But I got some ground rules I’ve found to be sound rules and you’re not the one I’m exempting. Nonetheless, I confess it’s tempting. – Jenny Toomey sings Franklin Bruno
(The maths has died. There’s an edited version here, which is probably slightly better)
It turns out that I did something a little controversial in last week’s post. As these things always go, it wasn’t the thing I was expecting to get push back from, but rather what I thought was a fairly innocuous scaling of the prior. One commenter (and a few other people on other communication channels) pointed out that the dependence of the prior on the design didn’t seem kosher. Of course, we (Andrew, Mike and I) wrote a paper that was sort of about this a few months ago, but it’s one of those really interesting topics that we can probably all deal with thinking more about.
So in this post, I’m going to go into a couple of situations where it makes sense to scale the prior based on fixed information about the experiment. (The emerging theme for these posts is “things I think are interesting and useful but are probably not publishable” interspersed with “weird digressions into musical theatre / the personal mythology of Patti LuPone”.)
If you haven’t clicked yet, this particular post is going to be drier than Eve Arden in Mildred Pierce. If you’d rather be entertained, I’d recommend Tempting: Jenny Toomey sings the songs of Franklin Bruno. (Franklin Bruno is today’s stand in for Patti, because I’m still sad that War Paint closed. I only got to see it twice.)
(Toomey was one of the most exciting American indie musicians in the 90s both through her bands [Tsunami was the notable one, but there were others] and her work with Simple Machines, the label she co-founded. These days she’s working in musician advocacy and hasn’t released an album since the early 2000s. Bruno’s current band is called The Human Hearts. He has had a long solo career and was also in an excellent powerpop band called Nothing Painted Blue, who had an album called The Monte Carlo Method. And, now that I live in Toronto, I should say that that album has a fabulous cover of Mark Szabo’s I Should Be With You. To be honest, the only reason I work with Andrew and the Stan crew is that I figure if I’m in New York often enough I’ll eventually coincide with a Human Hearts concert.)
Sparsity
Why won’t you cheat with me? You and I both know you’ve done it before. – Jenny Toomey sings Franklin Bruno
The first object of our affliction are priors that promote sparsity in high-dimensional models. There has been a lot of work on this topic, but the cheaters guide is basically this:
While spike-and-slab models can exactly represent sparsity and have excellent theoretical properties, they are basically useless from a computational point of view. So we use scale-mixture of normal priors (also known as local-global priors) to achieve approximate sparsity, and then use some sort of decision rule to take our approximately sparse signal and make it exactly sparse.
What is a scale-mixture of normals? Well it has this general form
$latex \beta_j \sim N(0, \tau^2 \psi^2_j)$
where $latex \tau$ is a global standard deviation parameter, controlling how large the $latex \beta_j$ parameters are in general, while the local standard deviation parameters $latex \psi_j$ control how big the parameter is allowed to be locally. The priors for $latex \tau$ and the $latex \psi_j$ are typically set to be independent. A lot of theoretical work just treats $latex \tau$ as fixed (or as otherwise less important than the local parameters), but this is wrong.
Interpretation note: This is a crappy parameterisation. A better one would constrain the $latex \psi_j$ to lie on a simplex. This would then give us the interpretation that $latex \tau$ is the overall standard deviation if the covariates are properly scaled to be $latex \mathcal{O}(1)$ and the local parameters control how the individual parameters contribute to this variability. The standard parameterisation leads to some confounding between the scales of the local and global parameters, which can lead to both an interpretational and computational problems. Interesting Bhattacharya et al. showed that in some specific cases you can go from a model where the local parameters are constrained to the simplex to the unconstrained case (although they parameterised with the variance rather than the standard deviation).
Pedant’s corner: Andrew likes define mathematical statisticians as those who use x for their data rather than y. I prefer to characterise them by those who think it’s a good idea to put a prior on variance (an unelicitable quantity) rather than standard deviation (which is easy to have opinions about). Please people just stop doing this. You’re not helping yourselves!
Actually, maybe that last point isn’t for Pedant’s Corner after all. Because if you parameterise by standard deviation it’s pretty easy to work out what the marginal prior on $latex \beta_j$ (with $latex \tau$ fixed) is. This is quite useful because, with the notable exception of the “Bayesian” “Lasso” which-does-not-work-but-will-never-die-because-it-was-inexplicably-published-in-the leading-stats-journal-by-prominent-statisticians-and-has-the-word-Lasso-in-the-title-even-though-a-back-of-the-envelope-calculation-or-I-don’t-know-a-fairly-straightforward-simulation-by-the-reviewers-should-have-nixed-it (to use its married name), we can’t compute the marginal prior for most scale-mixtures of normals. The following result, which was killed by reviewers at some point during the PC prior papers long review process, but lives forever on the V1 paper on arXiv tells you everything you need to know. It’s a picture because frankly I’ve had a glass of wine and I’m not bloody typing it all again.
