The other day I fit a simple model to estimate team abilities from World Cup outcomes. I fit the model to the signed square roots of the score differentials, using the square root on the theory that when the game is less close, it becomes more variable.
0. Background
As you might recall, the estimated team abilities were reasonable, but the model did not fit the data, in that when I re-simulated the game outcomes using the retrospectively fitted parameters, my simulations were much close than the actual games. To put it another way, many more than 1/20 of the games fell outside their 95% predictive intervals.
1. Re-fitting on the original scale
This was buggin me. In some way, the original post, which concluded with “my model sucks,” made an excellent teaching point. Still and all, it was a bummer.
So, last night as I was falling asleep, I had the idea of re-fitting the model on the original scale. Maybe the square-root transformation was compressing the data so much that the model couldn’t fit. I wasn’t sure how this could be happening but it seemed worth trying out.
So, the new Stan program, worldcup_raw_matt.stan:
data {
int nteams;
int ngames;
vector[nteams] prior_score;
int team1[ngames];
int team2[ngames];
vector[ngames] score1;
vector[ngames] score2;
real df;
}
transformed data {
vector[ngames] dif;
dif <- score1 - score2;
}
parameters {
real b;
real sigma_a;
real sigma_y;
vector[nteams] eta_a;
}
transformed parameters {
vector[nteams] a;
a <- b*prior_score + sigma_a*eta_a;
}
model {
eta_a ~ normal(0,1);
for (i in 1:ngames)
dif[i] ~ student_t(df, a[team1[i]]-a[team2[i]], sigma_y);
}
Just the same as the old model but without the square root stuff.
And then I appended to my R script some code to fit the model and display the estimates and residuals:
# New model 15 Jul 2014: Linear model on origional (not square root) scale
fit <- stan_run("worldcup_raw_matt.stan", data=data, chains=4, iter=5000)
print(fit)
sims <- extract(fit)
a_sims <- sims$a
a_hat <- colMeans(a_sims)
a_se <- sqrt(colVars(a_sims))
library ("arm")
png ("worldcup7.png", height=500, width=500)
coefplot (rev(a_hat), rev(a_se), CI=1, varnames=rev(teams), main="Team quality (estimate +/- 1 s.e.)\n", cex.var=.9, mar=c(0,4,5.1,2))
dev.off()
a_sims <- sims$a
sigma_y_sims <- sims$sigma_y
nsims <- length(sigma_y_sims)
random_outcome <- array(NA, c(nsims,ngames))
for (s in 1:nsims){
random_outcome[s,] <- (a_sims[s,team1] - a_sims[s,team2]) + rt(ngames,df)*sigma_y_sims[s]
}
sim_quantiles <- array(NA,c(ngames,2))
for (i in 1:ngames){
sim_quantiles[i,] <- quantile(random_outcome[,i], c(.025,.975))
}
png ("worldcup8.png", height=1000, width=500)
coefplot ((score1 - score2)[new_order]*flip, sds=rep(0, ngames),
lower.conf.bounds=sim_quantiles[new_order,1]*flip, upper.conf.bounds=sim_quantiles[new_order,2]*flip,
