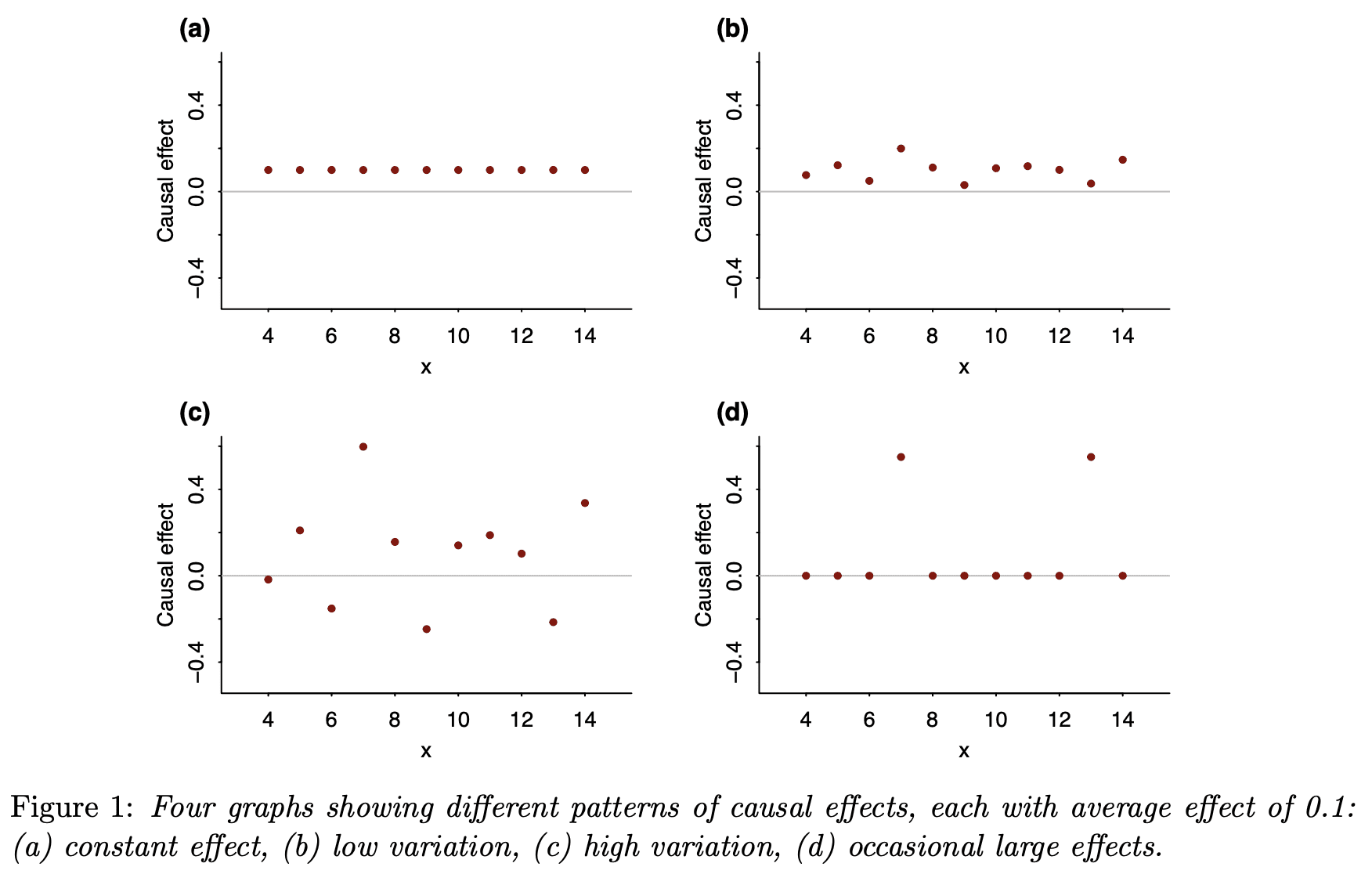
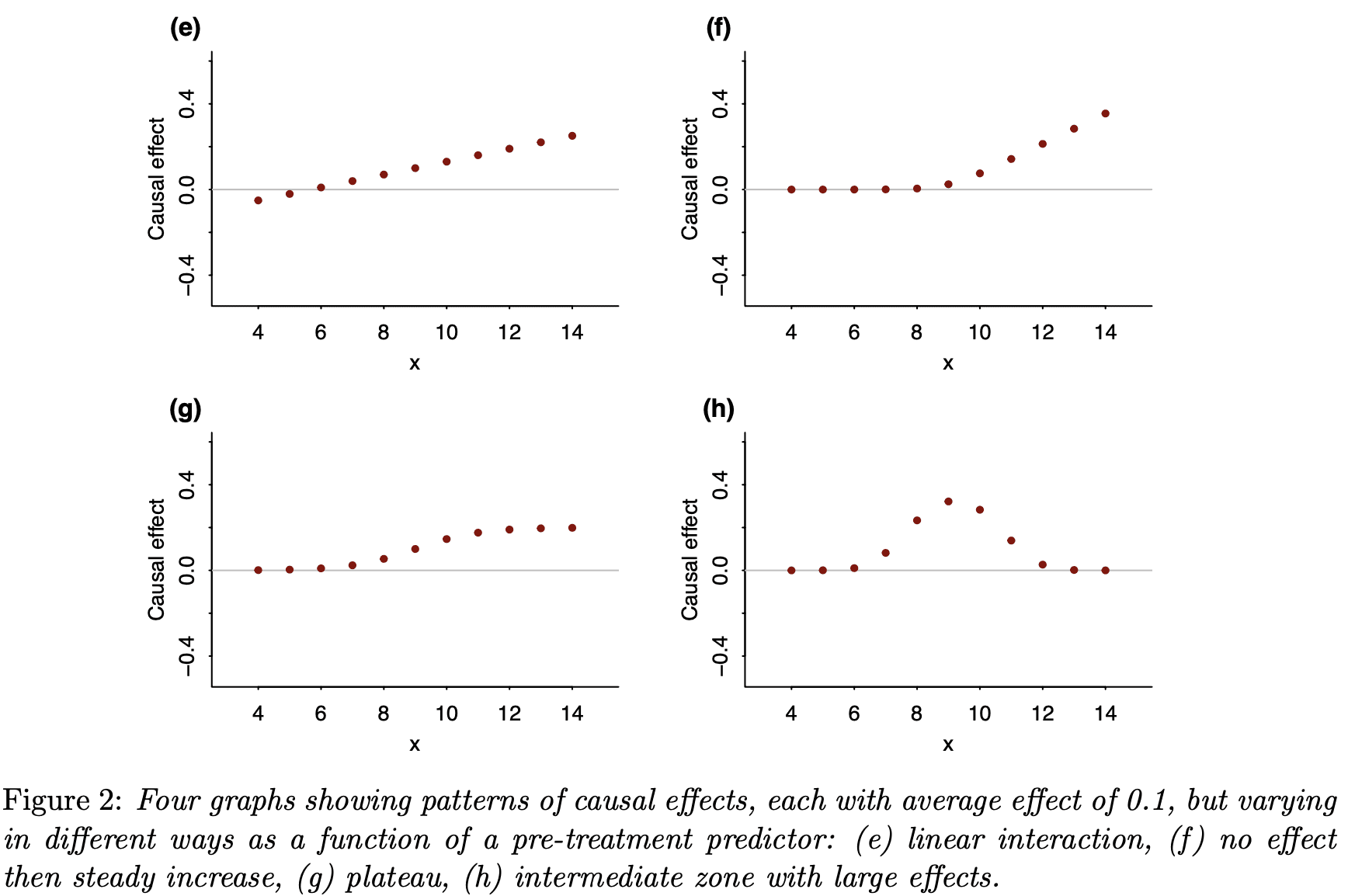
Last year I wrote about the value of testing observable consequences of a randomized experiment having occurred as planned. For example, if the randomization was supposedly Bernoulli(1/2), you can check that the number of units in treatment and control in the analytical sample isn’t so inconsistent with that; such tests are quite common in the tech industry. If you have pre-treatment covariates, then it can also make sense to test that they are not wildly inconsistent with randomization having occurred as planned. The point here is that things can go wrong in the treatment assignment itself or in how data is recorded and processed downstream. We are not checking whether our randomization perfectly balanced all of the covariates. We are checking our mundane null hypothesis that, yes, the treatment really was randomized as planned. Even if there is just a small difference in proportion treated or a small imbalance in observable covariates, if this is high statistically significant (say, p < 1e-5), then we should likely revise our beliefs. We might be able to salvage the experiment if, say, some observations were incorrectly dropped (one can also think of this as harmless attrition not being so harmless after all).
The argument against doing or at least prominently reporting these tests is that they can confuse readers and can also motivate “garden of forking paths” analyses with different sets of covariates than planned. I recently encountered some of these challenges in the wild. Because of open peer review processes, I can give a view into the peer review process for the paper where this came up.
