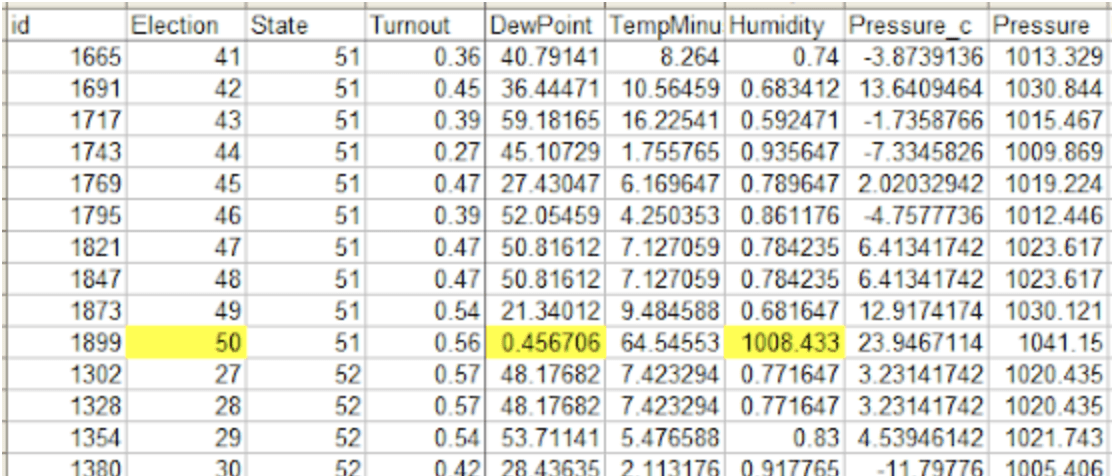
More specifically, he says:
ChatGPT can do deep, involved reasoning. It has the context capacity to do that.
I [Bob] think that human language is what is known as “AI complete”. To be good at language, you have to be intelligent, because language is about the world and context. You can’t do what ChatGPT does ignorant of the world or be unable to plan. . . .
Humans also generally produce output one word at a time in spoken language. In writing we can plan and go back and revise. We can do a little planning on the fly, but not nearly as much. To me, this was the biggest open problem in computational linguistics—it’s what my job talk was about in 1989 and now it’s basically a solved problem from the engineering if not scientific perspective.
I [Bob] am not saying there’s no limitations to using the LLM architecture—it doesn’t have any long- or really medium-term memory. I’m just saying it can’t do what it does now without some kind of “intelligence”. If you try to define intelligence more tightly, you either rule out humans or you somehow say that only human meat can be intelligent.
I told Bob that take on this might be controversial, even among computer scientists, and he replied:
Of course. Everything’s controversial among academics . . .
My [Bob’s] position is hardly novel. It’s the take of everyone I know who understands the tech (of course, that’s a no-true-Scotsman argument), including this paper from Microsoft Research. I do think if you have studied cognitive science, philosophy of language, and philosophy of mind, studied language modeling, studied psycholinguistics, have some inkling of natural language compositional semantics and lexical semantics, and you understand crowdsourcing with human feedback, then you’re much more likely to come to the same conclusion as me. If you’re just shooting from the hip without having thought deeply about meaning and how to frame it or how humans process language a subword component at a time, then of course the behavior seems “impossible”. Everyone seems to have confused it with cutting-and-pasting search results, which is not at all what it’s doing.
I’m not saying it’s equivalent to a human, just that whatever it’s doing is a form of general intelligence. What it’s truly lacking is longer term memory. That means there are things humans can do that it really is incapable of doing in its present form. But that’s not because it’s a “dumb machine”. We’re just “dumb meat” viewed from that perspective (unless you want to get all spiritual and say we have a soul of some kind that matters).
Bob also recommends this paper from Google and this one from OpenAI, and he continues:
There’s a ton of work on scaling laws now and what people are seeing is emergent behavior at certain model sizes. As in like 1% performance for 3B parameters, then 95% performance for 6B parameters kind of thing. But nobody knows why this is happening or where.
The capacity of these models is quite high, including the representation of words, representation of positions, etc. It’s generting one word at a time, but the structrure is an incredibly rich time series with literally billions of parameters.
The background here is that I’ve been reading what Thomas Basbøll has been writing on chatbots and the teaching of writing (a topic of interest to me, because I teach writing as part of my Communicating Data and Statistics course), and he recommended a long article by Giulio Alessandrini, Brad Klee, and Stephen Wolfram entitled “What Is ChatGPT Doing . . . and Why Does It Work?”
I really liked Alessandrini et al.’s article. It was at the right level for me, stepping through the following topics:
It’s Just Adding One Word at a Time
Where Do the Probabilities Come From?
What Is a Model?
Models for Human-Like Tasks
Neural Nets
Machine Learning, and the Training of Neural Nets
The Practice and Lore of Neural Net Training
“Surely a Network That’s Big Enough Can Do Anything!”
The Concept of Embeddings
Inside ChatGPT
The Training of ChatGPT
Beyond Basic Training
What Really Lets ChatGPT Work?
Semantic Grammar and the Power of Computational Language
So . . . What Is ChatGPT Doing, and Why Does It Work?