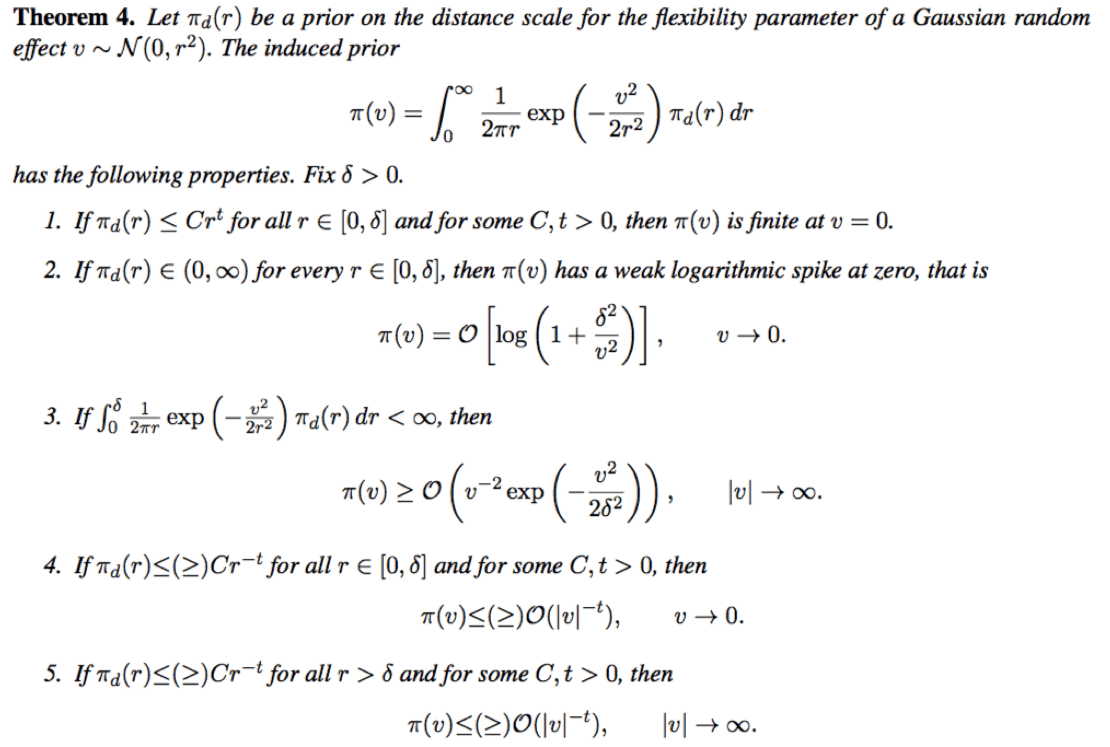
For those of you who don’t want to click through, it basically says the following:
- If the density of the prior on the standard deviation is finite at zero, then the implied prior on $latex \beta_j$ has a logarithmic spike at zero.
- If the density of the prior on the standard has a polynomial tail, then the implied prior on $latex \beta_j$ has the same polynomial tail.
(Not in the result, but computed at the time: if the prior on the standard deviation is exponential, the prior on $latex \beta_j$ still has Gaussian-ish tails. I couldn’t work out what happened in the hinterland between exponential tails and polynomial tails, but I suspect at some point the tail on the standard deviation does eventually get heavy enough to be seen in the marginal, but I can’t tell you when.)
With this sort of information, you can compute the equivalent of the bounds that I did on the Laplace prior for the general case (or, actually, for the case that will have at least a little bit of a chance, which is the monotonically decreasing priors on the standard deviation).
Anyway, that’s a long way around to say that you get similar things for all computationally useful models of sparsity. Why? Well basically it’s because these models are a dirty hack. They don’t allow us to represent exactly sparse signals, so we need to deal with that somehow. The somehow is through some sort of decision process that can tell a zero from a non-zero. Unfortunately, this decision is going to depend on the precision of the measurement process, which strongly indicates that it will need to know about things like $latex n$, $latex p$ and $latex \mathbf{X}$. One way to represent this is through an interaction wiht the prior.
You’d look better if your shadow didn’t follow you around, but it looks as though you’re tethered to the ground, just like every pound of flesh I’ve ever found. – Franklin Bruno in a sourceless light.
For a very simple decision process (the deterministic threshold process described in the previous post), you can work out exactly how the threshold needs to interact with the prior. In particular, we can see that if we’re trying to detect a true signal that is exactly zero (no components are active), then we know that $latex \| \mathbf{X} \boldsymbol{\beta} \| = 0$. This is not possible for these scale-mixture models, but we can require that in this case all of the components are at most $latex \epsilon$, in which case
$latex \| \mathbf{X}\boldsymbol{\beta} \| \leq \epsilon \| \mathbf{X} \|$,
which suggests we want $latex \epsilon \ll \| \mathbf{X} \|^{-1}$. The calculation in the previous post shows that if we want this sort of almost zero signal to have any mass at all under the prior, we need to scale $latex \lambda$ using information about $latex \mathbf{X}$.
Of course, this is a very very simple decision process. I have absolutely no idea how to repeat these arguments for actually good decision processes, like the predictive loss minimization favoured by Aki. But I’d still expect that we’d need to make sure there was a priori enough mass in the areas of the parameter space where the decision process is firmly one way or another (as well as mass in the indeterminate region). I doubt that the Bayesian Lasso would magically start to work under these more complex losses.
Models specified through their full conditionals
Why won’t you cheat with me? You and I both know that he’s done the same. – Jenny Toomey sings Franklin Bruno
So we can view the design dependence of sparsity priors as preparation for the forthcoming decision process. (Those of you who just mentally broke into Prepare Ye The Way Of The Lord from Godspell, please come to the front of the class. You are my people.) Now let’s talk about a case where this isn’t true.
To do this, we need to cast our minds back to a time when people really did have the original cast recording of Godspell on their mind. In particular, we need to think about Julian Besag (who I’m sure was really into musicals about Jesus. I have no information to the contrary, so I’m just going to assume it’s true.) who wrote a series of important papers, one in 1974 and one in 1975 (and several before and after, but I can’t be arsed linking to them all. We all have google.) about specifying models through conditional independence relations.
These models have a special place in time series modelling (where we all know about discrete-time Markovian processes) and in spatial statistics. In particular, generalisations of Besag’s (Gaussian) conditional autoregressive (CAR) models are widely used in spatial epidemiology.
Mathematically, Gaussian CAR models (and more generally Gaussian Markov models on graphs) are defined through their precision matrix, that is the inverse of the covariance matrix as
$latex \mathbf{x} \sim N(\mathbf{0}, \tau^{-1}\mathbf{Q}^{-1})$.
