“Eat what you are while you’re falling apart and it opened a can of worms. The gun’s in my hand and I know it looks bad, but believe me I’m innocent.” – Mclusky
While the next episode of Madam Secretary buffers on terrible hotel internet, I (the other other white meat) thought I’d pop in to say a long, convoluted hello. I’m in New York this week visiting Andrew and the Stan crew (because it’s cold in Toronto and I somehow managed to put all my teaching on Mondays. I’m Garfield without the spray tan.).
So I’m in a hotel on the Upper West Side (or, like, maybe the upper upper west side. I’m in the 100s. Am I in Harlem yet? All I know is that I’m a block from my favourite bar [which, as a side note, Aki does not particularly care for] where I am currently not sitting and writing this because last night I was there reading a book about the rise of the surprisingly multicultural anti-immigration movement in Australia and, after asking what my book was about, some bloke started asking me for my genealogy and “how Australian I am” and really I thought that it was both a bit much and a serious misunderstanding of what someone who is reading book with headphones on was looking for in a social interaction.) going through the folder of emails I haven’t managed to answer in the last couple of weeks looking for something fun to pass the time.
And I found one. Ravi Shroff from the Department of Applied Statistics, Social Science and Humanities at NYU (side note: applied statistics gets a short shrift in a lot of academic stats departments around the world, which is criminal. So I will always love a department that leads with it in the title. I’ll also say that my impression when I wandered in there for a couple of hours at some point last year was that, on top of everything else, this was an uncommonly friendly group of people. Really, it’s my second favourite statistics department in North America, obviously after Toronto who agreed to throw a man into a volcano every year as part of my startup package after I got really into both that Tori Amos album from 1996 and cultural appropriation. Obviously I’m still processing the trauma of being 11 in 1996 and singularly unable to sacrifice any young men to the volcano goddess.) sent me an email a couple of weeks ago about constructing interpretable decision rules.
(Meta-structural diversion: I starting writing this with the new year, new me idea that every blog post wasn’t going to devolve into, say, 500 words on how Medúlla is Björk’s Joanne, but that resolution clearly lasted for less time than my tenure as an Olympic torch relay runner. But if you’ve not learnt to skip the first section of my posts by now, clearly reinforcement learning isn’t for you.)
To hell with good intentions
Ravi sent me his paper Simple rules for complex decisions by Jongbin Jung, Connor Concannon, Ravi Shroff, Sharad Goel and Daniel Goldstein and it’s one of those deals where the title really does cover the content.
This is my absolute favourite type of statistics paper: it eschews the bright shiny lights of ultra-modern methodology in favour of the much harder road of taking a collection of standard tools and shaping them into something completely new.
Why do I prefer the latter? Well it’s related to the age old tension between “state-of-the-art” methods and “stuff-people-understand” methods. The latter are obviously preferred as they’re much easier to push into practice. This is in spite of the former being potentially hugely more effective. Practically, you have to balance “black box performance” with “interpretability”. Where you personally land on that Pareto frontier is between you and your volcano goddess.
This paper proposes a simple decision rule for binary classification problems and shows fairly convincingly that it can be almost as effective as much more complicated classifiers.
There ain’t no fool in Ferguson
The paper proposes a Select-Regress-and-Round method for constructing decision rules that works as follows:
- Select a small number $latex k$ of features $latex \mathbf{x}$ that will be used to build the classifier
- Regress: Use a logistic-lasso to estimate the classifier $latex h(\mathbf{x}) = (\mathbf{x}^T\mathbf{\beta} \geq 0 \text{ ? } 1 \text{ : } 0)$.
- Round: Chose $latex M$ possible levels of effect and build weights
$latex w_j = \text{Round} \left( \frac{M \beta_j}{\max_i|\beta_i|}\right)$.
The new classifier (which chooses between options 1 and 0) selects 1 if
$latex \sum_{j=1}^k w_j x_j > 0$.
In the paper they use $latex k=10$ features and $latex M = 3$ levels. To interpret this classifier, we can consider each level as a discrete measure of importance. For example, when we have $latex M=3$ we have seven levels of importance from “very high negative effect”, through “no effect”, to “very high positive effect”. In particular
- $latex w_j=0$: The $latex j$th feature has no effect
- $latex w_j= \pm 1$: The $latex j$th feature has a low effect (positive or negative)
- $latex w_j = \pm 2$: The $latex j$th feature has a medium effect (positive or negative)
- $latex w_j = \pm 3$: The $latex j$th feature has a high effect (positive or negative).
