As a European, I’ve always been fascinated by how trivial and common-sense matters end up in courts. I’ve been less fascinated and more annoyed by the piles of forms and disclaimers everywhere. Finally, annoyance takes over any kind of fascination faced with the medical bills – often so high because of lawsuit-protecting insurance. As Paul H. Rubin writes in NY Times:
The United States is already the most litigious society in the world. We spend about 2.2 percent of gross domestic product, roughly $310 billion a year, or about $1,000 for each person in the country on tort litigation, much higher than any other country. This includes the costs of tort litigation and damages paid to victims. About half of this total is for transactions costs — mostly legal fees.
So why is that? One way to explore that is to examine the composition of the US Congress, as BusinessWeek has done a few years ago:
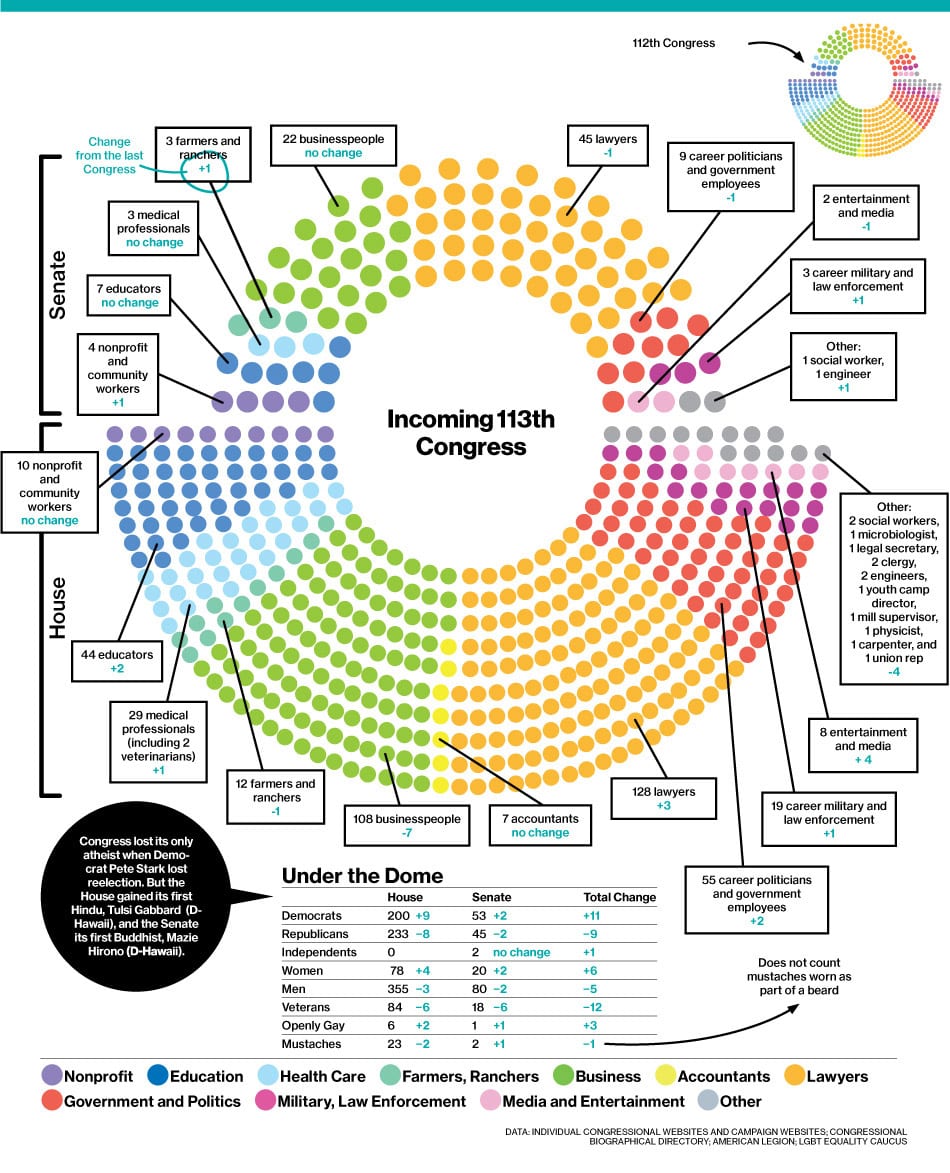
Law is the profession that’s best represented in the US Congress. How do lawyers vote compared to other professions? I’ve worked on quantitative analysis of voting behavior in US Senate a few years ago, so this is a pet interest of mine. I was thus interested to receive an email from two Swiss researchers summarizing their research:
In a study recently published in the Journal of Law and Economics (working paper version available here), Ulrich Matter and Alois Stutzer investigate the role of lawyer-legislators in shaping the law. The focus of their study lies particularly on legislators with a professional background as attorney (and not on the legislators’ education per se). In order to code the occupational backgrounds of all US Congressmen and all US state legislators over several years, the authors assembled a data set with detailed biographical information drawn from Project Vote Smart and compiled via its application programming interface (an R package that facilitates the compilation of such data is available here). The biographical information is then linked to the legislators’ voting records in the context of tort law reform at the federal and state level between 1995 and 2014.