For simple models, such as the popular CAR model, we assume $latex \mathbf{Q}$ is fixed, known, and sparse (i.e. it has a lot of zeros) and we typically interpret $latex \tau$ to be the inverse of the variance of $latex \mathbf{x}$.
This interpretation of $latex \tau$ could not be more wrong.
Why? Well, let’s look at the marginal
$latex x_j \sim N\left(0, \tau^{-1}[Q^{-1}]_{ii}\right)$.
To interpet $latex \tau$ and the inverse variance, we need the diagonal elements of $latex \mathbf{Q}^{-1}$ to all be around 1. This is never the case.
A simple, mathematically tractable example is the first order random walk on a one-dimensional lattice, which can be written in terms of the increment process as
$latex x_{j+1} – x_j \sim N(0, \tau^{-1})$.
Conditioned on a particular starting point, this process looks a lot like a discrete version of Brownian motion as you move the lattice points closer together. This is a useful model for rough non-linear random effects, such as the baseline hazard rate in a Cox proportional hazard model. A long and detailed (and quite general) discussion of these models can be found in Rue and Held’s book.
I am bringing this case up because you can actually work out the size of the diagonal of $latex \mathbf{Q}^{-1}$. Sørbye and Rue talk about this in detail, but for this model maybe the easiest way to understand it is that if we had a fixed lattice with $n$ points and we’d carefully worked out a sensible prior for $latex \tau$. Now imagine that we’ve gotten some new data and instead of only $latex n$ points in the lattice, we got information at a finer scale, so now the same interval is covered by $latex nk$ equally spaced nodes. We model this with the new first order random walk prior
$latex x’_{j+1} – x’_j \sim N(0,[\tau’]^{-1})$.
It turns out that we can relate the inverse variances of these two increment processes as $\tau’ = k \tau$.
This strongly suggests that we should not use the same prior for $latex \tau$ as we should for $latex \tau’$, but that the prior should actually know about how many nodes there are on the lattice. Concrete suggestions are in the Sørbye and Rue paper linked above.
Not to coin a phrase, but play it as it lays – Franklin Bruno in Nothing Painted Blue
This type of design dependence is a general problem for multivariate Gaussian models specified through their precision (so-called Gaussian Markov random fields). The critical thing here is that, unlike the sparsity case, the design dependence does not come from some type of decision process. It comes from the gap between the parameterisation (in terms of $latex \tau$ and $latex \mathbf{Q}$) and the elicitable quantity (the scale of the random effect).
Gaussian process models
And it’s not like we’re tearing down a house of more than gingerbread. It’s not like we’re calling down the wrath of heaven on our heads. – Jenny Toomey sings Franklin Bruno
So the design dependence doesn’t necessarily come in preparation for some kind of decision, it can also be because we have constructed (and therefore parameterised) our process in an inconvenient way. Let’s see if we can knock out another one before my bottle of wine dies.
Gaussian processes, the least exciting tool in the machine learner’s toolbox, are another example where your priors need to be design dependent. It will probably surprise you not a single sausage that in this case the need for design dependence comes from a completely different place.
For simplicity let’s consider a Gaussian process $latex f(t)$ in one dimension with isotropic covariance function
$latex c(s,t) =\sigma^2 (\kappa|s-t|)^\nu K_\nu(|\kappa|s-t|)$.
This is the commonly encountered Whittle-Matérn family of covariance functions. The distinguished members are the exponential covariance function when $latex \nu = 0.5$ and the squared exponential function
$latex c(s,t)= \sigma^2\exp\left(\kappa |s-t|^2 \right)$,
which is the limit as $latex \nu \rightarrow \infty$.
One of the inconvenient features of Matérn models in 1-3 dimensions is that it is impossible to consistently recover all of the parameters by simply observing more and more of the random effect on a fixed interval. You need to see new replicates in order to properly pin these down.
So one might expect that this non-identifiability would be the source of some problems.
One would be wrong.
The squared exponential covariance function does not have this pathology, but it’s still very very hard to fit. Why? Well the problem is that you can interpret $\kappa$ as an inverse-range parameter. Roughly, the interpetation is that if
$latex |s – t | > \frac{ \sqrt{ 8 \nu } }{\kappa}$
then the value of $latex f(s)$ is approximately independent of the value of $latex f(t)$. This means that a fixed data set provides no information about $latex \kappa$ in large parts of the parameter space. In particular if $latex \kappa^{-1}$ is bigger than the range of the measurement locations, then the data has no information about the parameter. Similarly, if $latex \kappa^{-1}$ is smaller than the smallest distance between two data points (or for irregular data, this should be something like “smaller than some low quantile of the set of distances between points”), then the data will have nothing to say about the parameter.
Of these two scenarios, it turns out that the inference is much less sensitive to the prior on small values of $latex \kappa$ (ie ranges longer than the data) than it is on small values of $latex \kappa$ (ie ranges shorter than the data).
Currently, we have two recommendations: one based around PC priors and one based around inverse gamma priors (the second link is to the Stan manual). But both of these require you to specify the design-dependent quantity of a “minimum length scale we expect this data set to be informative about”.
Betancourt has some lovely Stan case studies on this that I assume will migrate to the mc-stan.org/ website eventually.
I’m a disaster, you’re a disaster, we’re a disaster area. – Franklin Bruno in The Human Hearts (featuring alto extraordinaire and cabaret god Ms Molly Pope)
So in this final example we hit our ultimate goal. A case where design dependent priors are needed not because of a hacky decision process, or an awkward specification, but due to the limits of the data. In this case, priors that do not recognise the limitation of the design of the experiment will lead to poorly behaving posteriors. In this case, it manifests as the Gaussian processes severely over-fitting the data.
This is the ultimate expression of the point that we tried to make in the Entropy paper: The prior can often only be understood in the context of the likelihood.
