
Above is a pair of graphs from a 2015 paper by Alison Gopnik, Thomas Griffiths, and Christopher Lucas. It takes up half a page in the journal, Current Directions in Psychological Science. I think we can do better.
First, what’s wrong with the above graphs?
We could start with the details: As a reader, I have to go back and forth between the legend and the bars to keep the color scheme fresh in my mind. The negative space in the middle of each plot looks a bit like a white bar, which is not directly confusing but makes the display that much harder to read. And I had to do a double-take to interpret the infinitesimal blue bar of zero height on the left plot. Also, it’s not clear how to interpret the y-axes: 25 participants out of how many? And whassup with the y-axis on the second graph: the 15 got written as a 1, which makes me suspect that the graph was re-drawn from an original, which then leads to concern that other mistakes may have been introduced in the re-drawing process.
But that’s not the direction I want to go. There are problems with the visual display, but going and fixing them one by one would not resolve the larger problem. To get there, we need to think about goals.
A graph is a set of comparisons, and the two goals of a graph are:
1. To understand communicate the size and directions of comparisons that you were already interested in, before you made the graph; and
2. To facilitate discovery of new patterns in data that go beyond what you expected to see.
Both these goals are important. Its important to understand and communicate what we think we know, and it’s also important to put ourselves in a position where we can learn more.
The question, when making any graphs, is: what comparisons does it make it easy to see? After all, if you just wanted the damn numbers you could put them in a table.
Now let’s turn to the graph above. It makes it easy to compare the heights of two lines right next to each other—for example, I see that the dark blue lines are all higher than the light blue lines, except for the pair on the left . . . hmmmm, which are light blue and which are dark blue, again? I can’t really do much with the absolute levels of the lines because I don’t know what “25” means.
Look. I’m not trying to rag on the authors here. This sort of Excel-style bar graph is standard in so many presentations. I just think they could do better.
So, how to do better? Let’s start with the goals.
1. What are the key comparisons that the authors want to emphasize? From the caption, it seems that the most important comparisons are between children and adults. We want a graph that shows the following patterns:
(i) In the Combination scenario, children tended to chose multiple objects (the correct response, it seems) and adults tended to choose single objects (the wrong response).
(ii) In the Individual scenario, both children and adults tended to choose a single object (the correct response).
Actually, I think I’d re-order these, and first look at the Individual scenario which seems to be some sort of baseline, and then go to Combination which is displaying something new.
2. What might we want to learn from a graph of these data, beyond the comparisons listed just above? This one’s not clear so I’ll guess:
Who were those kids and adults who got the wrong answer in the Combination scenario? Did they have other problems? What about the adults who got the wrong answer in the Individual scenario, which was presumably easier? Did they also get the answer wrong in the other case? There must be some other things to learn from these data too—it’s hard to get people to participate in a psychology experiment, and once you have them there, you’ll want to give them as many tasks as you can. But from this figure alone, I’m not sure what these other questions would be.
OK, now time to make the new graph. Given that I don’t have the raw data, and I’m just trying to redo the figure above, I’ll focus on task 1: displaying the key comparisons clearly.
Hey—I just realized something! The two outcomes in this study are “Single object” and “Multiple object”—that’s all there is! And, looking carefully, I see that the numbers in each graph add up to a constant: it’s 25 children and, ummm, let me read this carefully . . . 28 adults!
This simplifies our task considerably, as now we have only 4 numbers to display instead of 8.
We can easily display four numbers with a line plot. The outcome is % who give the “Single object” response, and the two predictors are Child/Adult and Individual Principle / Combination Principle.
One of these predictors will go on the x-axis, one will correspond to the two lines, and the outcome will go on the y-axis.
In this case, which of our two predictors goes on the x-axis?
Sometimes the choice is easy: if one predictor is binary (or discrete with only a few categories) and the other is continuous, it’s simplest to put the continuous predictor as x, and use the discrete predictor to label the lines. In this case, though, both predictors are binary, so what to do?
I think we should use logical or time order, as that’s easy to follow. There are two options:
(1) Time order in age, thus Children, then Adults; or
(2) Logical order in the experiment, thus Individual Principle, then Combination Principle, as Individual is in a sense the control case and Combination is the new condition.
