1. When can we trust? How can we navigate social science with skepticism?
2. Why I’m not convinced by that Quebec child-care study
3. 20 years on
1. When can we trust? How can we navigate social science with skepticism?
The other day I happened to run across a post from 2016 that I think is still worth sharing.
Here’s the background. Someone pointed me to a paper making the claim that “Canada’s universal childcare hurt children and families. . . . the evidence suggests that children are worse off by measures ranging from aggression to motor and social skills to illness. We also uncover evidence that the new child care program led to more hostile, less consistent parenting, worse parental health, and lower‐quality parental relationships.”
I looked at the paper carefully and wasn’t convinced. In short, the evidence went in all sorts of different directions, and I felt that the authors had been trying too hard to fit it all into a consistent story. It’s not that the paper had fatal flaws—it was not at all in the category of horror classics such as the beauty-and-sex-ratio paper, the ESP paper, the himmicanes paper, the air-rage paper, the pizzagate papers, the ovulation-and-voting paper, the air-pollution-in-China paper, etc etc etc.—it just didn’t really add up to me.
The question then is, if a paper can appear in a top journal, have no single killer flaw but still not be convincing, can we trust anything at all in the social sciences? At what point does skepticism become nihilism? Must I invoke the Chestertonian principle on myself?
I don’t know.
What I do think is that the first step is to carefully assess the connection between published claims, the analysis that led to these claims, and the data used in the analysis. The above-discussed paper has a problem that I’ve seen a lot, which is an implicit assumption that all the evidence should go in the same direction, a compression of complexity which I think is related to the cognitive illusion that Tversky and Kahneman called “the law of small numbers.” The first step in climbing out of this sort of hole is to look at lots of things at once, rather than treating empirical results as a sort of big bowl of fruit where the researcher can just pick out the the juiciest items and leave the rest behind.
2. Why I’m not convinced by that Quebec child-care study
Here’s what I wrote on that paper back in 2006:
Yesterday we discussed the difficulties of learning from a small, noisy experiment, in the context of a longitudinal study conducted in Jamaica where researchers reported that an early-childhood intervention program caused a 42%, or 25%, gain in later earnings. I expressed skepticism.
Today I want to talk about a paper making an opposite claim: “Canada’s universal childcare hurt children and families.”
I’m skeptical of this one too.
Here’s the background. I happened to mention the problems with the Jamaica study in a talk I gave recently at Google, and afterward Hal Varian pointed me to this summary by Les Picker of a recent research article:
In Universal Childcare, Maternal Labor Supply, and Family Well-Being (NBER Working Paper No. 11832), authors Michael Baker, Jonathan Gruber, and Kevin Milligan measure the implications of universal childcare by studying the effects of the Quebec Family Policy. Beginning in 1997, the Canadian province of Quebec extended full-time kindergarten to all 5-year olds and included the provision of childcare at an out-of-pocket price of $5 per day to all 4-year olds. This $5 per day policy was extended to all 3-year olds in 1998, all 2-year olds in 1999, and finally to all children younger than 2 years old in 2000.
(Nearly) free child care: that’s a big deal. And the gradual rollout gives researchers a chance to estimate the effects of the program by comparing children at each age, those who were and were not eligible for this program.
The summary continues:
The authors first find that there was an enormous rise in childcare use in response to these subsidies: childcare use rose by one-third over just a few years. About a third of this shift appears to arise from women who previously had informal arrangements moving into the formal (subsidized) sector, and there were also equally large shifts from family and friend-based child care to paid care. Correspondingly, there was a large rise in the labor supply of married women when this program was introduced.
That makes sense. As usual, we expect elasticities to be between 0 and 1.
But what about the kids?
Disturbingly, the authors report that children’s outcomes have worsened since the program was introduced along a variety of behavioral and health dimensions. The NLSCY contains a host of measures of child well being developed by social scientists, ranging from aggression and hyperactivity, to motor-social skills, to illness. Along virtually every one of these dimensions, children in Quebec see their outcomes deteriorate relative to children in the rest of the nation over this time period.