A couple of key things here that makes this idea work. Firstly, the initial selection phase allows people to “sense check” the initial group of features while also forcing the decision rule to only depend on a small number of features, which greatly improves the ability for people to interpret the rule. The second two phases then works out which of those features are used (the number of active features can be less than $latex k$. Finally the last phase gives a qualitative weight to each feature.
This is a transparent way of building a decision rule, as the effect of each feature used to make the decision is clearly specified. But does it work?
She will only bring you happiness
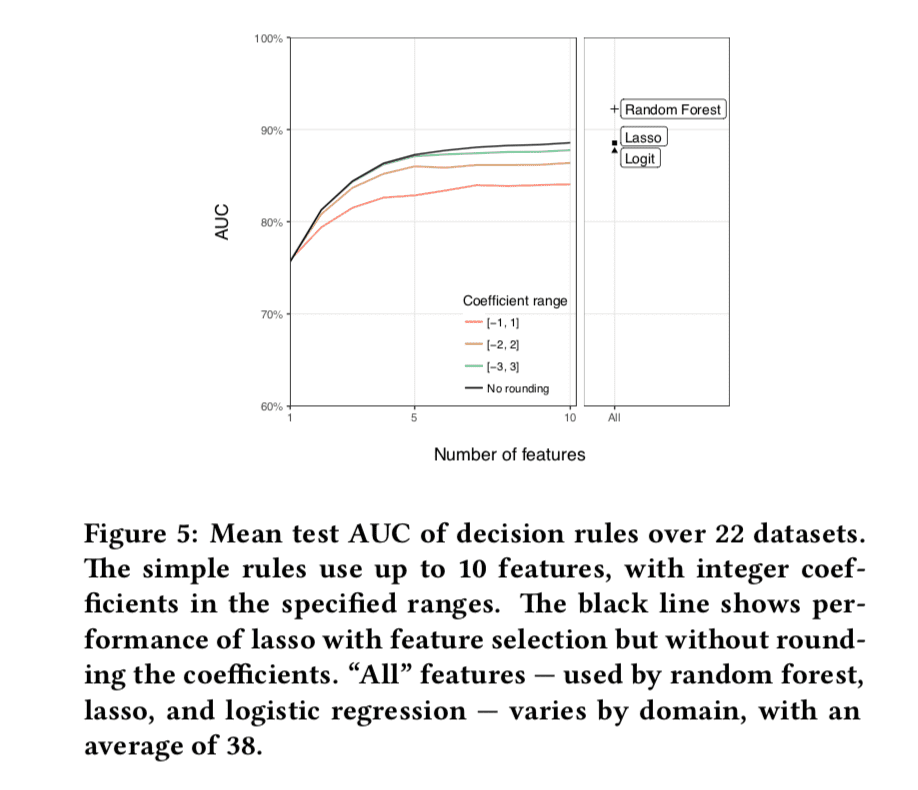
The most surprising thing in this paper is that this very simple strategy for building a decision rule works fairly well. Probably unsurprisingly, complicated, uninterpretable decision rules constructed through random forests typically do work better than this simple decision rule. But the select-regress-round strategy doesn’t do too badly. It might be possible to improve the performance by tweaking the first two steps to allow for some low-order interactions. For binary features, this would allow for classifiers where neither X nor Y are strong indicators of success, but the co-occurance of them (XY) is.
Even without this tweak, the select-regress-round classifier performs about as well as logistic regression and logistic lasso models that use all possible features (see the above figure from the paper), although it performs worse than the random forrest. It also doesn’t appear that the rounding process has too much of an effect on the quality of the classifier.
This man will not hang
The substantive example in this paper has to do with whether or not a judge decides to grant bail, where the event you’re trying to predict is a failure to appear at trial. The results in this paper suggest that the select-regress-round rule leads to a consistently lower rate of failure compared to the “expert judgment” of the judges. It also works, on this example, almost as well as a random forest classifier.
There’s some cool methodology stuff in here about how to actually build, train, and evaluate classification rules when, for any particular experimental unit (person getting or not getting bail in this case), you can only observed one of the potential outcomes. This paper uses some ideas from the causal analysis literature to work around that problem.