Principles can only get you so far
I’m making scenes, you’re constructing dioramas – Franklin Bruno in Nothing Painted Blue
Just to round this off, I guess I should mention that the strong likelihood principle really does suggest that certain details of the design are not relevant to a fully Bayesian analysis. In particular, if the design only pops up in the normalising constant of the likelihood, it should not be relevant to a Bayesian. This seems at odds with everything I’ve said so far.
But it’s not.
In each of these cases, the design was only invoked in order to deal with some external information. For sparsity, design was needed to properly infer a sparse signal and came in through the structure of the decision process.
For Gaussian processes, the same thing happened: the implicit decision criterion was that we wanted to make good predictions. The design told us which parts of the parameter space obstructed this goal, and a well specified prior removed the problem.
For the CAR models, the external information was that the elicitable quantity was the marginal standard deviation, which was a complicated function of the design and the standard parameter.
There are also any number of cases in real practice where the decision at hand is stochastically dependent on the data gathering mechanism. This is why things like MRP exist.
I guess this is the tl;dr version of this post (because apparently I’m too wordy for some people. I suggest they read other things. Of course suggesting this in the final paragraph of such a wordy post is very me.): Design matters even if you’re Bayesian. Especially if you want to do something with your posterior that’s more exciting than just sitting on it.
Dan:
Regarding your remark, “Design matters even if you’re Bayesian.” Why “even”? Design is central to statistics; it means as much to Bayesians as to anyone else. See chapter 8 of BDA (chapters 7 of the first two editions), for example.
It was a response to the idea that the likelihood principle inoculates Bayesians against design issues. Which it obviously doesn’t. As soon as you need to do something with your posterior design matters.
(On this, BDA is right, but at tension with a lot of what is taught)
RE: design matters to Bayesians, I’m curious how you would approach the simple random sampling example in section 2 here:
http://www.stat.cmu.edu/~larry/=stat705/Lecture6.pdf
from a Bayesian perspective.
Ojm:
I followed the link. Regarding the example, it would be even cleaner if the probabilities were all 1/2 because in that case the likelihood function is just a constant. Or, even simpler, if the probabilities were all 1: In that case you have an entire census, and again the likelihood function is a constant and is irrelevant to the problem entirely. No need to bring up Hoeffding’s inequality or whatever!
Isn’t the full likelihood function
\prod P(C_n|S_n,\theta) P(S_n|\pi)
Where C takes 3 values 0, 1 and unobserved (and is unobserved iff S=0).
The c_i are parameters and thus should appear in the condition. I would say the likelihood equals the binomial likelihood of the S_is when the c_is match the observed ones and 0 otherwise. Or, L(\pi, c_1, …, c_N) = (\prod_{i=1}^N P(S_i | \pi) ) \times \prod_{i: S_i=1} I_{C_i=c_i}, where C_is are the observations (as defined in the parent comment)?
Yes I think something like this is relevant. The normalised likelihood is 1 or 0: you do learn something about what the c_i can’t be from it.
Without further assumptions/constraints on how the c_i relate to each other though it is difficult if not impossible to generalise from observed sample to population. Eg if c=(1,2,99999999) and you happen to observe the 1 and 2 I doubt you’re gonna guess 99999999 without further info.
The frequentist solution, perhaps, relies on the idea of picking a representative sample with high prob? But could still be badly influenced by outliers or irregularity?
Looks like Basu may have made this point here (see Author’s note in the preview, which doesn’t require full access):
https://link.springer.com/chapter/10.1007/978-1-4612-3894-2_11
@ Andrew:
Yes the upshot of the example is, I think, that in this case the likelihood is irrelevant to the problem. But we can estimate the quantity of interest quite straightforwardly using non-likelihood-based methods.
So say the probs are all 1/2. What does the Bayesian do? Do you cover a similar example in eg BDA3?
Ojm:
Yes, we cover Bayesian inference for survey sampling in chapter 8 of BDA3 (chapter 7 of the first two editions).
I read that somewhat recently but don’t remember a specific solution to these sorts of difficulties. Is there a particular example you think is relevant to this case?
Ojm:
I’m not quite sure what is your question. You refer to “these sorts of difficulties” but I don’t see any difficulties at all to Bayesian inference from simple random sampling. It’s a straightforward problem whose straightforward solution we explain in the book!
So you don’t view it as an issue that the likelihood ‘doesn’t contain any info’ about the parameters of interest in this case?
Ojm:
From a Bayesian standpoint, the notation at that link is basically irrelevant. In the Bayesian world, all unknowns (whether they are parameters, predictive quantities, or whatever) have a joint probability distribution. Terms such as “likelihood” or “prior” are just for convenient. Mathematically, you have a model, you have p(everything), and your posterior distribution is p(everything unobserved | everything observed). I’m not saying it’s all trivial—there are challenges for example when considering the properties of Bayesian methods when the model is wrong—but the notation at that linked article doesn’t really do anything for Bayesian inference because it does not assign a probability distribution to the unknowns. The linked article represents a different way of performing inference for survey sampling, which is fine, but it doesn’t pose any problem for a Bayesian approach.
OK fair enough. However, I remember seeing this and similar examples and thinking the ‘frequentist’ approach seems pretty straightforward and intuitive, then reading corresponding Bayesian treatments and thinking they seem pretty convoluted.
Which doesn’t mean wrong of course. And this all links back to design vs model based approaches and eg the role of randomisation (which you discuss but still restrict to particular uses in a Bayes framework). So I find examples like this interesting.
Ojm:
In chapter 8 we give a Bayesian derivation of the classical estimate. The Bayesian estimate is as simple as the classical (“frequentist”) solution. For more difficult problems such as I deal with in my own research in political science, the classical solution won’t work.
Thanks, I’ll take another look
OK so I had another read.