More specifically:
Their results imply that this policy resulted in a rise of anxiety of children exposed to this new program of between 60 percent and 150 percent, and a decline in motor/social skills of between 8 percent and 20 percent. These findings represent a sharp break from previous trends in Quebec and the rest of the nation, and there are no such effects found for older children who were not subject to this policy change.
Also:
The authors also find that families became more strained with the introduction of the program, as manifested in more hostile, less consistent parenting, worse adult mental health, and lower relationship satisfaction for mothers.
I just find all this hard to believe. A doubling of anxiety? A decline in motor/social skills? Are these day care centers really that horrible? I guess it’s possible that the kids are ruining their health by giving each other colds (“There is a significant negative effect on the odds of being in excellent health of 5.3 percentage points.”)—but of course I’ve also heard the opposite, that it’s better to give your immune system a workout than to be preserved in a bubble. They also report “a policy effect on the treated of 155.8% to 394.6%” in the rate of nose/throat infection.
OK, hre’s the research article.
The authors seem to be considering three situations: “childcare,” “informal childcare,” and “no childcare.” But I don’t understand how these are defined. Every child is cared for in some way, right? It’s not like the kid’s just sitting out on the street. So I’d assume that “no childcare” is actually informal childcare: mostly care by mom, dad, sibs, grandparents, etc. But then what do they mean by the category “informal childcare”? If parents are trading off taking care of the kid, does this count as informal childcare or no childcare? I find it hard to follow exactly what is going on in the paper, starting with the descriptive statistics, because I’m not quite sure what they’re talking about.
I think what’s needed here is some more comprehensive organization of the results. For example, consider this paragraph:
The results for 6-11 year olds, who were less affected by this policy change (but not unaffected due to the subsidization of after-school care) are in the third column of Table 4. They are largely consistent with a causal interpretation of the estimates. For three of the six measures for which data on 6-11 year olds is available (hyperactivity, aggressiveness and injury) the estimates are wrong-signed, and the estimate for injuries is statistically significant. For excellent health, there is also a negative effect on 6-11 year olds, but it is much smaller than the effect on 0-4 year olds. For anxiety, however, there is a significant and large effect on 6-11 year olds which is of similar magnitude as the result for 0-4 year olds.
The first sentence of the above excerpt has a cover-all-bases kind of feeling: if results are similar for 6-11 year olds as for 2-4 year olds, you can go with “but not unaffected”; if they differ, you can go with “less effective.” Various things are pulled out based on whether they are statistically significant, and they never return to the result for anxiety, which would seem to contradict their story. Instead they write, “the lack of consistent findings for 6-11 year olds confirm that this is a causal impact of the policy change.” “Confirm” seems a bit strong to me.
The authors also suggest:
For example, higher exposure to childcare could lead to increased reports of bad outcomes with no real underlying deterioration in child behaviour, if childcare providers identify negative behaviours not noticed (or previously acknowledged) by parents.
This seems like a reasonable guess to me! But the authors immediately dismiss this idea:
While we can’t rule out these alternatives, they seem unlikely given the consistency of our findings both across a broad spectrum of indices, and across the categories that make up each index (as shown in Appendix C). In particular, these alternatives would not suggest such strong findings for health-based measures, or for the more objective evaluations that underlie the motor-social skills index (such as counting to ten, or speaking a sentence of three words or more).
Health, sure: as noted above, I can well believe that these kids are catching colds from each other.
But what about that motor-skills index? Here are their results from the appendix:

I’m not quite sure whether + or – is desirable here, but I do notice that the coefficients for “can count out loud to 10” and “spoken a sentence of 3 words or more” (the two examples cited in the paragraph above) go in opposite directions. That’s fine—the data are the data—but it doesn’t quite fit their story of consistency.
More generally, the data are addressed in an scattershot manner. For example:
We have estimated our models separately for those with and without siblings, finding no consistent evidence of a stronger effect on one group or another. While not ruling out the socialization story, this finding is not consistent with it.
This appears to be the classic error of interpretation of a non-rejection of a null hypothesis.