I was a peer reviewer for this paper, “Communicating doctors’ consensus persistently increases COVID-19 vaccinations”, now published in Nature. It is an impressive experiment embedded in a multi-wave survey in the Czech Republic. The intervention provides accurate information about doctors’ trust in COVID-19 vaccines, which people perceived to be lower than it really was. (This is related to some of our own work on people’s beliefs about others’ vaccination intentions.) The paper presents evidence that this increased vaccination:
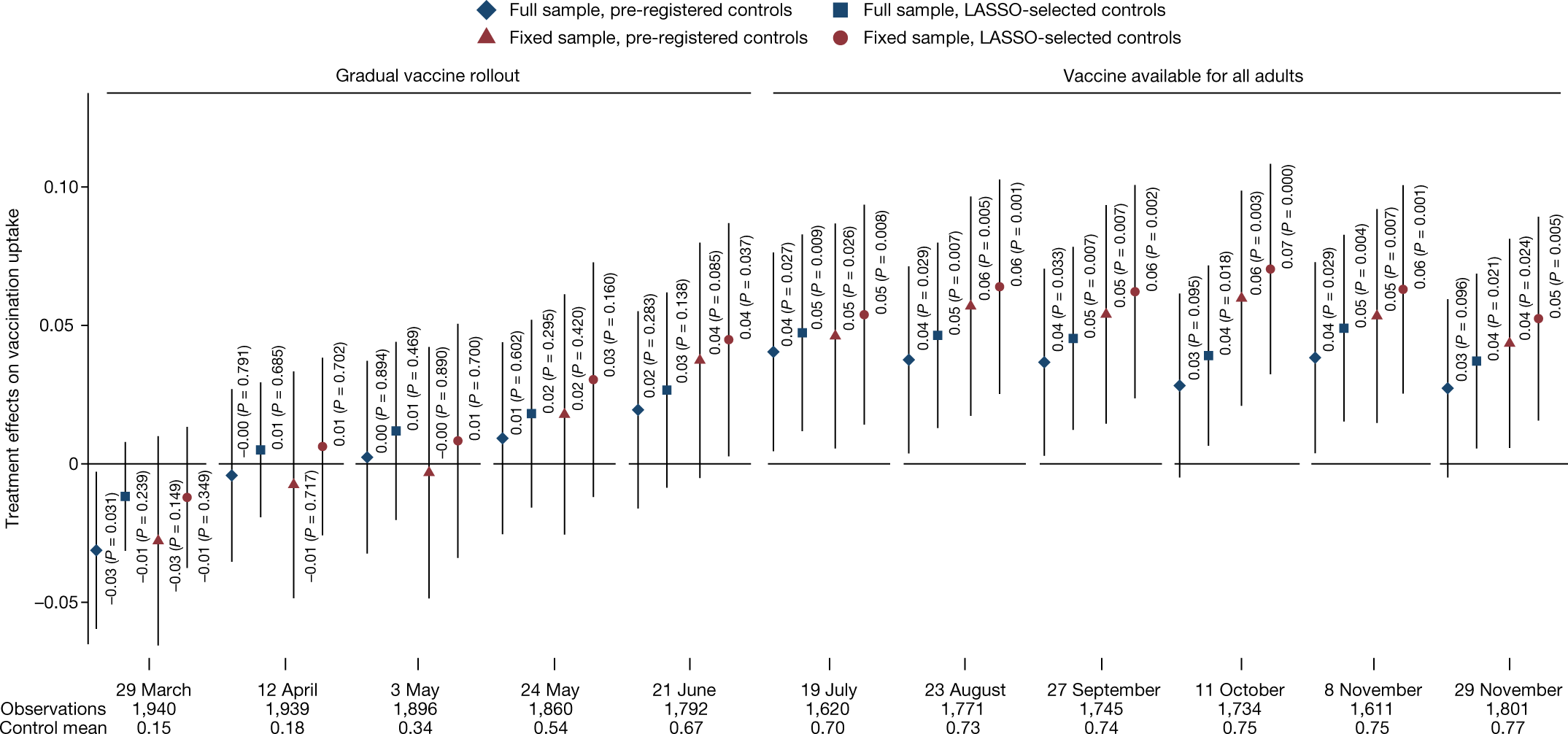
This figure (Figure 4 from the published version of the paper) shows the effects by wave of the survey. Not all respondents participated in each wave, so this creates the “full sample”, which includes a varying set of people over time, while the “fixed sample” includes only those who are in all waves. More immediately relevant, there are two sets of covariates used here: a pre-registered set and a set selected using L1-penalized regression.
