Shravan points me to this article, Twitter Language Use Reflects Psychological Differences between Democrats and Republicans, which begins with the following self-parody of an abstract:
Previous research has shown that political leanings correlate with various psychological factors. While surveys and experiments provide a rich source of information for political psychology, data from social networks can offer more naturalistic and robust material for analysis. This research investigates psychological differences between individuals of different political orientations on a social networking platform, Twitter. Based on previous findings, we hypothesized that the language used by liberals emphasizes their perception of uniqueness, contains more swear words, more anxiety-related words and more feeling-related words than conservatives’ language. Conversely, we predicted that the language of conservatives emphasizes group membership and contains more references to achievement and religion than liberals’ language. We analysed Twitter timelines of 5,373 followers of three Twitter accounts of the American Democratic and 5,386 followers of three accounts of the Republican parties’ Congressional Organizations. The results support most of the predictions and previous findings, confirming that Twitter behaviour offers valid insights to offline behaviour.
and also this delightful figure:
The pie-chart machine must’ve been on the fritz that day.
I can’t actually complain about this article because it appeared in Plos-one. I have the horrible feeling that, with another gimmick or two, it could’ve become a featured article in PPNAS or Science or Nature.
Anyway, I replied to Shravan:
Stop me before I barf . . .
To which Shravan replied:
Let it all out on your blog.
But no, I don’t think this is worth blogging. There must be some football items that are more newsworthy.
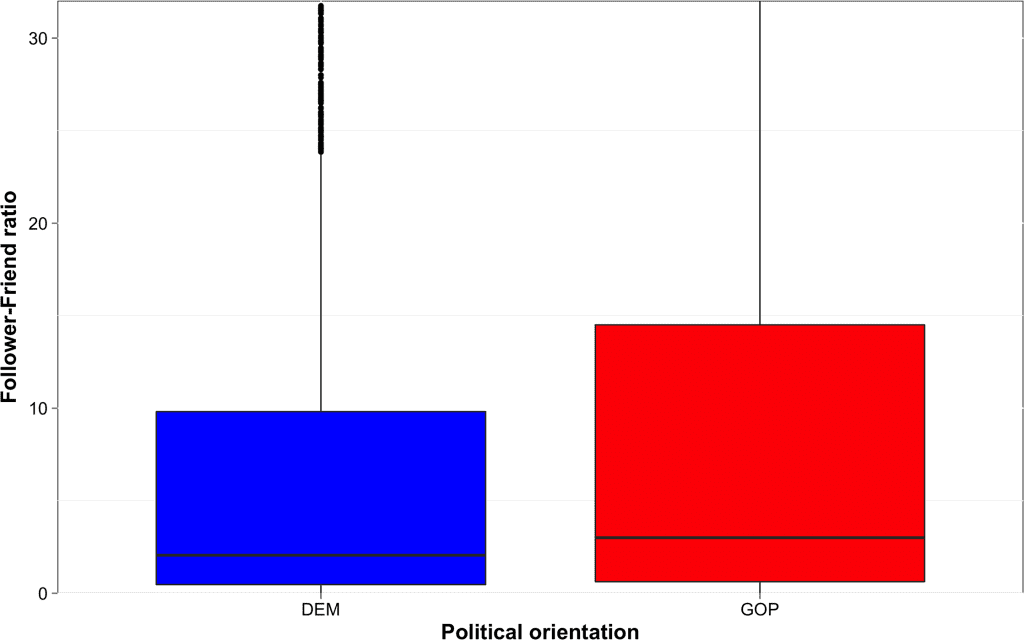
I’m confused, these boxplots are meant to give a sense of the distribution of the follower-friend ratio within each political orientation (admittedly, the boxplots are not displayed properly and the GOP boxplot, in particular, seems truncated). That said, it is not clear to me how pie charts would be more useful here.
Gail:
Oh, sure, pie charts would be horrible too.
Viopoints are the best for something like this:
https://cran.r-project.org/web/packages/viopoints/index.html
Don’t post this unless you can provide examples of what vioponts look like. The R package you link to certainly doesn’t. And what came up when I googled “vioponts” was very NSFW !! Thanks a lot!