If I’m understanding correctly, the key steps are:
– Introduce (in the notation above) an additional model p(c|theta), effectively treating c as data rather than parameter (though of course this distinction is blurred in Bayes)
– Do inference for the ‘superpopulation’ parameter theta (e.g. add a prior p(theta) and get the posterior)
– For the inference about c this is a ‘data’ or ‘predictive’ inference so you compute the posterior predictive for c under the theta posterior.
Really the key step is introducing p(c|theta). This connects to what I said above:
> Without further assumptions/constraints on how the c_i relate to each other though it is difficult if not impossible to generalise from observed sample to population
From a non-Bayesian perspective without a probability model p(c|theta), you still would seem to need some sort of constraint on the parameter space, e.g. F(c,theta) = 0 I guess, or at least regularity conditions, in order for the observed c to reliably inform you about the unobserved c.
Generally speaking I suppose the moral is everyone needs some regularity conditions/constraints, people just argue of what form to use. The Wasserman approach would be to use the minimal assumptions required to provide a probabilistic guarantee, which often won’t be in the form of a specific probability model, the Bayes approach is to assume a specific probability model and hope that it is ‘bland’ enough to give representative results for ‘similar’ model assumptions.
Ojm:
Yup, that’s math. No conclusions without assumptions.
Looking again at Wasserman’s example it seems worth noting that the bound on the range of cj values is very important in determining the usefulness of Hoeffding’s inequality – if e.g. cj in [0,999999] then, I think, the probability bound is basically P < 1 which seems pretty useless.
In Wasserman's example he uses cj in {0,1} which he states 'is not important', which seems misleading to me: the range of the values, e.g. the a and b in [a,b] appear explicitly in Hoeffding’s inequality. Using 0 and 1 means the dependence on these constants is hidden.
On the other hand, even assuming e.g. cj in [a,b] is a far weaker assumption than assuming a specific probability model.
Ojm:
See Section 7.6 of BDA3 for more than you’ll ever want to know about this topic!
Thanks, interesting read. Is it weird that I still want to know more? (Yes it is)
ojm:
I think one could argue what Larry gives is not a likelihood or at least it is a degenerate likelihood.
“The likelihood is the probability of the observations for various values of the parameters … A more formal definition of likelihood is that it is simply a mathematical function L(theta; y) = c(y) Pr(y; theta). The formal definition as a mathematical function though, may blur that the likelihood is the probability of re-observing what was actually observed.” http://statmodeling.stat.columbia.edu/wp-content/uploads/2011/05/plot13.pdf
Larry is taking the ci as being available for taking their average – so those are the “actually observed” – not the Si. The Si just indicate the selection of which ci to “actually observe”.
I have used data generating model as a synonym for likelihood in the past and I am starting to think I should stop doing that – at least if likelihood is being understood as something other that a probability model of how the “actually observed” came about. And to be for it to be truly capable of generating data it needs a prior to first generate the parameters that need to be set. Together the prior and data generating probability model should be able to emulate the reality that we have no direct access to, but wish to act in without being frustrated by it.
Hi Keith,
I missed this.
I think Wasserman defines it in a roundabout way, but the idea is roughly correct I think, subject to the zero/one requirement. But this zero/one requirement arises because of the point you make – we observe the c values.
In (sloppy) detail:
You have a set of units indexed by i available to take measurements on, and each measurement has a value c_i.
You observe only n of the units, i.e.
in = (i_1,i_2,…,i_n)
Corresponding to this is
cn = (c_i_1,c_i_2,…c_i_n)
The given data are the vectors
(in,cn)
That is, you know which units where observed and what their c values were.
Assuming the c are deterministic values of the i – i.e. they are measured without noise – then the probability of observing those c that you did, i.e. cn, is simply the probability of observing the units you did, i.e. the probability of in. Which is the ‘randomisation’ probability or whatever you call it.
But there is a key point here: the deterministic function needs to be included in the likelihood. Write cm = c(im) for the function giving the cm vector corresponding to any im vector. Intuitively: the c values corresponding to the actually observed units.
Then
p(observed data| full parameter)
= p(Cn=cn,In=in|C=c)
= p(Cn=cn|In=in,C=c)p(In=in|C=c)
Now
p(Cn=cn|In=in,C=c) = 1 if cn = c(in)
and
p(Cn=cn|In=in,C=c) = 0 if cn != c(in)
Hence the likelihood is
p(In=in|C=c) if cn = c(in)
and
0 if cn != c(in)
The component p(In=in|C=c) is constant for the randomised case and can be normalised to 1.
Intuitively: the likelihood is zero for those ‘full’ vectors c that don’t match the ‘partial’ actually observed vectors cn.
For example, if I observed
cn = (4,5,6) and in = (1,2,3)
then
c = (4,5,6,1,2) and i = (1,2,3,4,5)
has likelihood 1 but
c = (4,1,6,5,2) and i = (1,2,3,4,5)
has likelihood 0.
Intuitively: by observing the first three components of c we know that the full c can only be one with those three components. We have learned something.
For inference about the mean of c then we need to consider all possible completions of c that are consistent with the observed data.
One could report all possible completions, report the max and min based on bounds on the c values or report a distribution over the mean of completions induced by a distribution over the remaining c values. Etc.
Side point re
> And to be for it to be truly capable of generating data it needs a prior to first generate the parameters that need to be set.
This makes no sense to me. Eg
p(y | theta)p(theta | lambda)
just requires one to set a lambda etc. Infinite regress and all that.
I’d rather just say p(y;theta) specifies a distribution over y for any choice of theta. It defines a family of generative models.
Almost every simulation code works like this. Eg a PDE code that takes a diffusion coefficient and some ICs/BCs and gives an answer.
A sensible inverse problem would be to ask eg what ICs give results consistent with observations and you can just plug-in a series of values to determine the inverse set image:
{ICs | F(ICs) approx = observations}
The model is perfectly generative for each choice of ICs and you don’t need to choose the ICs to plug in in any ‘random’ way – you could eg use a for loop.