I guess the real question I have about this type of decision rule for this sort of example is around how these sorts of decision rules would be applied in practice. In particular, would judges be willing to use this type of system? The obvious advantage of implementing it in practice is that it is data driven and, therefore, the decisions are potentially less likely to fall prey to implicit and unconscious biases. The obvious downside is that I am personally more than the sum of my demographic features (or other measurable quantities) and this type of system would treat me like the average person who has shares the $latex k$ features with me.
1. No, you’re not in Harlem. Harlem is northeast of you.
2. Is this article you discuss related to the classic paper, by Robyn Dawes, “The robust beauty of improper linear models in decision making,” that’s in the classic Kahneman/Slovic/Tversky book? (By the way, “improper linear models” in that title refers to weighted averages where the weights are set ahead of time rather than being estimated from data.)
1. Ok!
2. I’m not sure. (I mean, I know less about decision making than I do about curling), but the paper references the Dawes paper but not the book.
3. Setting weights ahead of time rather than estimating them from the data is an interesting idea. Is this expert knowledge, or some version of the training/testing/evaluation sample splitting idea that has become quite popular?
Basically the idea is just to make all the contributions O(1) and choose the sign of the coefficient to get a positive correlation between the input and the output. Then decide yes if the resulting sum is positive enough.
You beat me to the Dawes cite. That was my immediate thought as well. Also covered in his book with Reid Hastie, _Rational Choice in an Uncertain World_.
@Dan. The advantage here is that you don’t need a dataset to train on. You just ask “experts” what the relevant variables are then do as Daniel Lakeland explains.
I actually cofounded a startup investment firm based on this principle combined with diversification.
Yes, it’s related and we cite it and another Dawes paper, too.
“You should be ashamed, Seanus” might be more on brand :)
Daniel vs the young canoeist.
Dan, what are your thoughts on ‘Depends What You Mean by Extremist’?
I found that after I had read it I had a strong urge to discuss it with people but that I only wanted to discuss it with people who had read the book as well. I think this was in an attempt to avoid the “How Australian are you?” type conversations which aren’t particularly pleasant.
I’m only half way through. As a book I liked Murder in Mississippi (God will strike you down in the US) more. As something that tells me about my country, it’s a deep dive into the archtypes we don’t really talk about. The talk about structural vs non-structural violence (and the ways we don’t reflect on them) is interesting. I mostly like it.
All that being said, that piece he wrote about the rally and counter protest in Brisbane covers a lot of the same ground.
Murder in Miss should be good read. Thanks for suggestion
I wrote a paper in the 1990,s where I called these types of analyses understudy analyses – analyses that stand in for those who don’t appreciate the complex analyses (actors). It was mainly about facilitating communication between statisticians and clinicians. I worked on it for more than a year. One journal reviewer called it irresponsible and dangerous – likely part of that short shrift against applied statistics that was even more severe back then.
> less likely to fall prey to implicit and unconscious biases
That’s likely in the collected data already.
> Setting weights ahead of time rather than estimating them from the data is an interesting idea. Is this expert knowledge
We used a group judgmental process to get the weights here – https://www.cambridge.org/core/journals/canadian-journal-on-aging-la-revue-canadienne-du-vieillissement/article/convening-expert-panels-to-identify-mental-capacity-assessment-items/21CAD5945E48EF160103B8DFAF84B715
The more interesting example was developing a predictive index for whether a judge would find for child neglect for a children’s aid group. A rely neat non-linear model was developed. At the time, I was reticent to statistically adjust the judgmental rates using the same “data” that was used in the group process to facilitate the clarification and extraction of judgment.
> throw a man into a volcano every year
Gee when I was there, one only had to worry about the quality of the cookies when it was your turn to bring them for the seminar (apparently heavily weighted in tenure decisions).
Keith said:
>> less likely to fall prey to implicit and unconscious biases
>That’s likely in the collected data already.
That is very true. I tried to word that sentence carefully but I was never happy with it. Obvious places where bias can seep in are through the choice of the initial (large) feature set, choice of the idea of “success”, and construction of the data split. Also if the data is somehow not a random sample of the population, then you’ll also have problems.