>”what came up when *I googled* “vioponts” was very NSFW !!”
I was feeling too lazy to post a pic, but here are my search results (you can see examples in the 6th and 7th links):
http://www.viopoint.com
https://cran.r-project.org/package=viopoints
https://cran.r-project.org/web/packages/viopoints/viopoints.pdf
https://www.viovet.co.uk/p123/Terms_and_Conditions/pages.html
http://www.andrewgelman.com/2016/09/27/i-refuse-to-blog-about-this-one/
stats.stackexchange.com/questions/137965/box-and-whisker-plot-for-multimodal-distribution/137982
journals.plos.org/plosone/article?id=10.1371/journal.pone.0046424
https://madebrave.com/work/viovet/
http://www.telecomreseller.com/2014/08/29/tech-twitter-scoreboard-updated-1350-companies-with-84-tech-ceos/
https://github.com/Pakillo/Rpackages_dir
If you use google it personalizes your search results based on previous history*. If the results were NSFW it is probably because some algorithm has identified your computer as one used by people who enjoy such results: https://en.wikipedia.org/wiki/Filter_bubble
Was it? I can’t see any nsfw search results for viopoints or vioponts
are you sure you spelled it right? The raciest thing I got was “Popular Leather Pants Stories” on the third page of results (didn’t click).
I just had to find out for myself, but only got results about network penetration testing white papers. That isn’t even vaguely NSFW. An image search was even bleaker. I think it must be due to your search history, Gail, as Anoneuoid suggested.
My real purpose in visiting and bumping this old post now is because I was reflecting on the importance given to the story telling approach in psychology research. I was thinking again about Brian Wansink, who did whatever it took to get that story out of the data. Doesn’t this sound familiar, what Shravan commented here, when considering Wansink’s approach to the use of statistical inference and data analysis for scientific inquiry?
On topic: I was curious what sort of reception this article had. Surprise, surprise, not really. Major media coverage that is unheard of for most of us:
The Guardian: “Liberals swear more on Twitter than rightwingers, says study” 15 Sep 2015
Pacific Standard: “Ideologically Speaking, You Are What You Tweet” 15 Sep 2015
Los Angeles Times: “Your Twitter feed says more about your political views than you think, study says” 17 Sep 2015
Independent: “The way you tweet gives away your political views, study finds” 16 Sep 2015
NPR.org: “Science Isn’t Partisan, But Public Perception Of Science Often Is : 13.7: Cosmos And Culture : NPR”
Equally depressing is the fact despite not being widely cited in scholarly journal articles (depending on your preference, be it Google Scholar or Scopus, between 20 and 40), the viewer and download counts show no sign of abating, nearly three years after publication.
Football? We all know that it’s baseball observations that really excite Shravan: http://statmodeling.stat.columbia.edu/2016/05/09/bill-james-does-model-checking/#comment-272636
I’m only allergic to discussions of statistical theory using sports examples. I come out in a rash.
And then you make rash comments?
I wish Andy would collect his prescriptions for approaching scientific research into a single, non-technical volume (i.e. not BDA3/DAURMHM1). That way you could say: “See what happens when you violate commandment X pg. 123 (and Y, and Z, and A through R)”.
Whaddayasay?
Stat:
I have many books in the queue!
I just read this quote in the Business Insider: “I just want to help people do better research”
Certainly, ridiculing other people’s work is a wonderful way to do that.
Aby:
If someone is doing bad research, probably the worst thing you can do for them is to accept their papers into top journals and to stand by these papers even after devastating criticism. This just supports the researchers in the mistaken belief that they’re doing good work and makes it that much harder for them to do good stuff. Some people are wasting big chunks of their career chasing noise and learning nothing! It’s far better, in my view, to point out flaws in work and point people toward more useful directions. I happen to do that using humor. You might be right that an approach using less mockery would be better. I think the most important thing, though, is to be clear about problems with published work. Also, remember that my larger goal here is not to help the particular authors of papers on himmicanes, power pose, gremlins, etc. (although I’m happy to help them too) but to convey these problems in the larger research community. My audience is not just those particular researchers but also the thousands of other researchers out there. I’d like to help them do better work too, and it might be that some vivid writing (including the occasional bit of mockery) will make these lessons more memorable.