Alessandrini et al.’s article has lots of examples, graphs, and code, and I get the impression that they’re actively trying to figure out what’s going on. They get into some interesting general issues; for example,
One might have thought that for every particular kind of task one would need a different architecture of neural net. But what’s been found is that the same architecture often seems to work even for apparently quite different tasks. At some level this reminds one of the idea of universal computation . . . but I think it’s more a reflection of the fact that the tasks we’re typically trying to get neural nets to do are “human-like” ones—and neural nets can capture quite general “human-like processes”.
In earlier days of neural nets, there tended to be the idea that one should “make the neural net do as little as possible”. For example, in converting speech to text it was thought that one should first analyze the audio of the speech, break it into phonemes, etc. But what was found is that—at least for “human-like tasks”—it’s usually better just to try to train the neural net on the “end-to-end problem”, letting it “discover” the necessary intermediate features, encodings, etc. for itself. . . .
That’s not to say that there are no “structuring ideas” that are relevant for neural nets. Thus, for example, having 2D arrays of neurons with local connections seems at least very useful in the early stages of processing images. And having patterns of connectivity that concentrate on “looking back in sequences” seems useful . . . in dealing with things like human language, for example in ChatGPT.
They also talk about the choices involved in tuning the algorithms—always an important topic in statistics and machine learning—so, all in all, I think a good starting point before getting into the technical articles that Bob pointed us to above. I pointed Bob to the Alessandrini et al. tutorial and his reaction was that it “seriously under-emphasizes the attention model in the transform and the alignment post-training. It’s the latter that took GPT-3 to ChatGPT, and it’s a huge difference.”
That’s the problem with sending a pop science article to an expert: the expert will latch on to some imperfection. The same thing happens to me when people send me popular articles on Bayesian statistics or American politics or whatever: I can’t help focusing on the flaws. Anyway, I still like the Alessandrini et al. article, I guess more so when supplemented with Bob’s comments.
P.S. Also I told Bob I still don’t get how generating one word at a time can tell the program to create a sonnet in the style of whoever. I just don’t get how “Please give me a sonnet . . .” will lead to a completion that has sonnet form. Bob replied:
Turn this around. Do you know how you write sentences without planning them all out word by word ahead of time? Language is hard, but we do all kinds of planning in this same way. Think about how you navigate from home to work. You don’t plan out a route step by step then execute it, you make a very general plan (‘ride my bke’ or ‘take the subway’), take a step toward that goal, then repeat until you get to work. As you get to each part of the task (unlock the bike, carry the bike outside, put the kickstand up, get on the bike, etc.) are all easily cued by what you did last, so it barely requires any thought at all. ChatGPT does the same thing with language. ChatGPT does a ton of computation on your query before starting to generate answers. It absolutely does a kind of “planning” in advance and as the MS paper shows, you can coach it to do better planning by asking it to share its plans. It does this all with its attention model. And it maintains several rich, parallel representations of how language gets generated.
Do you know how you understand language one subword component at a time? Human brains have *very slow* clock cycles, but very *high bandwidth* associative reasoning. We are very good at guessing what’s going to come next (though not nearly as good as GPT—it’s ability at this task is far beyond human ability) and very good at piecing together meaning from hints (too good in many ways as we jump to a lot of false associations and bad conclusions). We are terrible at logic and planning compared to “that looks similar to something I’ve seen before”.
I think everyone who’s thought deeply about language realizes it has evolved to make these tasks tractable. People can rap and write epic poems on the fly because there’s a form that we can follow and one step follows the next when you have a simple bigger goal. So the people who know the underlying architectures, but say “oh language is easy, I’m not impressed by ChatGPT” are focusing on this aspect of language. Where ChatGPT falls down is with long chains of logical reasoning. You have to coax it to do that by telling it to. Then it can do it in a limited way with guidance, but it’s basic architecture doesn’t support good long-term planning for language. If you want GPT to write a book, you can’t prompt it with “write a book”. Instead, you can say “please outline a book for me”, then you can go over the outline and have it instantiate as you go. At least that’s how people are currently using GPT to generate novels.
I asked Aki Vehtari about this, and Aki pointed out that there are a few zillion sonnets on the internet already.
Regarding the general question, “How does the chatbot do X?”, where X is anything other than “put together a long string of words that looks like something that could’ve been written by a human” (so, the question could be, “How does the chatbot write a sonnet” or “How does ChatGPT go from ‘just guessing next word’ to solving computational problems, like calculating weekly menu constrained by number of calories?”), Bob replied:
This is unknown. We’ve basically created human-level or better language ability (though not human or better ability to connect language to the world) and we know the entire architecture down to the bit level and still don’t know exactly why it works. My take and the take of many others is that it has a huge capacity in its representation of words and its representation of context and the behavior is emergent from that. It’s learned to model the world and how it works because it needs that information to be as good as it is at language.
Technically, it’s a huge mixture model of 16 different “attention heads”, each of which is itself a huge neural network and each of which pay attention to a different form of being coherent. Each of these is a contextual model with access to the previous 5K or so words (8K subword tokens).
Part of the story is that the relevant information is in the training set (lots of sonnets, lots of diet plans, etc.); the mysterious other part is how it knows from your query what piece of relevant information to use. I still don’t understand how it can know what to do here, but I guess that for now I’ll just have to accept that the program works but I don’t understand how. Millions of people drive cars without understanding at any level how cars work, right? I basically understand how cars work, but there’d be no way I could build one from scratch.