post that mentions the pollster. But does this mean I also need to disclose our Google support every time I mention googling something? And must I disclose my consulting for Microsoft ever time I mention Clippy? I think I’ll put together a single page listing outside support and then I can use a generic disclaimer for all my posts.
P.P.P.S. Ben Lauderdale sent me a note arguing that Yougov didn’t do so bad at all:
I worked with Doug Rivers on the MRP estimates you discussed in your post today. I want to make an important point of clarification: none of the YouGov UK polling releases *except* the one you linked to a few days back used the MRP model. All the others were 1 or 2 day samples adjusted with raking and techniques like that. The MRP estimates never showed Remain ahead, although they got down to Leave 50.1 the day before the referendum (which I tweeted). The last run I did the morning of the referendum with the final overnight data had Leave at 50.6, versus a result of Leave 51.9.
Doug and I are going to post a more detailed post-mortem on the estimates when we recover from being up all night, but fundamentally they were a success: both in terms of getting close to the right result in a very close vote, and also in predicting the local authority level results very well. Whether our communications were successful is another matter, but it was a very busy week in the run up to the referendum, and we did try very hard to be clear about the ways we could be wrong in that article!
P.P.P.P.S. And Yair writes:
I like the discussion about turnout and Leave voters being more enthusiastic. My experience has been that it’s very difficult to separate turnout from support changes. I bet if you look at nearly any stable subgroup (defined by geography and/or demographics), you’ll tend to see the two moving together.
Another piece here, which I might have missed in the discussion, is differential non-response due to the Jo Cox murder. Admittedly I didn’t follow too closely, but it seems like all the news covereage in recent days was about that. Certainly plausible that this led to some level of Leave non-response, contributing to the polling trend line dipping towards Remain in recent days. I don’t think the original post mentioned fitting the MRP with Party ID (or is it called something else in the UK?), but I’m remembering the main graphs from the swing voter Xbox paper being pretty compelling on this point.
Last — even if the topline is off, in my view there’s still a lot of value in getting the subgroups right. I know I was informally looking at the YouGov map compared to the results map last night. Maybe would be good to see a scatterplot or something. I know everyone cares about the topline more than anything, but to me (and others, I hope) the subgroups are important, both for understanding the election and for understanding where the polls were off.
It seems all 5 sources of error could be propagated through into the final interval estimate, both in a Bayesian and a Frequentist analysis. My guess is that doing the right thing and attempting to properly deal with all of the known uncertainty would routinely yield intervals too wide to be compelling to a general audience.
Anon:
That could be. But I think one of the problems is the general use of 95% intervals. If people were only asking for 50% intervals (which, under the normal distribution, are only one-third as wide as 95% intervals!), this would be less of a problem.
To put it another way, if you really are getting calibrated 95% intervals, then the truth should fall below the bottom end of the interval just one time in 40. Consider, for example, U.S. presidential elections. Being wrong one time in 40, that’s something that will happen, in expectation, once every 160 years–that is, there’s roughly a 50% chance it will happen in your lifetime! That’s more certainty than most of us know what to do with (although I suppose it can be relevant for business decisions related to possibilities like that recent drop in the value of the pound).
For the general audience, maybe better to present 50% intervals which don’t give that illusion of certainty.
I don’t understand this at all. Anon seems more to the point, there are unacknowledged sources of error other than sampling variability, they are more or less your 5 point list. If we had models that took these into account they would be more accurate, including the 95% intervals. A 95% interval that included all 5 sources of error might have been something like 45-60% with a max posterior estimate of 53% in favor of exit. But… that interval doesn’t sell in the market for news-stories, since it’s not much more narrow than the interval people have as a prior based on just their everyday interactions with their peers, so people don’t bother to be accurate and produce realistic intervals they pretend to produce extra information by ignoring real sources of uncertainty.
In some sense, it’s better to have a regular stream of unexpected upsets… that’s what sells clicks on the internet!
You can’t use these incentives to explain the betting market, but you can maybe say that the uncertainty remaining after a proper modeling procedure made it hard to make money, especially factoring in the cost of doing the polling and modeling.
Indeed, I’d rather see polls that accounted for all these sources of uncertainty and then presented both 50% AND 95% credible intervals.
Anon’s point does I think explain the field of Epidemiology where methods such as Greenland’s multiple bias (sources of error) analyses using empirically based informative priors often leads to wide posteriors – so almost no epidemiologists want to use such methods.
But here, Andrew’s 50% intervals also makes sense in that experienced producers and consumers of Epidemiology studies done as usual often refer to the _real_ probability an interval excludes no effect when there is no effect as being about 50%.
“…we’re not trying to determine which of 1, 2, 3, 4, or 5 is ‘the’ explanation; rather, we’re assuming that all four of these are happening.” — I found a 20% error for you right there!