She says, as she ridicules someone for the act of ridicule.
I totally agree with Aby. There is no way in which this post will help people do better research.
Kirby:
I certainly wouldn’t claim that every post I write will help people do better research. Sometimes I just want to entertain. I’ve written thousands of research-focused posts; it can also be good to mix things up a bit. I actually wrote this particular post a few months ago. This blog is free, and you can feel free to skip over the silly posts and focus on the ones with more research content.
aby:
I have repeatedly experienced that polite facilitative criticism (you may wish to read/consider) is largely ignored in proportion to how badly it likely needs to be heeded.
+1
There’s another aspect to this too (in my view): Mockery helps break up the preciousness surrounding bad science. More than once, I have seen purveyors of bad science cloak themselves in poignancy and vulnerability (intentionally or unintentionally). If they went through a harrowing experience, touched thousands of hearts and lives, or just present themselves as sensitive, people may hesitate to criticize their work. The persona obscures the logic and methodology. Mockery of the right kind–that is, mockery for the sake of clarity–shakes this up in a good way.
If someone ridicules my work, my first reaction is to try to find out what i did wrong that led to the ridicule. Also if PhDTrump were to ridicule my work, I would not lose any sleep. If a statistician ridicules my work, I take notice. Dana Carney is an example of a person who focused on the right thing. Susan Fiske (and Amy Cuddy) are examples of people who focused on the wrong thing.
It’s a pity that article that Andrew responded to did not have a question to Fiske about what she thought about power poses now that some data and peer-reviewed critiques were in, and now that Carney explained all the possible problems in the way that experiment was conducted.
Come on guys. If someone publicly said that your work makes them barf, you wouldn’t be offended? Justify this if you must, but the post obviously amounts to bullying. And to respond to Andrew’s point – sure, we don’t have to read this. But unless you teach your children that they should look the other way when they see somebody else being bullied, I think this misses the point. Unfortunately this sort of post plays right into the hands of someone like Fiske.
Justin:
Sorry, but no. When a work is published, it’s there for all to see and to read and, if appropriate, to criticize. Sometimes people tell me they don’t like my work, maybe it even makes them barf sometimes, I dunno, whatever, that’s fine.
Have you ever seen referee reports? They can be really dismissive. But they’re in secret. I think it’s better to be out in the open. That’s one reason I prefer post-publication to pre-publication review. Pre-publication referees say all sorts of crap and it can’t be contested. Post-publication critiques can be addressed directly. See for example the above comment thread.
I agree with everything you just wrote. I guess we disagree that your post, which appears to me the equivalent of pointing and laughing at what a bunch of idiots these authors are, contains any actual criticism which the authors could use to improve their future work.
Anyway thanks for the blog – I do actually enjoy it for the most part.
Justin:
I have to say that I would not have written this post now, as the waters are muddied by the recent discussion of Fiske’s controversial article. I wrote it several months ago and it just happened to pop up recently. In the context of the usual mix of posts, I think it would be perceived as just another “oh, well!” post. Where it actually landed, I think it ended up looking like more of a strong statement than I intended.
P.S. I have no reason to think that the authors of that paper are idiots. Statistics is hard. When I speak in a foreign language, I make lots of mistakes. That doesn’t make me an idiot, it just means I’m not a very good French or Spanish speaker. People do sometimes laugh at my accent. But, sure, I don’t like it when people laugh at me.
Justin said, “Come on guys. If someone publicly said that your work makes them barf, you wouldn’t be offended?”
My sense of responsibility/ethics/adult behavior is that even if you feel offended, you still have an obligation to push past your feelings to consider the criticism on its merits. Sure, I think Andrew sometimes goes too far in his mockery (and have criticized him for this). But he usually does have valid criticisms — and is willing to acknowledge his mistakes.
See http://statmodeling.stat.columbia.edu/2016/09/21/what-has-happened-down-here-is-the-winds-have-changed/#comment-316656 and my comment on it for further elaboration on the importance of criticism.