(And using a sequence of values eg a for loop is not the same as using a delta function for theta as sometimes seems to be implied! It just means you have a function and are free to plug in any value you want at any point in time and these can and will usually be different values)
Isn’t this exactly what poststratification does? Your point estimate is your decision (I want to minimise a certain type of error for a certain posterior summary)
I agree with other commenters about that likelihood function being incomplete. There will be N factors, each including a term related to S_i as given in that link. But there is a term related to the actual values measured which is missing. I will distinguish the unknown constants (fixed in the frequentist case) c_i and the observed values d_i.
When S_i = 1 the likelihood includes a term which is 1 for c_i = d_i and 0 otherwise (when S_i = 0 the likelihood term does not depend on c_i). We can use maximum likelihood to estimate the values of c_i for the terms with S_i = 1 and the answer is unsurprisingly c_i = d_i. But we cannot estimate the values of c_i for the terms with S_i = 0.
A) We are asked to estimate theta the mean of all the c_i values. The estimator proposed is unbiased but has a lot of variance and other undesirable properties. It can give estimates higher than 1, even though we know that the mean of values from {0,1} has to be in the range [0,1].
B) A better estimate would be to normalize by the actual number of observed points sum(S_i) and not the expected number of observed points (the parameter PI which is assumed known). Essentially, we take the observed average as representative for the whole population: theta = sum(S_i*d_i)/sum(S_i).
The only issue is what to do when all the points are hidden, as we would be dividing by 0 and the sample average is not defined. If this case is excluded, the estimator is unbiased and has lower MSE. If we set some value (like 1/2) in the cases where the estimator is not well defined there may be bias but vanishes as N grows.
C) What about the Bayesian treatment? If we model the constants as being independent, the prior for each c_i will be 0/1 with 50%/50% probability. For the observed points, the posterior is d_i and for the others the posterior is still 0/1 with 50%/50% probability.
We can calculate the posterior distribution for the sum of the constants (N*theta) which will be the binomial distribution for the uncertain constants Binom(size=N-sum(S_i),prob=0.5) plus the sum of the constants which are precisely known sum(S_i*d_i).
The expected value of this distribution is simply the sum of the observed values plus 0.5 for each unobserved value. The posterior expected value for theta is the weighted average of the sample mean for the observed values and 1/2 for the unobserved values.
D) An alternative Bayesian calculation would be to assume that the prior for each constant is a binomial with probability p unknown. In that case the observed constants are precisely defined and for those that remain uncertain the posterior can be updated (as long as any values have been observed, of course).
The posterior distribution for theta will be more complex in this case but if I am not mistaken when the prior for p is flat we recover the same estimator given in B) above. The expected value for each unknown constant is p, which we estimate as the average of the observed values. The expected value for theta is therefore equal to the observed average: theta = sum(S_i*d_i)/sum(S_i).
I agree re the likelihood: it is constant, eg 1 when normalised, for those full c consistent with the observed data, but zero for those c not consistent with the observed data.
This tells us something: some c that were possible before the data are no longer possible after the data. Basu also discusses this in detail in the link above.
The Bayesian posterior is the restriction of an additional assumed ‘super population’ model p(c) to this set. If the c are independent then nothing is learned except what the likelihood tells you as an indicator function for possible c values. When they are assumed to arise from a common source then observing some of c can tell you about the unobserved values, but not otherwise.
In general, I basically see the likelihood function as the indicator function for the inverse set image of the data ie the indicator function for {theta | f(theta) = y0}. Except for probably models we need a real valued membership value p(y0;theta) for theta instead of a 0/1 indicator. It’s been noted in the literature that pure likelihood theory is basically the same as fuzzy set/possibility theory, presumably for this reason.
In the present case there is no probability model for the c and no specified dependence so all we can do is report the inverse image of the data, ie those parameters that are consistent with the observations. This is a 0/1 likelihood function playing the role of indicator function.
Though if you have a bound on the other c values you can use this to deterministically bound what the mean of any completion of c would be. Or you could construct a probability model for the completion of c, which is pretty much Bayes.
I think it’s good to keep in mind that the likelihood is a function of the parameter values, even when the dependency is a constant function for some parameters (those corresponding to the non-observed data) and a delta function for the others.
It’s true that if the model assumes that the constants are independent we cannot infer anything about the non-observed parameters (and I think the independence assumption makes more sense than the “super population” model in this case). But the parameters of interest are not the c_i’s !
In fact the likelihood function that we have to write is L(theta). The function Wasserman gives is incomplete, making inference impossible, but we know how to write the probability of the data given the parameter.
If we consider the sufficient statistics S (the number of observed values) and X (the number of ones observed), the correct likelihood function is
L(theta) = p^S (1-p)^(N-S) binomial(S,X) binomial(N-S, N*theta-X) / binomial(N, N*theta)
where p is the probability of observing each value and the binomial factors are the number of arrangements of X observed ones out of S observed values, N*theta-X non-observed ones out of N-S non-observed values and N*theta ones out of N values.
Keeping only the terms which depend on theta, we find that the likelihood is proportional to
L (theta) ~ (N*theta)! / (N*theta-X)! * (N-N*theta)! / ((N-N*theta)-(S-X))!
= N*theta * (N*theta-1) * (N*theta-2) * … [ X terms ] … * (N-N*theta) * (N-N*theta-1) * (N-N*theta-2) * … [ S-X terms ] ….
One can easily estimate theta using maximum likelihood. There is no need to create ad-hoc estimators.
We can also use this likelihood to do a Bayesian analysis. Of course, a prior distribution for the parameter theta will be required.
> In fact the likelihood function that we have to write is L(theta). The function Wasserman gives is incomplete, making inference impossible, but we know how to write the probability of the data given the parameter.
