We (Sean Talts, Michael Betancourt, Me, Aki, and Andrew) just uploaded a paper (code available here) that outlines a framework for verifying that an algorithm for computing a posterior distribution has been implemented correctly. It is easy to use, straightforward to implement, and ready to be implemented as part of a Bayesian workflow. [latest version of the paper is here. — AG]
This type of testing should be required in order to publish a new (or improved) algorithm that claims to compute a posterior distribution. It’s time to get serious about only publishing things that actually work!
You Oughta Know
Before I go into our method, let’s have a brief review of some things that are not sufficient to demonstrate that an algorithm for computing a posterior distribution actually works.
- Theoretical results that are anything less than demonstrably tight upper and lower bounds* that work in finite-sample situations.
- Comparison with a long run from another algorithm unless that algorithm has stronger guarantees than “we ran it for a long time”. (Even when the long-running algorithm is guaranteed to work, there is nothing generalizable here. This can only ever show the algorithm works on a specific data set.)
- Recovery of parameters from simulated data (this literally checks nothing)
- Running the algorithm on real data. (Again, this checks literally nothing.)
- Running the algorithm and plotting traceplots, autocorrelation, etc etc etc
- Computing the Gelman-Rubin R-hat statistic. (Even using multiple chains initialized at diverse points, this only checks if the Markov Chain has converged. It does not check that it’s converged to the correct thing)
I could go on and on and on.
The method that we are proposing does actually do a pretty good job at checking if an approximate posterior is similar to the correct one. It isn’t magic. It can’t guarantee that a method will work for any data set.
What it can do is make sure that for a given model specification, one dimensional posterior quantities of interest will be correct on average. Here, “on average” means that we average over data simulated from the model. This means that rather than just check the algorithm once when it’s proposed, we need to check the algorithm every time it’s used for a new type of problem. This places algorithm checking within the context of Bayesian Workflow.
This isn’t as weird as it seems. One of the things that we always need to check is that we are actually running the correct model. Programming errors happen to everyone and this procedure will help catch them.
Moreover, if you’re doing something sufficiently difficult, it can happen that even something as stable as Stan will quietly fail to get the correct result. The Stan developers have put a lot of work into trying to avoid these quiet cases of failure (Betancourt’s idea to monitor divergences really helped here!), but there is no way to user-proof software. The Simulation-Based Calibration procedure that we outline in the paper (and below) is another safety check that we can use to help us be confident that our inference is actually working as expected.
(* I will also take asymptotic bounds and sensitive finite sample heuristics because I’m not that greedy. But if I can’t run my problem, check the heuristic, and then be confident that if someone died because of my inference, it would have nothing to do with the computaition of the posterior, then it’s not enough.)
Don’t call it a comeback, I’ve been here for years
One of the weird things that I have noticed over the years is that it’s often necessary to re-visit good papers from the past so they reflect our new understanding of how statistics works. In this case, we re-visited an excellent idea Samantha Cook, Andrew, and Don Rubin proposed in 2006.
Cook, Gelman, and Rubin proposed a method for assessing output from software for computing posterior distributions by noting a simple fact:
If $latex \theta^* \sim p(\theta)$ and $latex y^* \sim p(y \mid \theta^*)$, then the posterior quantile $latex \Pr(h(\theta^*)<h(\theta)\mid y^*)$ is uniformly distributed (the randomness is in $latex y^*$) for any continuous function $latex h(\cdot)$.
There’s a slight problem with this result. It’s not actually applicable for sample-based inference! It only holds if, at every point, all the distributions are continuous and all of the quantiles are computed exactly.
In particular, if you compute the quantile $latex \Pr(h(\theta^*)<h(\theta)\mid y^*)$ using a bag of samples drawn from an MCMC algorithm, this result will not hold.
This makes it hard to use the original method in practice. That might be down-weighting the problem. This whole project happened because we wanted to run Cook, Gelman and Rubin’s procedure to compare some Stan and BUGS models. And we just kept running into problems. Even when we ran it on models that we knew worked, we were getting bad results.
So we (Sean, Michael, Aki, Andrew, and I) went through and tried to re-imagine their method as something that is more broadly applicable.
When in doubt, rank something
The key difference between our paper and Cook, Gelman, and Rubin is that we have avoided their mathematical pitfalls by re-casting their main theoretical result to something a bit more robust. In particular, we base our method around the following result.
Let $latex \theta^* \sim p(\theta)$ and $latex y^* \sim p(y \mid \theta^*)$, and $latex \theta_1,\ldots,\theta_L$ be independent draws from the posterior distribution $latex p(\theta\mid y^*)$. Then the rank of $latex h(\theta^*)$ in the bag of samples $latex h(\theta_1),\ldots,h(\theta_L)$ has a discrete uniform distribution on $latex [0,L]$.