The work that Andrew mentions here is in my approximate area (language/linguistics). I’ve been in linguistics since 1992. Over the last 16 years, I’ve been doing experimental work (roughly, cognitive psychology type work). I review funding proposals and papers that are much like the paper that Andrew mentions here.
I also started off fundamentally clueless about using statistics, but this didn’t stop me from using it. What people in linguistics (and psych) do is that they look for “stories” they can tell once they have data. Whatever the outcome is, they will come up with something to explain it. If women use shorter words than men, there’s an explanation for it, if they use longer words, there’s an explanation for that too, if there’s no difference, that can be explained as well. If they use shorter words in the morning and longer words in the evening or vice versa, we can explain that too. And so on (I made up this example, but it’s pretty typical of this kind of work).
In my field, the phrase people openly use when talking about their data is “how can we spin this”? I am not making this up, I’ve had a conversation a few weeks ago at a conference with a poster presenter who used the words, “if we want to, we can spin the result like this”. It’s part of the discourse and it is understood that there is a storytelling(“spin”) aspect to it and nobody objects to this. Editors have more than once asked us to rewrite our paper so that our post-hoc findings can be re-cast as an a priori prediction; there is no sense that there’s anything wrong with that.
People who tell this kind of storytelling dominate the field, they dominate the funding and the job scene. If as a young student you are trying to do the right thing, you will not publish in top journals because your “story” is too ambiguous and tentative. People in these fields have no hesitation in making the strongest possible claim and then going beyond that. They publish in top journals, get the jobs and the research money. The honest student can’t compete. Once you have hundreds of articles to your name, it’s a winner take all situation. Fiske, in her interview yesterday, mentioned that she has some 300+ published articles; that’s the kind of number that gives you money when you want it, and where you want it, for whatever comedic project you come up with. So it is imperative that people are shocked into stopping this.
The kind of study Andrew is talking about here is a great example of the kind of BS flooding the field. I’m fed up of having my time wasted as a researcher and reviewer, rejecting and debunking third-rate data analyses. People literally make up p-values in their papers to get published, and I mean literally literally. Not in the present case, but it’s happening in other work. If you point that out, it’s considered embarrassing.
If people can be humiliated into doing the right thing, I’m all for it. I do agree with you that it probably won’t work, just as polite reviews and private conversations with offending parties don’t seem to work. Andrew will probably not convince these researchers to question themselves and their work, but he’s raising awareness for others, and this is having an important and positive effect. My students read Andrew’s blog and they understand the problem and are trying to avoid making the same mistakes these others (and I myself) have made. I’m sure other people are also learning from these posts. So there is a net benefit to having Andrew disrupting the polite discourse of science. He has the advantage that he’s outside the field (of psych*). Many people in the field who are very influential think the same way as Andrew, but they will not do much about it, out of collegiality or whatever.
Shravan:
Yes, the concluding sentences of the abstract are particularly problematic: “The results support most of the predictions and previous findings, confirming that Twitter behaviour offers valid insights to offline behaviour.”
This follows the research plan of finding statistically significant comparisons anywhere in the data and then fitting them into a vague, all-emcompassing theory. Such a research program can go on in circles forever.
As you say, it’s standard stuff. Don’t hate the player, hate the game.
Shravan:
Your description of the problem was very succinct when you stated it as: “If women use shorter words than men, there’s an explanation for it, if they use longer words, there’s an explanation for that too, if there’s no difference, that can be explained as well.”
Unfortunately, it’s not just Psych. To various degrees this problem pervades many other branches of the hard sciences now. e.g. I worked in catalysis & people often had similar just-so stories to explain why an A+B+C combination worked well.
I think it’s an generic academia problem: There’s too much “storytelling”, too little auditing, next to zero accountability, very little of making people responsible in retrospect for claims they make, no penalties for making overly strong claims etc.
Additionally, we put too much emphasis on “structural” explanations which in turn incentivizes these just-so explanations. Journals & academics somehow prefer appealing, structural, rich models that don’t work to black-box, brute-force models that do work. And that, to me, is part of the problem.
Shravan said, “Unfortunately, it’s not just Psych. To various degrees this problem pervades many other branches of the hard sciences now.”