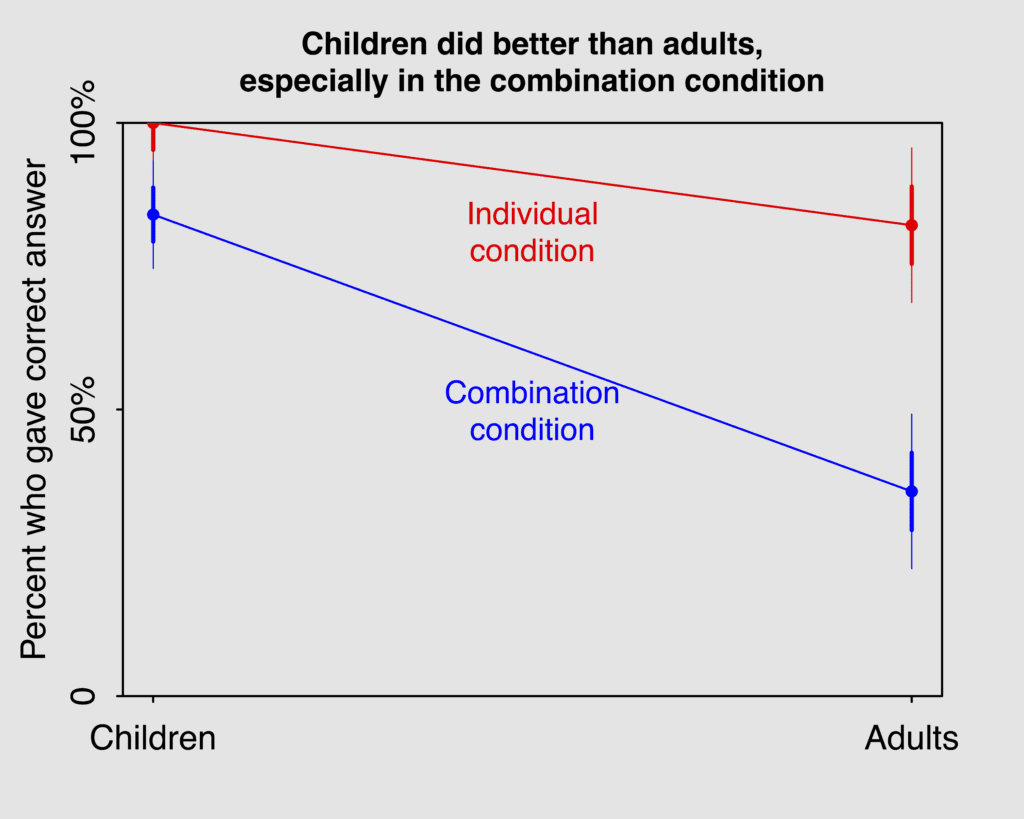
I tried it both ways and I think option 2 was clearer. So I’ll show you this graph and the corresponding R code. Then I’ll show you option 1 so you can compare.
Here’s the graph:

I think this is better than the bar graphs from the original article, for two reasons. First, we can see everything in one place: Like the title sez, “Children did better than adults,\nespecially in the combination condition.” Second, we can directly make both sorts of comparisons: we can compare children to adults, and we can also make the secondary comparison of seeing that both groups performed worse under the combination condition than the individual condition.
Here’s the data file I made, gopnik.txt:
Adult Combination N_single N_multiple 0 0 25 0 0 1 4 21 1 0 23 5 1 1 18 10
And here’s the R code:
setwd("~/AndrewFiles/research/graphics")
gopnik <- read.table("gopnik.txt", header=TRUE)
N <- gopnik$N_single + gopnik$N_multiple
p_multiple <- gopnik$N_multiple / N
p_correct <- ifelse(gopnik$Combination==0, 1 - p_multiple, p_multiple)
colors <- c("red", "blue")
combination_labels <- c("Individual\ncondition", "Combination\ncondition")
adult_labels <- c("Children", "Adults")
pdf("gopnik_2.pdf", height=4, width=5)
par(mar=c(3,3,3,2), mgp=c(1.7, .5, 0), tck=-.01, bg="gray90")
plot(c(0,1), c(0,1), yaxs="i", xlab="", ylab="Percent who gave correct answer", xaxt="n", yaxt="n", type="n", main="Children did better than adults,\nespecially in the combination condition", cex.main=.9)
axis(1, c(0, 1), combination_labels, mgp=c(1.5,1.5,0))
axis(2, c(0,.5,1), c("0", "50%", "100%"))
for (i in 1:2){
ok <- gopnik$Adult==(i-1)
x <- gopnik$Combination[ok]
y <- p_correct[ok]
se <- sqrt((N*p_correct + 2)*(N[ok]*(1-p_correct) + 2)/(N[ok] + 4)^3)
lines(x, y, col=colors[i])
points(x, y, col=colors[i], pch=20)
for (j in 1:2){
lines(rep(x[j], 2), y[j] + se[j]*c(-1,1), lwd=2, col=colors[i])
lines(rep(x[j], 2), y[j] + se[j]*c(-2,2), lwd=.5, col=colors[i])
}
text(mean(x), mean(y) - .05, adult_labels[i], col=colors[i], cex=.9)
}
dev.off()
Yeah, yeah, I know the code is ugly. I'm pretty sure it could be done much more easily in ggplot2.