varnames=ifelse(flip==1, paste(teams[team1[new_order]], "vs.", teams[team2[new_order]]),
paste(teams[team2[new_order]], "vs.", teams[team1[new_order]])),
main="Game score differentials\ncompared to 95% predictive interval from model\n",
mar=c(0,7,6,2), xlim=c(-6,6))
dev.off ()
And here's what I got:
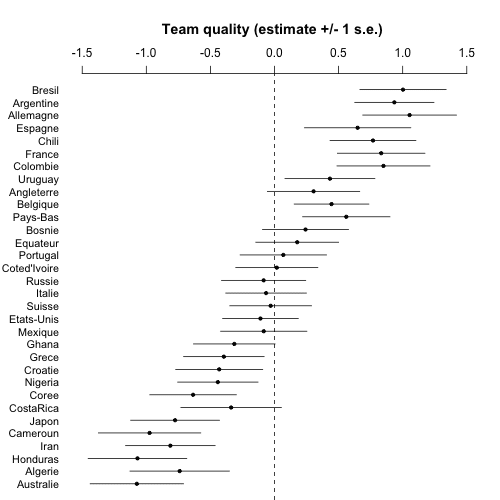
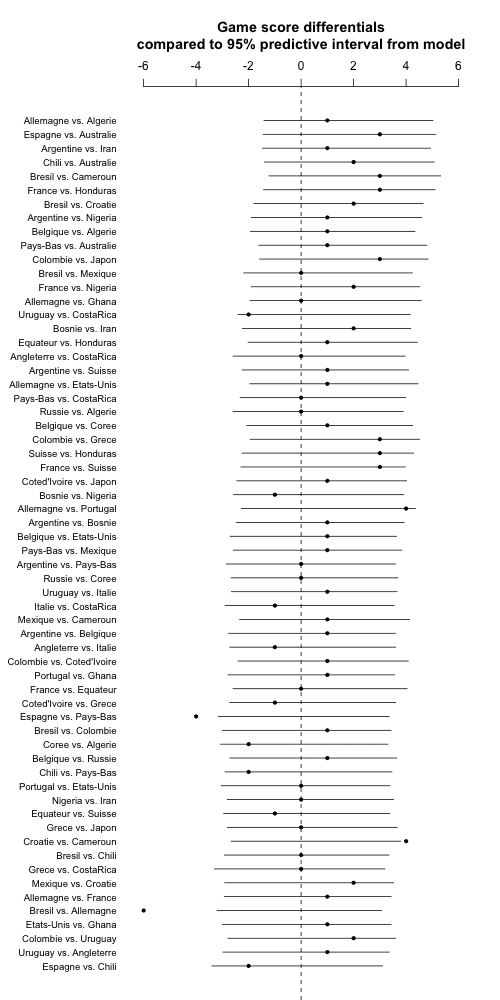
And this looks just fine, indeed in many ways better than before, not just the bit about the model fit but also the team ability parameters can now be directly interpretable. According to the model fit, Brazil, Argentina, and Germany are estimated to be 1 goal better than the average team (in expectation), with Australia, Honduras, and Cameroon being 1 goal worse than the average.
2. Debugging
But this bothered me in another way. Could those square-root-scale predictions have been that bad? I can't believe it. Back to the code. I look carefully at the transformation in the Stan model:
transformed data {
vector[ngames] dif;
vector[ngames] sqrt_dif;
dif <- score1 - score2;
for (i in 1:ngames)
sqrt_dif[i] <- (step(dif[i]) - .5)*sqrt(fabs(dif[i]));
}
D'oh! That last line is wrong, it's missing a factor of 2. Stan doesn't have a sign() function so I hacked something together using "step(dif[i]) - .5". But this difference takes on the value +.5 if dif is positive or -.5 if dif is negative (zero doesn't really matter because it all gets multiplied by abs(dif) anyway). Nonononononononono.
Nononononononononononononononono.
Nonononononononononononononononononononononono.
Damn.
OK, I fix the code:
transformed data {
vector[ngames] dif;
vector[ngames] sqrt_dif;
dif <- score1 - score2;
for (i in 1:ngames)
sqrt_dif[i] <- 2*(step(dif[i]) - .5)*sqrt(fabs(dif[i]));
}
I rerun my R script from scratch. Stan crashes R. Interesting---I'll have to track this down. But not right now.
I restart R and run. Here are the results from the fitted model on the square root scale:
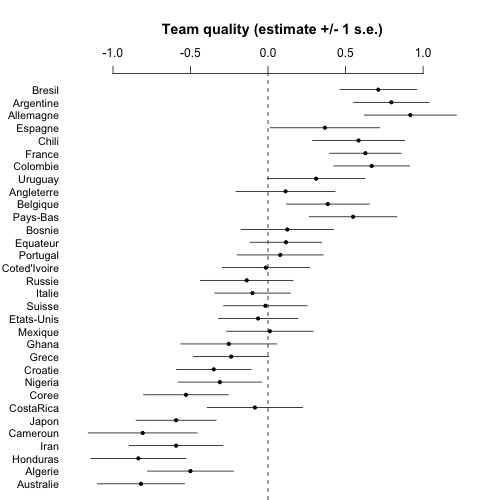
And here are the predictions and the game outcomes:
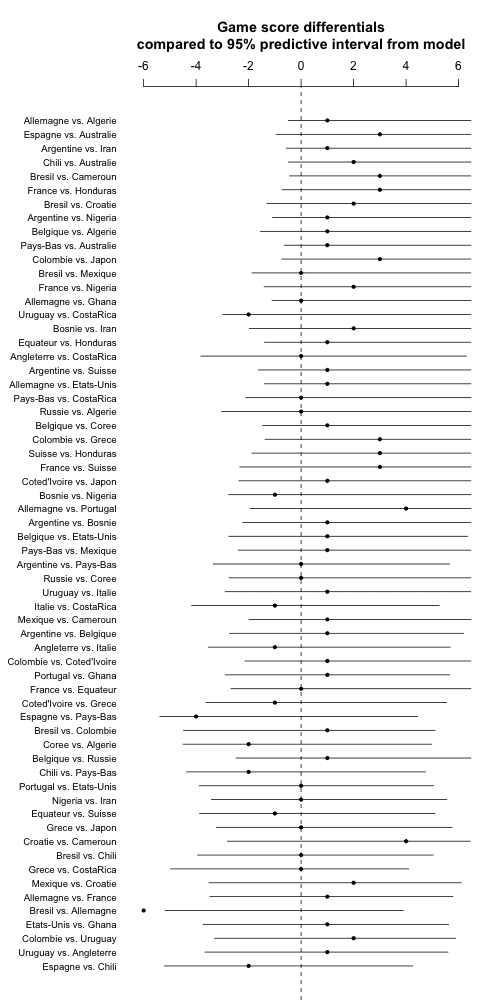
I'm not quite sure about this last graph but I gotta go now so I'll post, maybe will look at the code later if I have time.
3. Conclusions
My original intuition, that I could estimate team abilities by modeling score differentials on the square root scale, seems to have been correct. In my previous post I'd reported big problems with predictions, but that's because I'd dropped a factor of 2 in my code. These things happen. Modeling the score differences on the original scale seems reasonable too. It's easy to make mistakes, and it's good to check one's model in various ways. I'm happy that in my previous post I was able to note that the model was wrong, even if at the time I hadn't yet found the bug. It's much better to be wrong and know you're wrong than to be wrong and not realize it.
