Some weeks ago, I posted in Mastodon (you can follow me there) a thread about “How big problem it is that cross-validation is biased?”. I have also added that text to CV-FAQ. Today I extended that thread as we have a new paper out on estimating and correcting selection induced bias in cross-validation model selection.
I’m posting here the whole thread for the convenience of those who are not (yet?) following me in Mastodon:
Unbiasedness has a special role in statistics, and too often there are dichotomous comments that something is not valid or is inferior because it’s not unbiased. However, often the non-zero bias is negligible, and often by modifying the estimator we may even increase bias but reduce the variance a lot, providing an overall improved performance.
In CV the goal is to estimate the predictive performance for unobserved data given the observed data of size n. CV has pessimistic bias due to using less than n observation to fit the models. In case of LOO-CV this bias is usually small and negligible. In case of K -fold-CV with a small K, the bias can be non-negligible, but if the effective number of parameters of the model is much less than n, then with K>10 the bias is also usually negligible compared to the variance.
There is a bias correction approach by Burman (1989) (see also Fushiki (2011)) that reduces CV bias, but even in the cases with non-negligible bias reduction, the variance tends to increase so much that there is no real benefit (see, e.g. Vehtari and Lampinen (2002)).
For time series when the task is to predict future (there are other possibilities like missing data imputation) there are specific CV methods such as leave-future-out (LFO) that have lower bias than LOO-CV or K -fold-CV (Bürkner, Gabry and Vehtari, 2020). There are sometimes comments that LOO-CV and K -fold-CV would be invalid for time series. Although they tend to have a bigger bias than LFO, they are still valid and can be useful, especially in model comparison where bias can cancel out.
Cooper et al. (2023) demonstrate how in time series model comparison variance is likely to dominate, it is more important to reduce the variance than bias, and leave-few-observations and use of joint log score is better than use of LFO. The problem with LFO is that the data sets used for fitting models are smaller, increasing the variance.
Bengio and Grandvalet (2004) proved that there is no unbiased estimate for the variance of CV in general, which has been later used as an argument that there is no hope. Instead of dichotomizing to unbiased or biased, Sivula, Magnusson and Vehtari (2020) consider whether the variance estimates are useful and how to diagnose when the bias is likely to not be negligible (Sivula, Magnusson and Vehtari (2023) prove also a special case where there actually exists unbiased variance estimate).
CV tends to have high variance, as the sample reuse is not making any modeling assumptions (this holds also for information criteria such as WAIC). Not making modeling assumptions is good when we don’t trust our models, but if we trust we can get reduced variance in model comparison, for example, examining directly the posterior or using reference models to filter out noise in the data (see, e.g., Piironen, Paasiniemi and Vehtari (2018) and Pavone et al. (2020)).
When using CV (or information criteria such as WAIC) for model selection, the performance estimate for the selected model has additional selection induced bias. In case of small number of models this bias is usually negligible, that is, smaller than the standard deviation of the estimate or smaller than what is practically relevant. In case of negligible bias, we may choose suboptimal model, but the difference to the performance of oracle model is small.
In case of a large number of models the selection induced bias can be non-negligible, but this bias can be estimated using, for example, nested-CV or bootstrap. The concept of the selection induced bias and related potentially harmful overfitting are not new concepts, but there hasn’t been enough discussion when they are negligible or non-negligible.
In our new paper with Yann McLatchie Efficient estimation and correction of selection-induced bias with order statistics we review the concepts of selection-induced bias and overfitting, propose a fast to compute estimate for the bias, and demonstrate how this can be used to avoid selection induced overfitting even when selecting among 10^30 models.
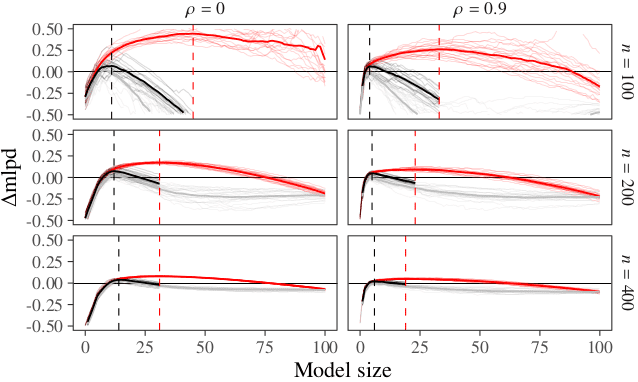
The figure here shows simulation results with p=100 covariates, with different data sizes n, and varying block correlation among the covariates. The red lines show the LOO-CV estimate for the best model chosen so far in forward-search. The grey lines show the independent, much bigger test data performance, which usually don’t have available. The black line shows our corrected estimate taking into account the selection induced bias. Stopping the searches at the peak of black curves avoids overfitting.
Although we can estimate and correct the selection induced bias, we primarily recommend to use more sensible priors and not to do model selection. See more in Efficient estimation and correction of selection-induced bias with order statistics and Bayesian Workflow.