This result is true for both discrete and continuous distributions. On the other hand, we now have freedom to choose $latex L$. As a rule, the larger $latex L$, the more sensitive this procedure will be. On the other hand, a larger $latex L$ will require more simulated data sets in order to be able to assess if the observed ranks deviate from a discrete-uniform distribution. In the paper, we chose $latex L=100$ samples for each posterior.
The hills have eyes
But, more importantly, the hills have autocorrelation. If a posterior has been computed using an MCMC method, the bag of samples that are produced will likely have non-trivial autocorrelation. This autocorrelation will cause the rank histogram to deviate from uniformity in a specific way. In particular, it will lead to spikes in the histogram at zero and/or one.
To avoid this, we recommend thinning the sample to remove most of the autocorrelation. In our experiments, we found that thinning by effective sample size was sufficient to remove the artifacts, even though this is not theoretically guaranteed to remove the autocorrelation. We also considered using some more theoretically motivated methods, such as thinning based on Geyer’s initial positive sequences, but we found that these thinning rules were too conservative and this more aggressive thinning did not lead to better rank histograms than the simple effective sample size-based thinning.
Simulation based calibration
After putting all of this together, we get the simulation based calibration (SBC) algorithm. The below version is for correlated samples. (There is a version in the paper for independent samples).

The simple idea is that each of the $latex N$ simulated datasets, you generate a bag of $latex L$ approximately independent samples from the approximate posterior. (You can do this however you want!) You then compute the rank of the true parameter (that was used in the simulation of the data set) within the bag of samples. So you need to compute $latex N$ true parameters, each of which is used to compute one data set, which is used to compute $latex L$ samples from its posterior.
So. Validating code with SBC is obviously expensive. It requires a whole load of runs to make it work. The up side is that all of this runs in parallel on a cluster, so if your code is reliable, it is actually quite straightforward to run.
The place where we ran into some problems was trying to validate MCMC code that we knew didn’t work. In this case, the autocorrelation on the chain was so strong that it wasn’t reasonable to thin the chain to get 100 samples. This is an important point: if your method fails some basic checks, then it’s going to fail SBC. There’s no point wasting your time.
The main benefit of SBC is in validating MCMC methods that appear to work, or validating fast approximate algorithms like INLA (which works) or ADVI (which is a more mixed bag).
This method also has another interesting application: evaluating approximate models. For example, if you replace an intractable likelihood with a cheap approximation (such as a composite likelihood or a pseudolikelihood), SBC can give some idea of the errors that this approximation has pushed into the posterior. The procedure remains the same: simulate parameters from the prior, simulate data from the correct model, and then generate a bag of approximately uncorrelated samples from corresponding posterior using the approximate model. While this procedure cannot assess the quality of the approximation in the presence of model error, it will still be quite informative.
When You’re Smiling (The Whole World Smiles With You)
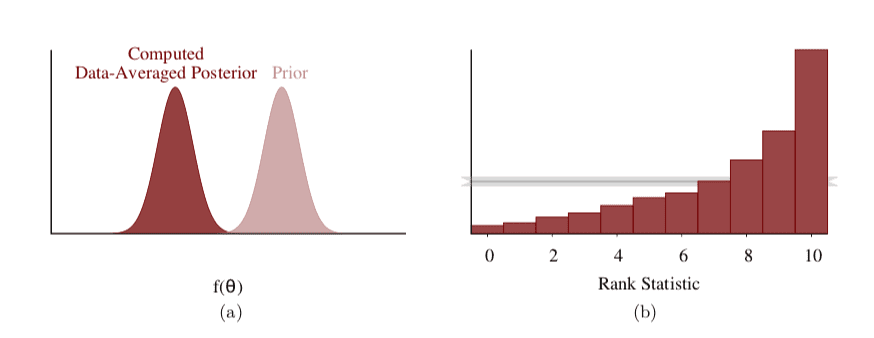


One of the most useful parts of the SBC procedure is that it is inherently visual. This makes it fairly straightforward to work out how your algorithm is wrong. The one-dimensional rank histograms have four characteristic non-uniform shapes: “smiley”, “frowny”, “a step to the left”, “a jump to the right”, which are all interpretable.