Raghu:
D’oh! I fixed it. What happened is that I’d started with just explanations 1,2,3,4 and then added sampling error to the list.
I’m confused — yougov wrote: “Our current headline estimate of the result of the referendum is that Leave will win 51 per cent of the vote. This is close enough that we cannot be very confident of the election result: the model puts a 95% chance of a result between 48 and 53, although this only captures some forms of uncertainty.”
And then you seem to suggest that their estimate favored Remain. I see their last poll did, but isn’t this confidence interval for Leave? They were giving a 95% probability that Leave would have at least 48% of the vote? Or am I misreading your analysis?
MW:
My bad. I’d been mixing results from two different Yougov polls. I corrected this in the post.
The Economist printed this before the vote. Their model showed “leave” winning so they changed it because they didn’t believe/want to believe their results. Here is the relevant part:
“We calculate the probability of Brexit via three main steps. The first is to produce a pre-election forecast—a prior, in Bayesian parlance—for the likely vote share in every counting area. We started with a sample of 5,500 responses to recent polls on the referendum conducted by YouGov. We ran a logistic regression of people’s voting intentions against five predictors: age, education, social class, voting at the 2015 general election and geographic region. On the whole, people who are older, less educated, of a lower social class and support the Conservatives or UKIP are likelier to support Brexit, particularly if they live in England but not in London. Relying on the British Election Study (BES), we conducted a similar regression on each group’s likelihood of showing up to vote at the 2015 general election.
Next, we estimated the proportions for each of these categories for the electorate in each counting area, based on data from the BES and the most recent census. For the district of Tendring, for example, we calculate that just 16% of potential voters have completed university and 82% are over 35, while the combined vote for the Tories and UKIP in 2015 was 76%. In Edinburgh, the corresponding figures were 43% university graduates, 64% over age 35 and 17% support for UKIP plus the Conservatives. By feeding these figures into our logistic models, we calculated an expected turnout and “leave”/”remain” split for each counting area.
After repeating this exercise for every counting area and adding up the results, we concluded that this method was probably systematically under-representing “remain” supporters. It suggested that “leave” would win the referendum comfortably—precisely the opposite conclusion from the one reached by betting markets, which see “remain” as the overwhelming favourite. To bring our estimates in line with the wisdom of crowds—if you think you’re smarter than a prediction market, think again—we simply reduced the projected “leave” share by the same amount in every counting area, so that our national forecast matched the bookmakers’ expectation of 54.8% for “remain”.”
So, the prediction markets were following the polls, and the poll modeling people were following the prediction markets…. nice.
Jonathan:
Wow, good catch on the Economist’s “If you think you’re smarter than a prediction market, think again.” Talk about market fundamentalism!
To me this is the most remarkable sentence here:
” To bring our estimates in line with the wisdom of crowds—if you think you’re smarter than a prediction market, think again—we simply reduced the projected “leave” share by the same amount in every counting area, so that our national forecast matched the bookmakers’ expectation of 54.8% for “remain””
Yup, this is also how we proceed in psychology, linguistics, and the like. When the result does not match all the findings we have had so far, we we simply look at the data again to see what would have to change to get the pattern we expected.
It’s good to know that everyone, including statisticians, engage in p-value hacking, even when no p-values are involved. Maybe Andrew needs to refocus his criticism to include the people engaging in data massaging.
Shill is a strong word (though I clicked on the sponsers tab on Andrew’s website and lo and behold–there is yougov–so there should be a disclaimer when there is a post touting (or dissing) yougov). A previous discussion between Andrew and myself on polling is on:
http://statmodeling.stat.columbia.edu/2014/09/30/didnt-say/ (do a search on numeric and there is the exchange)
I don’t really expect most readers to go through this but there is a very salient point on polling which I reproduce:
As regard to the applicability of your paper to pollsters, in states where you can obtain registered voter list, a very simple way to ensure non-biasness of response by partisan/demographic categories is to sort the registered voter list by various criteria (partisan id, sex, age, ethnicity (through surname matching)) and then create clusters of, say, 50 names for 400, 800, or however many n you want to contact. This gives a rough equivalence to the actual composition of the district/state and you start with number one in the cluster and call until you get a respondent. There might be increased non-response in some of these clusters after a campaign event (I’ve never looked) but even if you have to call 4 names in a democratic cluster (say) as opposed to 3 in a republican cluster (presume this is after a republican convention), it doesn’t matter (unless you want to claim there is a vote-choice bias in the democrats that do respond as opposed to those who have “slumped”–I’ve never seen this either). Anyway, this is why non-response isn’t typically a problem in states where you can get registered voters with party identification (obviously, you have to pay to get the phone numbers matched since they typically won’t be on the registered voter file) [slump refers to a at the time unpublished working paper by Andrew and others claiming that non-response was the big driver of polling variability, a claim I challenge at length in the previous comments].