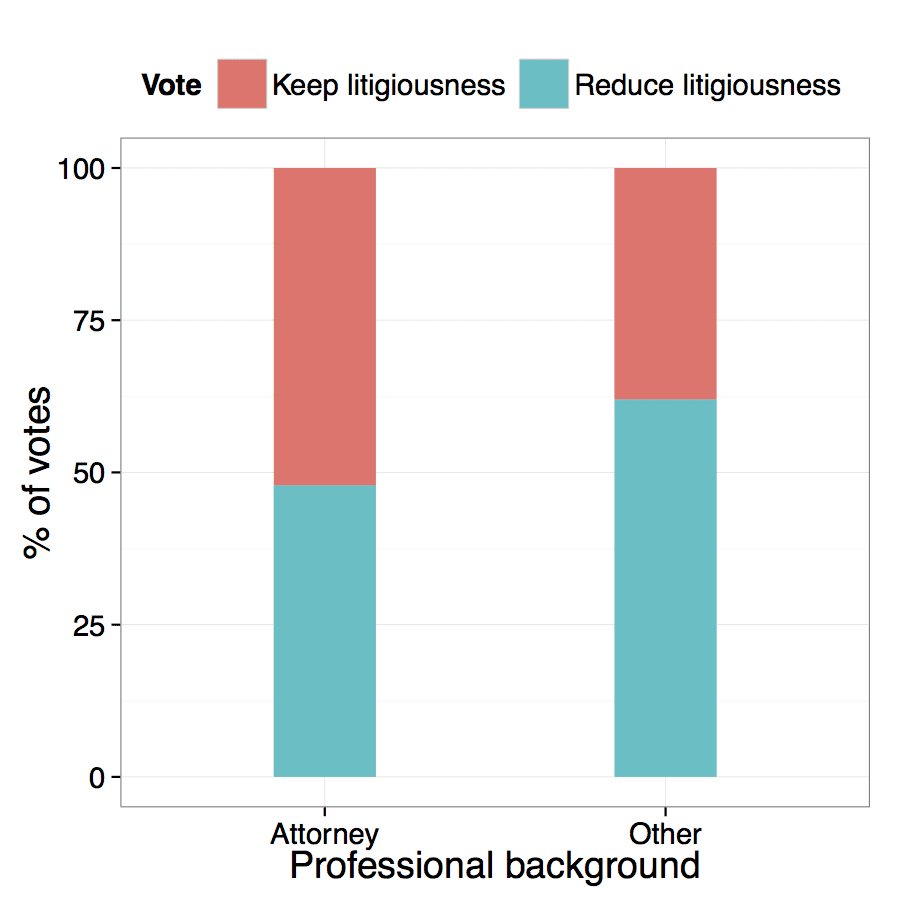
The theoretical consideration is that lawyer-legislators can, by deciding on statutory law, affect the very basis of their business and that this is particularly the case for tort law. A look at the raw data (figure below) indicates that lawyer-legislators are less likely to support reforms that restrict tort law than legislators with a different professional background.
This holds when controlling for other factors in regression analyses. For bills aiming at increasing tort liability the pattern switches and lawyer-legislators are more likely to vote in favor of bills that extend tort law than legislators with a different professional background.
Overall, the findings are consistent with the hypothesis that lawyer-legislators, at least in part, pursue their private interests when voting on tort issues. From a broader perspective, the results highlight the relevance of legislators’ identities and individual professional interests for economic policy making.
I can imagine other professions in the Congress engaging in similar protectionism of an imperfect status quo in their respective fields. It’s access to data and statistics that facilitate this necessary scrutiny in analyzing conscious and unconscious biases of legislators.











![http://coastwatch.pfeg.noaa.gov/erddap/griddap/erdBAsstamday.png?sst[(2010-01-16T12:00:00Z):1:(2010-01-16T12:00:00Z)][(0.0):1:(0.0)][(30):1:(50.0)][(220):1:(240.0)]](http://coastwatch.pfeg.noaa.gov/erddap/griddap/erdBAsstamday.png?sst[(2010-01-16T12:00:00Z):1:(2010-01-16T12:00:00Z)][(0.0):1:(0.0)][(30):1:(50.0)][(220):1:(240.0)]){kind=link}