Yes, a prominent biologist once told me something to the effect that he considered getting a statistically significant result as giving the researcher the right to speculate about the cause.
Martha:
Yes, that’s what Kaiser Fung calls story time.
I just think we glorify the storytelling too much. And we are too credulous believing storylines.
This appeared on today’s ASA Connect Digest:
“You might be interested in Stats+Stories. You can access at http://www.statsandstories.net or find it on iTunes (search for “Stats+Stories”). This is a collaboration between the Dept. of Statistics and the Department of Media, Journalism and Film at Miami University. Statisticians and others (gerontologists, market researchers, television executives, …) have been guests. Three ASA presidents have been guests.”
The website’s subtitle is “The Statistics behind the Stories and the Stories behind the Statistics.” I think the first “stories” is intended to refer to news stories. I haven’t listened to any of the podcasts, but wonder if the site is worthwhile, counterproductive, or a mix. Does anyone here have any experience with it?
Martha:
I think stories are essential to our understanding of the world, and Basbøll and I have some thoughts on the connections between stories and statistics.
> Many people in the field who are very influential think the same way as Andrew, but they will not do much about it, out of collegiality or whatever.
I did become aware of that in clinical research – senior influential people – who comment in private to me asking me not to make this public because they don’t want the grief that might create for them. (Not a very comfortable place to be put in.)
I don’t think its collegiality but rather retribution or _pay back_. Folks in senior levels have lots of things in play – grant applications, students who need employers and collaborators, meetings to organize, journal to get submissions for, etc., ect.
Certainly explains the increase in substantive (insider?) criticisms when anonymous comments are allowed.
I think one solution (in part) is to go for more non-peer review. Then the quid pro quo problems are less. Its harder for a Psychologist to get retribution on (say) a Physician, even with the seniority differential.
Peer review is overrated. A smart outsider can contribute so much more.
Shravan provided additional insight here http://statmodeling.stat.columbia.edu/2016/09/24/a-break-in-the-thin-blue-line/#comment-317766
Thank you, Shravan, for this comment. It is the best comment I read on Andrew’s blog so far.
I think one way to prevent “story telling” – as described by you – is to make preregistration of studies and the publication of statistical analysis plans mandatory. I know that this is not easy and introduces other issues, however, for this particular problem I do see no other solution.
I fully agree. My students and I are transitioning to this. Our first pre-registration (on OSF) has happened, thanks to the initiative of one of my students.
So, your complaint Aby, is that it’s offensive for a statistician to be repulsed by fake research promoting misinformation?
Isn’t it obvious that a study of Twitter account language doesn’t predict offline behavior?
Isn’t it obvious that this follower friend ratio chart has nothing to do with the researchers’ predictions?
How does this original research prove nationwide trends, or give analysis predictive of behavior, or of anything?
It’s not just that the logic is flawed in this article.
The problem is that it’s so flawed in so many fundamental ways, as to be offensive.
I’m just saying, maybe there are times when it would be repulsive not to be repulsed.
Twitter language can predict anything. Even heart disease in other people living in the same county. http://pss.sagepub.com/content/early/2015/01/20/0956797614557867.abstract
Time to give a reminder of one of my favorite websites: http://tylervigen.com/spurious-correlations
I don’t get it. What’s so wrong with the abstract? Is it not unreasonable that political attitudes might relate to expressive language use? Is it too obvious? Not useful? Likely to lean on statistical significance (vs. practical) with such a large sample? Having to “barf” is a strong phrase.
As a layperson (not a statistician), I see some overwhelming problems with this study.
First, the “previous findings” are a big hodgepodge of studies, some of which look immediately dubious. Example: “In line with this finding, in a study where participants were asked to predict political affiliation from photographed faces (which they did with high accuracy) Democrats were perceived as more friendly and Republicans as more powerful.”
Second, the final sentence of the abstract shows bad logic. If indeed the results support “most” of the predictions and previous findings, this does not mean that Twitter behavior provides valid insight into offline behavior. It only means that Twitter behavior conforms to some predicted patterns. That is not the same thing.