I don’t think Britain keeps such lists so this isn’t applicable here but it does show a way around Andrews issue 1–non representative sample. I will say I have used this with much smaller sample sizes (400) than the Brexit polls (congressional/state races primarily) and it’s empirical standard error is around 5%. It is, however, a useful technique which doesn’t seem to be widespread (I’ve never seen it in the academic literature though of course I haven’t done an exhaustive search).
Numeric:
OK, I added the disclaimer to this post too.
Your PPS
P.P.S. Full disclosure: YouGov gives some financial support to the Stan project. (I’d put this in my previous post on Yougov but I suppose the commenter is right that I should add this disclaimer to every post that mentions the pollster. But does this mean I also need to disclose our Google support every time I mention googling something? And must I disclose my consulting for Microsoft ever time I mention Clippy? I think I’ll put together a single page listing outside support and then I can use a generic disclaimer for all my posts.
This is specious. The reason you need to mention the Yougov support is that you are part of the academic political science power elite, as is Yougov (at least I looked at their board a few years ago when it was Polimetrix and it was essentially a bunch of political methodologists–I understand it’s somewhat different now (still selling soap, mostly) but obviously Rivers is still involved (given the comments about MRP estimates on Brexit by Lauderdale). I’ve noted before that you tend to go easier on political scientists then say social psychologists–you’ve denied it but see my comments in http://statmodeling.stat.columbia.edu/2014/09/30/didnt-say/ regarding a true howler by Rivers–your comment was that you weren’t familiar with that paper and that you’ve also upbraided the smiley face author(s). Still, you would get a desk at Google or Microsoft–maybe better–Varian did well for himself–but the point is that you’re much more connected with Yougov than Google. This is how power elites work, according to Mills.
+1
I have a lot of concerns about prediction markets. You can look at things like the trading on the pound to see the bets of people with a lot more on the line, and even then the financial markets were extremely (~85%) confident in Remain on what looked like poor evidence. I think both financial and prediction markets bought into the post-Jo Cox shift towards Remain and also felt that Leave was so big a decision that it simply wouldn’t happen.
Prediction markets are the aggregation of human predictions, and humans are bad at predictions in ways that are themselves predictable. Most notably here prediction markets seem highly vulnerable to recency bias and trendiness, moving too much too fast in response to recent news. For another example of this, look at how prediction markets have valued the probability of a Trump candidacy, then a Trump presidency. It’s swung around between implausibly low and implausibly high so much that I question what use prediction markets really have.
Can you reliably spot when the market is wrong before the resolution of uncertainty? A standard argument for market efficiency is that if this can be done, the market will be efficient after all, because you, and people like you, will profit from your superior predictive ability and drive the price closer to what you think is the better estimate.
I agree that prediction markets cannot do anything other than aggregate predictions, so if there exists no good information about an outcome, you can’t expect the markets to magically arrive at a good prediction. But prediction market errors being themselves predictable is a profit opportunity, and if people that have this ability profit from it, it improves the market. I’m skeptical that they’d share their insight with the public.
Regarding the 85% in the betting markets and the optimism in forex markets, I find it puzzling. Was that just speculation? Did some hedge funds commission private polls, which were very poor quality? I’d love to know the cause of that late surge in optimism.
>Can you reliably spot when the market is wrong before the resolution of uncertainty?
In my experience and study, the answer in general is No. There are innumerable instances of individuals “calling it” for very specific situations / periods of time. A significant percentage of the human race probably experiences this type of general perception (“They were all wrong, and I was right”) in one small context or another, at least once in a lifetime. But doing this on a consistent basis, with real money involved, is asking a lot.
It appears that people can improve their estimations of event probabilities (cf Tetlock’s Good Judgment Project). But what your question implicitly describes is the very rare individual. A recent WSJ interview with Charlie Munger (now 90 years old!) made some relevant points.
“On how he sank tens of millions of dollars into bank stocks in March 2009:
We just put the money in. It didn’t take any novel thought. It was a once-in-40-year opportunity. You have to strike the right balance between competency or knowledge on the one hand and gumption on the other. Too much competency and no gumption is no good. And if you don’t know your circle of competence, then too much gumption will get you killed. But the more you know the limits to your knowledge, the more valuable gumption is.”
Agree — Anon is correct and concise, as are you.
Pollsters are always full of convenient excuses when reality of actual balloting proves them wrong.
Total survey margin of error is never publicly reported… precisely because: “… that interval doesn’t sell in the market for news-stories.”
It’s fundamentally a business, like selling used cars. Full and honest disclosure tends to discourage consumers.