I don’t know much about the topic but THANK GOD that the quote in the beginning made me listen to McLusky after 5 years of not having listened to them.
Tbh I prefer Future of the Left (travels with myself and another is an all-time fav album) but they were less thematically appropriate
Oh yes. Spent a very sweaty Friday night in Fortitude Valley with FoTL last week, fantastic to see them again.
Definitely related to the Dawes paper. The Dawes paper’s main point is that if you have a bunch of regressors that all have positive correlation with one another and they all have positive effects on the outcome, you can basically make up weights and still result in very similar predictions compared to the estimated linear regression weights.
Criminal justice examples tend to fit this very well, because most of the data collected are negative, in that any interaction with the system tends to signal future bad outcomes. Also deviant behavior tends to be general — so e.g. those who commit robberies are also more likely to run a stop sign. Administrative criminal justice datasets basically never collect signals that would indicate future good behavior — like you have a wife or a good job that will keep you out of trouble going forward. All you have are past instances of bad behavior (which of course signal that more bad behavior is likely to occur in the future).
These simple decision rules will work better in cases that the effects are linear and additive — but I think that actually works ok for many social science examples. My pet theory about that is in noisy data linear and additive are the best you are going to get — hence we have plenty of CJ examples where complicated models do no better than very simple ones. Ravi has another paper that is a great example with NYPD stop decisions. Here is another recent example where folks on MTurk did just as good a job with little info, http://advances.sciencemag.org/content/4/1/eaao5580. Which that is a long standing finding in these decisions, Bernard Harcourt has a good history of that in his book Against Prediction.
My guess is that Frank Harrell would roll his eyes at the focus in this paper on optimizing decision rules with respect to binary classification accuracy. Am I right on that?
We don’t focus on optimization in the paper. The paper is against optimization. Just read it.
What does Frank Harrell have against assessing decision rules based on binary classification (because that’s what the paper does)? I’m assuming that if he doesn’t like optimizing, he’s also against assessing. But what should you assess on instead? Or are you making an argument against single criterion assessment of decision rules? Because I suspect (for reasons given by AndyW and Dawes) that this would work just as well against multi-criterion optimized rules assuming the initial selection step is based on multiple objectives.
My only actual actual criticism (now that I’ve had a bit more time to think) is that $latex [-M,M]$ isn’t a great interval for logistic regression coefficients and it would make more sense to have, if $latex M >3$, the weights scaled to discrete points in the interval $latex [-3,3]$. This would preserve the discrete, interpretable nature without screwing up the logistic regression.
Just for context here, I’m interested in reasons for Harrell’s apparent dislike of optimizing decision rules against binary classification accuracy for two reasons. Firstly, almost everyone knows more about decision theory than I do, but naively it seems like if your decision is binary and you have data on outcomes from very similar cases, that would be a good way to at least initially validate a classifier (and then continuously evaluate it in a prequential manner). Secondly, a thing I have a lot more experience with: when a very prominent statistician (like Harrell) says something is like “I hate optimizing decisions rules on classification accuracy” there is almost always a lot of context (either explicitly or implicitly given) and usually a whole lot more nuance. So I’m very interest in checking the context.
My guess is that Ben is simply referring to the problem with #correctly classified/#total cases as a measure of predictive performance, namely unequal costs of the two kinds of error. Am I right on that?
:)
Well, it would be best to get Frank’s word himself, but my take from his blog and his posts on the Cross Validated site is that he does not like when people choose the model that maximizes the area-under-the-curve statistic. This is just another way of saying what Kit noted — that AUC does not necessarily get the weights for false-positives and false-negatives right (it is pretty easy to construct cases where AUC is improved but will fail badly in practice by not focusing on the right tails).
That being said, the idea of simple models performing quite well relative to complicated ones I think is likely to hold even if not comparing via AUC, so I don’t take that as an obvious criticism of this work.
There are two obvious ways you could incorporate different weights for false-positives and false-negatives that apply to the simple models procedure here. One is instead of logistic regression use a different loss function that is more applicable to your situtation (like quantile regression, see this Richard Berk article for an example, http://dx.doi.org/10.1007/s10940-010-9098-2). Another is to do your normal logistic model, but then change where you set the threshold to make your decision (e.g. at a predicted prob. of 1% instead of a predicted prob. of 50%).