Third, the method for collecting tweets is anywhere between questionable and ludicrous:
“Using a Python program connected to the Twitter API (https://dev.twitter.com/docs/api), we collected the user IDs of all followers of @GOP, @HouseGOP, @Senate_GOPs (406,687 in total, as of the 9th of June 2014) and @TheDemocrats, @HouseDemocrats, @SenateDems (456,114 in total). Next, we removed the IDs of users following both Republican and Democrat accounts, leaving 316,590 Republican and 363,348 Democrat followers after this filter. We then randomly sampled 17,000 IDs from each follower group and collected timelines and other information about user accounts and tweets. Protected accounts were filtered out, resulting in 13,740 Democrat and 14,363 Republican followers. Due to Twitter API rate limit restrictions, we were able to collect a maximum of 200 tweets for each user. Only the most recent tweets were collected and no content filtering was applied (the analysis was not limited to political tweets).”
First of all, why assume that all followers of @GOP, @HouseGOP, @Senate_GOPs are Republicans? There are likely some Democrats who are following for the information. The reverse is true as well. Second, if you’re looking specifically at followers, aren’t you limiting yourselves to datasets that will contain a great deal of inside chatter, retweeting, and repetition? In other words, if you could identify your “conservative” and “liberal” tweeters through some other means, might you not end up with quite different data?
There are many more problems, but these struck me right away (and I have no reason to plow through the whole thing).
The offending line is “Twitter behaviour offers valid insights to offline behaviour.” That’s consistent with <100% predictions being supported. Different characteristics of expressive language were related to (measured) political affiliation. Unless you're saying that following a party is not a measure of affiliation (i.e., that there's no criterion external to Twitter being used). There's error there, for sure (which would actually attenuate any effects). I'm setting aside the article content; I was just curious why it was referred to as a "self-parody."
The predictions and findings are not bidirectional. They did not establish, or come anywhere near establishing, that Twitter language, gathered randomly, can provide insights into the users’ political affiliations. They only found (with plenty of caveats) that those whom they *previously identified* as Republican or Democrat exhibited certain verbal patterns on Twitter.
So the concluding sentence of the abstract is patently false: “The results support most of the predictions and previous findings, confirming that Twitter behaviour offers valid insights to offline behaviour.” It switches the directionality of the supposed findings.
There is the issue that the abstract seems to initially frame linguistic expressions as the outcome. But in their actual logit models, affiliation was the response. The data (clearly, not “gathered randomly”) hint toward the possibility of some effect, but it’s not good evidence for a number of reasons. Open-source journals have pretty lax peer review.
Criticism is OK, even (or especially!) in the way Prof. Gelman does it. (BTW thanks for this great blog, I just found it.)
The question is, are we doing science to get some fame and appreciation for our beloved egos or to get closer to the truth? To coddle our dear selves or to learn something about the world? If you do this for knowledge, then all valid comments and pieces of criticism are helpful.
I have learned much from some really offensive reviews. Just put the offensive part aside and concentrate on the professional content. Of course, it may also depend on your ‘social status’ within your field. The big names like Susan Fiske may take an offense. The little nobodies like many of us will not, and may even feel some schadenfreude when authority figures are shaken a bit. That’s democracy in science, folks. You may be the biggest name in your field, but truth is always the biggest. Far bigger than the biggest name.
Reminds my of
CS Peirce (1879) “The theory here given rests on the supposition that the object of the investigation is
the ascertainment of truth. When the investigation is made for the purpose of attaining
personal distinction, the economics of the problem are entirely different. But that seems
to be well enough understood by those engaged in that sort of investigation.”
Most of those taking offense likely do know their purposes?
We need to do more to promote better designed experiments in psychology. One example is the following:
Middlemist, D. R., Knowles, E. S, & Matter, C. F.
Personal space invasions in the lavatory: Suggestive evidence for arousal. Journal of Personality and Social Psychology, 1976, 33, 541-546.
Apologies to anyone who may have missed the irony here. Bad design is not the only criterion for rejecting an article. Some topics are so silly or methods so unethical as to be not worth researching.
Lee:
Since we’re taking about barfing, it makes sense to go to the lavatory.