And here’s their table of key results:
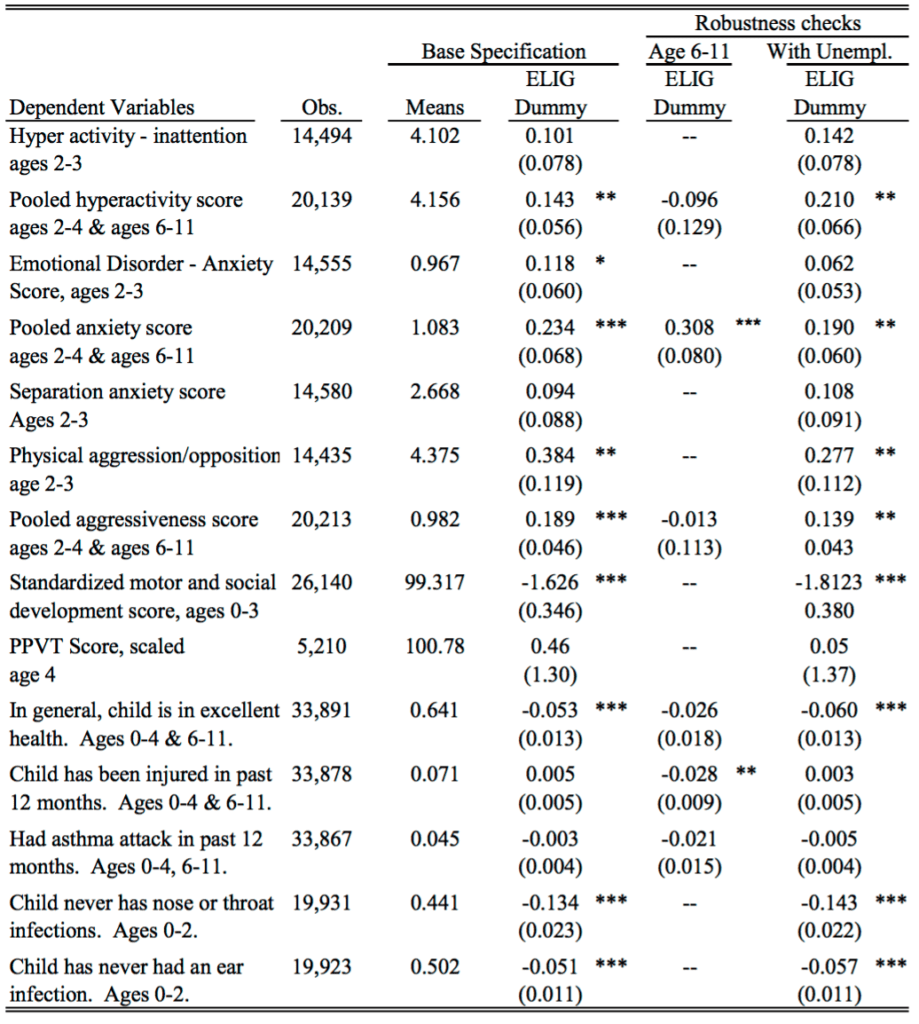
As quantitative social scientists we need to think harder about how to summarize complicated data with multiple outcomes and many different comparisons.
I see the current standard ways to summarize this sort of data are:
(a) Focus on a particular outcome and a particular comparison (choosing these ideally, though not usually, using preregistration), present that as the main finding and then tag all else as speculation.
Or, (b) Construct a story that seems consistent with the general pattern in the data, and then extract statistically significant or nonsignificant comparisons to support your case.
Plan (b) was what was done again, and I think it has problems: lots of stories can fit the data, and there’s a real push toward sweeping any anomalies aside.
For example, how do you think about that coefficient of 0.308 with standard error 0.080 for anxiety among the 6-11-year-olds? You can say it’s just bad luck with the data, or that the standard error calculation is only approximate and the real standard error should be higher, or that it’s some real effect caused by what was happening in Quebec in these years—but the trouble is that any of these explanations could be used just as well to explain the 0.234 with standard error 0.068 for 2-4-year-olds, which directly maps to one of their main findings.