- Histogram has a smile: The posteriors are narrower than they should be. (We see too many low and high ranks)
- Histogram has a frown: The posteriors are wider than they should be. (We don’t see enough low and high ranks)
- Histogram slopes from left to right: The posteriors are biased upwards. (The true value is too often in the lower ranks of the sample)
- Histogram slopes from right to left: The posteriors are biased downwards. (The opposite)
These histograms seem to be sensitive enough to indicate when an algorithm doesn’t work. In particular, we’ve observed that when the algorithm fails, these histograms are typically quite far from uniform. A key thing that we’ve had to assume, however, is that the bag of samples drawn from the computed posterior is approximately independent. Autocorrelation can cause spurious spikes at zero and/or one.
These interpretations are inspired by the literature on calibrating probabilistic forecasts. (Follow that link for a really detailed review and a lot of references). There are also some multivariate extensions to these ideas, although we have not examined them here.
“Don’t call it a comeback, I’ve been here for years”
Should you not be familiar with it, and care about this sort of thing, Eagle-Eye Cherry made a sweet cover of LL cool J’s “Mama said knock you out” (which i think is where you got the “don’t call it a comeback, i’ve been here for years” from ?)
https://www.youtube.com/watch?v=S609LUs1GEM
Cool! I was using a simplified version of the Cook-Gelman-Rubin method for a while (checking that X% of simulations have the true param in X% posterior interval where X in {25,50,95}) and it saved me a lot of trouble so far. Switching to this method should be easy and I am glad someone did the hardwork of actually thinking it through!
“Recovery of parameters from simulated data (this literally checks nothing)
Running the algorithm on real data. (Again, this checks literally nothing.)”
Not to be nitpick, but that’s just not true. It’s certainly true that *alone* does not validate that your sampling algorithm is correct, but a lot of bugs are caught with *both* these procedures. The number of peer-reviewed algorithms that out-and-out fail on most of the available real datasets is surprisingly high (of course, they tend not to gain much popularity). This can be as simple as failing when there are ties in the data; never happens with continuous simulated data, very frequently happens with real data!
The reason this is a nitpick worth having is that I don’t believe the proposed methods are “100% validation” that the samples approximate the posterior, and you claim that’s not true either. So it’s a bit disingenuous to say “these methods do nothing” when, in fact, they would be helpful for catching certain bugs that seem to show up more than they should. Both these methods can catch a percentage of issues, and, empirically, the “Running the algorithm on real data” percentage is much higher than we care to admit sometimes!
I take your point about ties and detecting structural problems, but running an algorithm on real data doesn’t tell you anything about whether the algorithm is computing what it’s supposed to compute. It is quite possible that the algorithm is faithfully reproducing a model that doesn’t fit the data.
If the reference was to Rocky Horror, it should be amended as “it’s just a jump to the left, then a step to the right“.
It would be intriguing if you could find histograms that resembled putting one’s hand on one’s hip, or pulling one’s knees in tight…
Hi Dan,
I wonder if you have any video lectures available? It interesting to see how your style of presentation works in life performance.
“The up side is that all of this runs in parallel on a cluster, so if your code is reliable, it is actually quite straightforward to run.” — Sounds good. Have you already developed an SBC software that can automatically run the validation tests of an arbitrary generative Stan model?
There is Python code to do this in the github repo associated with the paper: https://github.com/seantalts/simulation-based-calibration
I’m trying to follow the logic about thinning.
Am I right that thinning is almost a red herring, and that the main problem is insufficient effective sample size? In other words, I think the key is to run for long enough, and that the main reason to thin while you’re doing that is efficiency – that if you have a large-enough effective sample size, the auto-correlation shouldn’t hurt you.
I’m not saying we shouldn’t thin, I’m saying I’m confused by the claim that thinning (and removing autocorrelation) is necessary.
Jonathan:
The point of thinning here is that it simplifies the joint distribution of the posterior simulations, making them close to independent, which makes it easier to understand the properties of the statistics comparing the true values of the parameters to the posterior simulations.
Im still missing the point here…
Lets say I run my MCMC for 10000 samples, and my true parameter is ranked at 13% (15% of samples are lover than the true, 87% are higher).
Now of I thin these samples to 100, may true parameter still should be ranked at about 13%, should it? So what is the gain?
Mikhail:
See here.
Also a good point. In other words, not only is there a danger that your sample size would be insufficient, there’s also the practical problem of not really knowing what it is.
Is the preprint published yet? It’s hard to get grumpy about people not using these methods if they’re not peer-reviewed :-)
Jonathan:
I added a link to the latest version of the paper. It will never be published, but we have a new paper that moves the ideas forward, and we’ll be submitting that to a journal soon, so it should eventually be peer reviewed and published.
It’s still had some influence, though: according to Google Scholar, it’s my third-most cited unpublished paper!
Thanks