Also, just for fun I threw in +/- 1 and 2 standard error bars, using the Agresti-Coull formula based on (y+2)/(n+4) for binomial standard errors. Cos why not. The one thing this graph doesn't show is whether the adults who got it wrong on the individual condition were more likely to get it wrong in the combination condition, but that information wasn't in the original graph either.
On the whole, I'm satisfied that the replacement graph contains all the information in less space and is much clearer than the original.
Again, this is not a slam on the authors of the paper. They're not working within a tradition in which graphical display is important. I'm going through this example in order to provide a template for future researchers when summarizing their data.
And, just for comparison, here's the display going the other way:
(This looks so much like the earlier plot that it seems at first that we did something wrong. But, no, it just happened that way because we're only plotting four numbers, and it just happened that the two numbers whose positions changed had very similar values of 0.84 and 0.82.)
And here's the R code for this second graph:
pdf("gopnik_1.pdf", height=4, width=5)
par(mar=c(3,3,3,2), mgp=c(1.7, .5, 0), tck=-.01, bg="gray90")
plot(c(0,1), c(0,1), yaxs="i", xlab="", ylab="Percent who gave correct answer", xaxt="n", yaxt="n", type="n", main="Children did better than adults,\nespecially in the combination condition", cex.main=.9)
axis(1, c(0, 1), adult_labels)
axis(2, c(0,.5,1), c("0", "50%", "100%"))
for (i in 1:2){
ok <- gopnik$Combination==(i-1)
x <- gopnik$Adult[ok]
y <- p_correct[ok]
se <- sqrt((N*p_correct + 2)*(N[ok]*(1-p_correct) + 2)/(N[ok] + 4)^3)
lines(x, y, col=colors[i])
points(x, y, col=colors[i], pch=20)
for (j in 1:2){
lines(rep(x[j], 2), y[j] + se[j]*c(-1,1), lwd=2, col=colors[i])
lines(rep(x[j], 2), y[j] + se[j]*c(-2,2), lwd=.5, col=colors[i])
}
text(mean(x), mean(y) - .1, combination_labels[i], col=colors[i], cex=.9)
}
dev.off()
Regarding the 15 mistakenly written as “1”. Sometimes I will redo all the numbers in a graph with Inkscape to get the font consistent with the manuscript (in the past I haven’t had much luck getting matplotlib to use different fonts, but maybe this has changed with newer releases).
I don’t know about your new graphs. They’re a step in the right direction, but there’s a lot of wasted space in the middle, and the lines imply a linear change in the success rate with age, which is something we can’t infer from this dichotomous data. I’d prefer transparent violin plots with a big chunk removed from the middle of the horizontal axis.
I agree 100% with statsgirl about using a line to join up discrete categories.
Statsgirl, Alasdair:
Regarding the lineplots: This question comes up from time to time. The short answer is that it’s a tradeoff. On one hand, when connecting “Individual condition” and “Combination condition” with a line, we’re inappropriately implying a continuous scale between the two conditions. On the other hand, the lineplot allows direct visual comparisons in both directions (within each line and between the two lines) in a way that would be difficult if the points were not connected. One compromise could be to make the dots bigger and the lines dashed rather than solid.
I think put alpha=0.25 for the lines and make the dots 3x as big… I hate dashes, that’s old school stuff from when everything was printed in black ink on white pages, and halftones cost money.
Andrew! Take a weekend to add ggplot2 and the rest of the tidyverse to your toolbelt; your future self will thank you!
On that point – I found this a vastly improved introduction to ggplot than I recall from getting in the past – http://r4ds.had.co.nz/data-visualisation.html#first-steps
Under an hour to be up and running with a simple conceptual framework to revisit when you forget the details.
figures… in base…?!