“
>let me emphasize the that all four items interact
I think above you said all four items have effects, but didn’t mention interactive effects in particular. What are the interactive effects you have in mind? How do you know whether there are interactive effects or just additive “main” effects?
http://www.economist.com/blogs/graphicdetail/2016/06/polls-versus-prediction-markets?fsrc=rss
What do you think about this?
“the probability of Remain under this model would be pnorm(50, 51, 1.25) = .21, that is, 4-1 odds in favor. So, when Yougov said the other day that “it’s hard to justify those [Betfair] odds” of 5-1, it appears that they (Yougov) would’ve been happy to give 4-1 odds, which doesn’t seem all so different”
I’m confused here – isn’t this backwards? Implied probability of Remain was ~75% leading up to vote, but per the Yougov poll it should have been 21% so it would have been *markedly* different.
SD000:
My bad. I’d been mixing results from two different Yougov polls. I corrected this in the post.
“Doug and I are going to post a more detailed post-mortem on the estimates when we recover from being up all night, but fundamentally they were a success: both in terms of getting close to the right result in a very close vote, and also in predicting the local authority level results very well.”
I had a good laugh reading this. This reminds of the psychologist trying to argue that the result was effectively significant, p<0.10, hence publish in top journal.
When the statistician gets it wrong, they resort to the same sort of back-pedalling as anyone else.
Shravan:
I disagree with you on this. Yougov’s MRP estimates really were pretty close to the actual election outcome. The estimates weren’t perfect (see items 1-5 above which will assure imperfection) but they were indeed close.
Recently more polling ends near 50 to 50. Let’s consider Austrian president election for example. I suspect that people tend to add their vote to seemingly weaker side. They are satisfied with no side. Frustrated people don’t wont one side win too much. Maybe a lot of people was thinking that after killing Jo Cox a lot of the others will vote for stay. So they were hurry to vote for exit. Just to balance results.
I believe that stupid human psychology do more, then is expected. If there will be no pre-election polls, there will be more obvious results. Based more on objective reasons.
The other thing is, that in every properly working system must be some hysteresis. Now all considers how big bad mark the EU receive from Brits. In fact Brits are more divided than EU. I think, that if the EU would be such a tragedy for UK, there could not be nearly half of votes for stay in.
There could be some hysteresis for changes. Especially for long term, fundamental change. It is not reasonable for example, if some country gets in EU with support of 75% and after 50 years of membership gets out with 51% votes in referendum.
I have to say that with current level of information it’s very hard to understand what went wrong, particularly given:
1. There’s really no big difference between (1) and (4) – i.e. it doesn’t really matter if you missed all people or people who will actually vote. No matter what, you messed your frame.
2. Also, (2) and (4) are very tied – your voting intention actually includes whether you intend to vote
3. You can never get (5) – sampling variability – right if your model is wrong. People often miss that the sampling error distribution is baked right into the model, and by messing the model badly you mess both estimate and distribution, particularly if you didn’t run some of the tests to see whether your residuals are actually random, for example.
4. (3) – shifts in attitude at the very last day – is a catch-all excuse. I don’t even want to hear it.
Frankly, this kinda sums up the problem with post-vote analysis of Brexit: so far, I hear no analysis of up to which point the polls went right. I.e. I hear no reports saying that the turnout was as predicted by our model, or that the polls were accurate in South England, but the turnout was smaller, or something to this effect. What’s more, I see exit polls that looks quite suspect to me, and given the known issues with 2012 US exit polls I’m inclined to think that polling companies got the exit polls wrong as well.
Finally, to me the outcome of UK election looks like a mixture model, i.e. you don’t have voters coming from one uniform-ish distribution, but rather have a mixture of few distributions. Based on my experience, this is where most standard continuous models start to fail, and this is one of the areas where it’s hard to debug what went wrong without seeing the data and by looking at results only.
1 The TNS polls were predicting “Leave” win all the time (and were pretty accurate, excl. “don’t knows”)
2 Pollsters who did not have serious problems with the sample randomness, with models they use to correct sample biases, and with turnout models.
Thats all about it
just USE RANDOM SAMPLES!
Its very simple. The surveys and pollsters do not understand the general pulse of the voter population. This detachment from the ground reality and focusing on data collection from a small sample results in yougov coming up with 1000+ results within a month before the ref, each one is different from others and all of them are wrong. The sampling and their feedback should at the most have 0.5 weight. The other factors – socio economic, cultural, etc. should be considered and applied to get it approximately correct. A week before the ref I had broken this down by region (including BOTs), total voting poulation, the general mood in each area, probabiltiy of voter turnout. Based on this I got it nearly right.
Here’s a simple explanation that also happens to be true:
Their poll did not observe what they said it observed.
They used their poll data to build a forecast, and then reported the forecast as the poll.
Guessing – even making a very good guess – at how undecideds will eventually decide is the function of a forecast. For the sake of statistical literacy I’d recommend separating the two in the future.
Polls are not predictions