But the likelihood should be written as a function of the full parameter before any restriction is considered. You do inference for the full parameter and then consider the implications for functions of the full parameter like mean(c).
> If we consider the sufficient statistics S (the number of observed values) and X (the number of ones observed), the correct likelihood function is…
I think the key point here is that for this problem the ordering actually does matter – we assume that we actually do observe e.g. the first component of c, the second component of c etc, not just the c value of an unknown unit. The only thing that is random is the choice of _which_ unit we observe.
And this, I think, is why the likelihood is flat/deterministic (see response above to Keith).
> But the likelihood should be written as a function of the full parameter
I think we agree that the likelihood function for what you call the full parameter (the vector of c_i’s) given the observed data (s_i indentifies the points observed, and d_i the corresponding values) is
L(c_1,…,C_N;d_1,…,d_N,s_1,…,s_N) = L(c_1;d_1,s_1) * … * L(c_N;d_N,s_N)
where each factor L(c_i;d_i,s_i) is equal to p^s_i*(1-p)^(1-s_i) = (1-p) when s_i = 0
and is equal to p^s_i*(1-p)^(1-s_i)*delta(s_i,d_i) = p*delta(s_i,d_i) when s_i = 1.
Knowing some of the c_i’s doesn’t give any information about the unobserved c_i’s unless the model includes some codependence between them.
In a Bayesian analysis, you can always make inference about the uncertain values because you have a distribution for them (equal to the prior if the c_i’s are unrelated, or informed by the observed c_i’s if the distribution depends on a common hyperparameter, for example).
> You do inference for the full parameter and then consider the implications for functions of the full parameter like mean(c).
Why? You can do much better by writing the model in terms of the parameter of interest theta = mean(c).
> I think the key point here is that for this problem the ordering actually does matter
It does, but it doesn’t. Randomizing which fixed values c_i you observe is like sampling the observed values from the distribution of c_i’s (without replacement).
The estimator for theta proposed by Wasserman is based on that kind of sampling without making it explicit.
I showed how the correct likelihood function for the parameter of interest L(theta) can be easily written down and used to calculate a better (maximum likelihood) estimator.
> Why? You can do much better by writing the model in terms of the parameter of interest theta = mean(c).
Hmm well as you say the problem is incomplete if stated only in terms of the mean. I would think the full parameter is required for it to be a generative model. But I’ll have another think about your answer.
Does your analysis work for the case where the c_i are known to lie in a given interval [a,b] for known a, b? It seems like your answer takes advantage of the {0,1} parameter space – fair, but the other answers generalise more directly. I suppose you could use the order statistics and an empirical likelihood or something tho?
You are right, the solution I propose is for the particular case c_i={0,1} assumed by Wasserman (in this case the detail is really important). Given the randomisation, the order of the c_i’s is irrelevant but the values of the c_i’s are required to write the likelihood function. When they are binary, they are perfectly determined given theta: there will be N*theta ones and N*(1-theta) zeros.
To make it clear: let’s say there N=3 points, we observe one single point and its value is 1.
P(one observation, the value is 1| theta) = P(the value is 1| one observation, theta) * P(one observation)
The second term is trivial and if the values are in {0,1} we can calculate the first term. For example, for theta = 1 the equiprobable cases are
(1,0,0), (0,1,0) and (0,0,1) so the probability of the value being 1 (getting 1 in the first position) is 1/3. For theta = 2 the equiprobable cases are (1,1,0), (1,0,1) and (0,1,1) and the probability of the value being one is 2/3. For theta = 3, the probability of the value being 1 is 1.
The likelihood function is (ignoring the constant term):
P(theta=0| one observation, the value is 1) = 0
P(theta=1|…) = 1/3
P(theta=2|…) = 2/3
P(theta=3|…) = 1
Fixing theta doesn’t determine the values of the c_i’s in the general case. For example, if the values are in {0, 1/2, 1} we cannot get the probability of observing the data for theta = 2. The possible combinations are (1, 1, 0), (1, 0, 1), (0, 1, 1), (1, 1/2, 1/2), (1/2, 1, 1/2), (1/2, 1/2, 1). If we have two 1’s and one 0, two out of three are compatible with the data. If we have one 1 and two 1/2’s, one out of three is compatible with the data.
Interesting.
Thinking out loud about the N=3, n=1 case…
From a pure likelihood perspective, and considering the ‘full parameter’ problem, I wanna say that if we observe the first element of c and we know that c_i in {0,1} then
(1,0,0), (1,0,1), (1,1,0), (1,1,1)
have the same normalised likelihood value of 1, as above, and all other combos e.g. (0,…) have likelihood 0.
Suppose the goal is inference for the sum of c, theta(c), from a pure likelihood POV. Then we can write the full parameter as c = (theta(c), c’) where c’ = c-theta(c) i.e. we substract the (scalar) sum theta from the (vector) parameter c to get the (vector) differences c’.
Then we can write L(c) = L(theta,c’).
To do inference about theta we consider the profile likelihood
Lp(theta) = sup_{c’} L(theta,c’).
This is simply the flat likelihood again for each compatible theta. I.e. the profile likelihood says that theta = 1, 2, 3 are ‘equi-possible’ (profile likelihood can be interpreted as a ‘possibilistic’ inference a la https://en.wikipedia.org/wiki/Possibility_theory).
Alternatively, if I was to try to do things ‘predictively’ I might decide to randomly (uniformly) draw from the set of remaining consistent vectors above to compute the completion.
In this case theta = 2 would have probably 1/2 and theta = 1 and theta = 3 would have probably 1/4, since (1,0,1) and (1,1,0) both give theta = 2.
But in neither case do I get your answer of theta = 3 being the most supported. Perhaps this is related to whether the reduction is carried out before or after the inference? If so, reminds me a little of the marginalisation paradoxes.