Once you start explaining away anomalies, there’s just a huge selection effect in which data patterns you choose to take at face value and which you try to dismiss.
So maybe approach (a) is better—just pick one major outcome and go with it? But then you’re throwing away lots of data, that can’t be right.
I am unconvinced by the claims of Baker et al., but it’s not like I’m saying their paper is terrible. They have an identification strategy, and clean data, and some reasonable hypotheses. I just think their statistical analysis approach is not working. One trouble is that statistics textbooks tend to focus on stand-alone analyses—getting the p-value right, or getting the posterior distribution, or whatever, and not on how these conclusions fit into the big picture. And of course there’s lots of talk about exploratory data analysis, and that’s great, but EDA is typically not plugged into issues of modeling, data collection, and inference.
What to do?
OK, then. Let’s forget about the strengths and the weaknesses of the Baker et al. paper and instead ask, how should one evaluate a program like Quebec’s nearly-free preschool? I’m not sure. I’d start from the perspective of trying to learn what we can from what might well be ambiguous evidence, rather than trying to make a case in one direction or another. And lots of graphs, which would allow us to see more in one place, that’s much better than tables and asterisks. But, exactly what to do, I’m not sure. I don’t know whether the policy analysis literature features any good examples of this sort of exploration. I’d like to see something, for this particular example and more generally as a template for program evaluation.
3. Nearly 20 years on
So here’s the story. I heard about this work in 2016, from a press release issued in 2006, the article was published in a top economics journal in 2008, it appeared in preprint form in 2005, and it was based on data collected in the late 1990s. And here we are discussing it again in 2023.
It’s kind of beating a dead horse to discuss a 20-year-old piece of research, but you know what they say about dead horses. Also, according to Google Scholar, the article has 1616 citations, including 120 citations in 2023 alone, so, yeah, still worth discussing.
That said, not all the references refer to the substance of the paper. For example, the very first paper on Google Scholar’s list of citers is a review article, Explaining the Decline in the US Employment-to-Population Ratio, and when I searched to see what they said about this Canada paper (Baker, Gruber, and Milligan 2008), here’s what was there:
Additional evidence on the effects of publicly provided childcare comes from the province of Quebec in Canada, where a comprehensive reform adopted in 1997 called for regulated childcare spaces to be provided to all children from birth to age five at a price of $5 per day. Studies of that reform conclude that it had significant and long-lasting effects on mothers’ labor force participation (Baker, Gruber, and Milligan 2008; Lefebvre and Merrigan 2008; Haeck, Lefebvre, and Merrigan 2015). An important feature of the Quebec reform was its universal nature; once fully implemented, it made very low-cost childcare available for all children in the province. Nollenberger and Rodriguez-Planas (2015) find similarly positive effects on mothers’ employment associated with the introduction of universal preschool for three-year-olds in Spain.
They didn’t mention the bit about “the evidence suggests that children are worse off” at all! Indeed, they’re just kinda lumping this in with positive studies on “the effects of publicly provided childcare.” Yes, it’s true that this new article specifically refers to “similarly positive effects on mothers’ employment,” and that earlier paper, while negative about the effect of universal child care on kids, did say, “Maternal labor supply increases significantly.” Still, when it comes to sentiment analysis, that 2008 paper just got thrown into the positivity blender.
I don’t know how to think about this.
On one hand, I feel bad for Baker et al.: they did this big research project, they achieved the academic dream of publishing it in a top journal, it’s received over 1616 citations and remains relevant today—but, when it got cited, its negative message was completely lost! I guess they should’ve given their paper a more direct title. Instead of “Universal Child Care, Maternal Labor Supply, and Family Well‐Being,” they should’ve called it something like: “Universal Child Care: Good for Mothers’ Employment, Bad for Kids.”
On the other hand, for the reasons discussed above, I don’t actually believe their strong claims about the child care being bad for kids, so I’m kinda relieved that, even though the paper is being cited, some of its message has been lost. You win some, you lose some.