This differs from a prior version of the paper, which actually didn’t report the preregistered set, motivated by concerns about imbalance of covariates that hadn’t been left out of that set. In my first peer review report, I wrote:
Contrary to the pre-analysis plan, the main analyses include adjustment for some additional covariates: “a non-pre-specified variable for being vaccinated in Wave0 and Wave0 beliefs about the views of doctors. We added the non-specified variables due to a detected imbalance in randomization.” (SI p. 32)
These indeed seem like relevant covariates to adjust for. However, this kind of data-contingent adjustment is potentially worrying. If there were indeed a problem with randomization, one would want to get to the bottom of that. But I don’t see much evidence than anything was wrong; it is simply the case that there is a marginally significant imbalance (.05 < p < .1) in two covariates and a non-significant (p > .1) imbalance in another — without any correction for multiple hypothesis testing. This kind of data-contingent adjustment can increase error rates (e.g., Mutz et al. 2019), especially if no particular rule is followed, creating a “garden of forking paths” (Gelman & Loken 2014). Thus, unless the authors actually think randomization did not occur as planned (in which case perhaps more investigation is needed), I don’t see why these variables should be adjusted for in all main analyses. (Note also that there is no single obvious way to adjust for these covariates. The beliefs about doctors are often discussed in a dichotomous way, e.g., “Underestimating” vs “Overestimating” trust so one could imagine the adjustment being for that dichotomized version additionally or instead. This helps to create many possible specifications, and only one is reported.) … More generally, I would suggest reporting a joint test of all of these covariates being randomized; presumably this retains the null.
This caused the authors to include the pre-registered analyses (which gave similar results) and to note, based on a joint test, that there weren’t “systematic” differences between treatment and control. Still I remained worried that the way they wrote about the differences in covariates between treatment and control invited misplaced skepticism about the randomization:
Nevertheless, we note that three potentially important but not pre-registered variables are not perfectly balanced. Since these three variables are highly predictive of vaccination take-up, not controlling for them could potentially bias the estimation of treatment effects, as is also indicated by the LASSO procedure, which selects these variables among a set of variables that should be controlled for in our estimates.
In my next report, while recommending acceptance, I wrote:
First, what does “not perfectly balanced” mean here? My guess is that all of the variables are not perfectly balanced, as perfect balance would be having identical numbers of subjects with each value in treatment and control, and would typically only be achieved in the blocked/stratified randomization.
Second, in what sense is does this “bias the estimation of treatment effects”? On typical theoretical analyses of randomized experiments, as long as we believe randomization occurred as planned, error due to random differences between groups is not bias; it is *variance* and is correctly accounted for in statistical inference.
This is also related to Reviewer 3’s review [who in the first round wrote “There seems to be an error of randomization on key variables”]. I think it is important for the authors to avoid the incorrect interpretation that something went wrong with their randomization. All indications are that it occurred exactly as planned. However, there can be substantial precision gains from adjusting for covariates, so this provides a reason to prefer the covariate-adjusted estimates.
If I was going to write this paragraph, I would say something like: Nevertheless, because the randomization was not stratified (i.e. blocked) on baseline covariates, there are random imbalances in covariates, as expected. Some of the larger differences are variables that were not specified in the pre-registered set of covariates to use for regression adjustment: (stating the covariates, I might suggest reporting standardized differences, not p-values here).
Of course, the paper is the authors’ to write, but I would just advise that unless they have a reason to believe the randomization did not occur as expected (not just that there were random differences in some covariates), they should avoid giving readers this impression.
I hope this wasn’t too much of a pain for the authors, but I think the final version of the paper is much improved in both (a) reporting the pre-registered analyses (as well as a bit of a multiverse analysis) and (b) not giving readers the incorrect impression there is any substantial evidence that something was wrong in the randomization.
So overall this experience helped me fully appreciate the perspective of Stephen Senn and other methodologists in epidemiology, medicine, and public health that reporting these per-covariate tests can lead to confusion and even worse analytical choices. But I think this is still consistent with what I proposed last time.
I wonder what you all think of this example. It’s also an interesting chance to get other perspectives on how this review and revision process unfolded and on my reviews.
P.S. Just to clarify, it will often make sense to prefer analyses of experiments that adjust for covariates to increase precision. I certainly use those analyses in much of my own work. My point here was more that finding noisy differences in covariates between conditions is not a good reason to change the set of adjusted-for variables. And, even if many readers might reasonably ex ante prefer an analysis that adjusts for more covariates, reporting such an analysis and not reporting the pre-registered analysis is likely to trigger some appropriate skepticism from readers. Furthermore, citing very noisy differences in covariates between conditions is liable to confuse readers and make them think something is wrong with the experiment. Of course, if there is strong evidence against randomization having occurred as planned, that’s notable, but simply adjusting for observables is not a good fix.
[This post is by Dean Eckles.]