But mere wordiness was never the problem I had with your style. Perhaps — rather contrary to my expectation — prose purplosity varies inversely with inebriation, in which case all I can say is…
Your fascination with form over content really is something to behold. Just to blow your mind: I wasn’t drinking while writing three thousand fairly technical words.
Dan:
Don’t take the comments too seriously. Just as we contribute to the general public discussion by blogging for free, and in exchange we expect people to take our ideas seriously but to cut us some slack on our idiosyncratic ways of expressing ourselves, so should we recognize that our commenters are contributing to the general public discussion by commenting for free, and in exchange we should cut them some slack and allow them to give us a hard time on occasion, as long as they also other times contribute to the intellectual discussion,as most of our commenters do.
This is not to say you shouldn’t talk back to commenters—heck, I even respond to trolls sometimes!—just that it’s a privilege of commenters to have some fun from time to time, as that’s one of the things people can do to make commenting a more appealing pastime. And, as I expect you’re aware, our comment section is wonderful, arguably the best on the internet.
That’s what I thought I was doing. Gently chiding him for only ever commenting on style while missing the idea that perhaps I’m just having fun.
So your references to glasses and bottles of wine were all lies? My confidence in you is shattered. What’s next? Do you actually like show tunes at all…?
Think of it as a structural bottle of wine. Not unlike the joke about not being pithy enough for twitter in the extremely long an flabby post about how a method can’t shrink the noise away. Or the focussed deep dive into an excellent but underrated songwriter scaffolding a deep dive into an under appreciated concept.
Or I could just be having fun.
I wasn’t going to reply because it didn’t seem worthwhile for either of us but this is still niggling at me so I might as well unburden myself. I’m not fascinated with form over content; I like the content, I want more of the content, and if I didn’t you wouldn’t have found yourself telling me about how easy it is to not read things I don’t like because I already know that and wouldn’t have bothered. Nor am I missing the idea that you’re just having fun; that’s both obvious and beside the point (that point being for me to whine about the fun I’m not having while trying to get at the good stuff).
I do think the multi-sentence parentheticals go too far. Maybe if he could just keep it to the italicized quotes between sections and the occasional inline link… ;-)
I really appreciate the notes on the identifiability of Gaussian process covariance functions.. both here and in the Entropy paper.. it makes precise something that I have had only the vaguest appreciation of before.
The rest of the post (and the last one) are fascinating.. but so much of it seems counter to my understanding its a bit difficult to respond to. Or rather its a bit hard to respond to only one point..
Surely the procedure you describe in the previous post would create a probabilistic specification P(Y_1,…,Y_M|X_1,..X_M) which is not a marginal of P(Y_1,…,Y_M+N|X_1,..X_M+N).. Broadly isn’t Kevin van Horn right?
“In this case, priors that do not recognise the limitation of the design of the experiment will lead to poorly behaving posteriors. In this case, it manifests as the Gaussian processes severely over-fitting the data.”
This quote jars a bit (and I understand its a humorously written post done in your spare time).. but to quote your paper which I find really clear and insightful:
“In such cases, the posterior eventually concentrates not on a point but rather around some extended submanifold of parameter
space—and the projection of the prior along this submanifold continues to impact the posterior even as
more and more data are collected.”
Isn’t that what is going on here.. the likelihood is flat in a significant region of the parameter space and in that region the posterior will equal the prior.. We may be talking past each other due to terminology.. but I don’t see why this should require an adjustment of the prior – in fact isn’t an argument for leaving it alone?.. The posterior will contain all the complex functions that lie appropriately close to the data which in aggregate is a highly regularised function. I am sure I could dig up an old Radford Neal or Savage quote .. Bayesian models don’t overfit … essentially because they don’t fit .. they condition..
The big point that confuses me in the two posts is if you are defending using data dependant priors from a foundational point of view.. or if you are employing them as a heuristic device..
“Of these two scenarios, it turns out that the inference is much less sensitive to the prior on small values of \kappa (ie ranges longer than the data) than it is on small values of \kappa (ie ranges shorter than the data).”
are both of the use of the word “small” here correct? I don’t mean to be pedantic.. I just don’t follow..
Thanks for such an interesting post! Apologies that I may have missed some things.. I will continue to reread and think about it..
David
Hi David,
I guess the point where we depart is whether or not things like n and p are data or if they’re design information. I think of them as the latter, so priors that depend on n and p are not “design dependent”. X is a different matter, but I think there are a lot of strong reasons to scale your model so parameters (and hence priors) are O(1), even if you feel this introduces design dependency.
As for those quotes – well, I’m not sure they’re different things. The quote from the paper is definitely applicable here: you are seeing your prior on the sub-data scales and so your inference will be sensitive to that aspect of the prior. In the post, I’m (clumsily) trying to argue (back with simulations from Betancourt) that if your interest is prediction, then you will do much better cutting off those parts of the posterior. The key thing you see in the simulations is that the behaviour at those ridiculous scales does not just wash away at aggregate, but does effect point summaries as well as simulations.
It really comes down to the idea that design information isn’t data, it’s meta-data. I don’t see the philosophical objection to conditioning on meta-data, and you get some serious practical benefits. (Like you can understand exactly why the Bayesian Lasso doesn’t work)
> Bayesian models don’t overfit … essentially because they don’t fit .. they condition..
They really can over-fit! For conditioning to prevent over-fitting, you need the joint to not have much mass on predictions that do not generalize, which really needs you to specify your prior correctly.
>are both of the use of the word “small” here correct?
Nope. The second one should be large. That damn bottle of wine.
> Broadly isn’t Kevin van Horn right?
Well… I don’t think either of us are completely right. This one is a hard topic and we’re viewing it through two very different lenses. My point is not that these models are somehow nested, but rather information about how big the model is (meta-data) is necessary to set priors.