I like your redesign but effectiveness could depend on audience. Conventions can have a strong effect on how people interpret graphs, and people have a tendency to associate lines with change over time. Barbara Tverksy did a set of studies on this once, found that bar / line associations can have a stronger effect than the data being shown https://link.springer.com/content/pdf/10.3758/BF03201236.pdf
Very good point that effectiveness will depend on the audience. I’m not sure I understand the claim associated with the link, though. Is it that the cognitive load of interpreting a line as a comparison will make the graph harder to understand for certain audiences, or that lots of people (tbh, including me at first) just won’t read or remember the labels and will read it as a time trend?
One problem is that whatever one does, a reviewer wants the opposite. I do this to my students too. I ask them to do Y instead of X, and when they come back to me with Y, I ask them why they didn’t do X.
Long time listener, first time caller.
I’ve struggled a lot with how to best illustrate these paired comparisons. In the end, I came up with the following: https://twitter.com/CT_Bergstrom/status/886962357187915776
I think this works pretty well at showing the relations and is a bit more attractive.
For about the past year, I’ve been using catseye plots (like the right plot here https://i.stack.imgur.com/lgtuD.gif) rather than simply showing points and confidence intervals — I really like the way they illustrate the normal distribution of the means, and I usually mark the mean with a line or point, and shade +/- SE, and almost always overlay the catseye plots on a greyed scatterplot. The investigators I work with have been appreciative, and once past the initial reaction people seem to understand and interpret them well — though I did have one investigator confuse them with box plots. I have not made a bar plot in over a year, and nobody has complained, and I’d like to think that these plots are helping people to become comfortable with the variability in the data.
And yes, I do sometimes need transform the data to an approximation of normality before plotting and analyzing. I still plot simple confidence intervals where reporting the results of logistic or Poisson regressions.
As I recall, I learned of these on this blog. I understand they’re becoming more common in the literature lately.
I think there are actually two comparisons suggested by the author’s text. The primary is the one you identified: children do better than adults on the task. The secondary comparison is that adults have a clear preference for single objects.
Here is my take on the data:
http://imgur.com/8N3xTAZ
And the code (python):
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
plt.style.use('ggplot')
data = {'Adult': [0, 0, 1, 1],
'Combination': [0, 1, 0, 1],
'N_single': [25, 4, 23, 18],
'N_multiple': [0, 21, 5, 10]}
df = pd.DataFrame(data)
df['Group'] = df.apply(lambda d: 'Adults' if d['Adult'] else 'Children', axis=1)
df['Condition'] = df.apply(lambda d: 'Combination' if d['Combination'] else 'Individual', axis=1)
df['P Single'] = df.apply(lambda d: d['N_single'] / (d['N_single'] + d['N_multiple']), axis=1)
df['P Correct'] = df.apply(lambda d: 1.0 - d['P Single'] if d['Combination'] else d['P Single'], axis=1)
figsize = (plt.rcParams['figure.figsize'][0] * 2, plt.rcParams['figure.figsize'][1])
fig, axs = plt.subplots(1, 2, figsize=figsize)
ax = plt.subplot(1, 2, 1)
for name, gdf in df.sort_values('Group', ascending=False).groupby('Group', sort=False):
ax.plot(gdf['Combination'], gdf['P Correct'] * 100, label=name)
ax.set_ylim([0, 110])
ax.set_ylabel("% correct")
ax.set_xticks([0, 1])
ax.set_xticklabels(['Individual', 'Combination'])
ax.set_xlabel("Condition")
ax.set_title("Task Performance")
ax.legend()
ax = plt.subplot(1, 2, 2)
for name, gdf in df.sort_values('Group', ascending=False).groupby('Group', sort=False):
ax.plot(gdf['Combination'], gdf['P Single'] * 100, label=name)
ax.set_ylim([0, 110])
ax.set_ylabel("% single")
ax.set_xticks([0, 1])
ax.set_xticklabels(['Individual', 'Combination'])
ax.set_xlabel("Condition")
ax.set_title("Preference for Single")
ax.legend()
For the line plot with “conditions” on the x-axis, it could be assumed that the scale is ordinal implying that number of objects are correlated with percent who gave correct answer. I think it is a natural assumption to assume continuity when you are presented with a straight line. I think this graph makes more sense when you would have more discrete categories.