Finally, now that the model fits ok, one could investigate all sorts of thing by expanding it in various ways. But that's a topic for another day (not soon, I think).
Naive question: Say in your first figure do all those long bars on score differentials mean that we are fairly confident that the outcome will be “Either Team A wins with a 2 goal lead or Team B wins with a 5 goal lead.”
How is that a good result? Isn’t that analogous to saying I’m 95% confident that the temperature tomorrow in Wisconsin will be between 5 Celsius to 45 C
Or am I misinterpreting what those long bars mean?
It’s a good result if you want sport to be unpredictable. If you could predict it, it would be a yawn.
Yes, but also, “one could investigate all sorts of thing by expanding it in various ways”
Its good if we want the results to reflect the uncertainty inherent in the problem. It is bad if we were hoping for the philosophers’ stone (that perfect analysis, which turns the data into gold).
So would the model be even better if all bars were much longer? Say, every bar -10 Goals to +10 Goals?
In other prediction models I’ve seen accuracy / false positives / AUC etc. being used. Hence I’m genuinely confused how Andrew was judging good or bad “by eyeballing”.
Rahul:
You want approx 95% of the 95% predictive intervals to contain the true values. Not 50%, but also not 100%.
Uh, I want 100% of the predictive intervals to contain the true values.
The goal is to predict the true values, not to predict what percentage of the time I’ll be wrong.
@Anon:
Um, you want *95%* predictive intervals to have *100%* coverage? So, you want your 95% predictive intervals to be infinitely wide? What good is that? I don’t follow at all…
Re: what you want to know, Deborah Mayo’s work has good discussions of why you *should* want to know the error probabilities of your model (“what percentage of the time I’ll be wrong”, if you want to put it that way).
Yes Jeremy the goal of predictive intervals is to predict the thing they’re trying to predict. There are lots and lots of intervals which aren’t infinitely wide that do so.
What percentage of the time those intervals are wrong is up to Mother Nature, not Mother Mayo.
It’s a good thing too that our goal isn’t to be wrong 5% of the time.
Creating reasonable sized prediction intervals which are as close to 100% right as possible, is far easier than creating a set which is wrong a known guaranteed percentage of the time.
Anon, the point is that nominal 95% intervals that cover >>95% of the time could be made narrower without becoming overconfident — such timorous intervals “leave money on the table”, as it were. (I suspect I’ve said that to you before.)
trading uncertainty to get smaller intervals is NOT the same as trying to be wrong a fixed percentage of the time.
Anon:
Remember the motto: Accept uncertainty and embrace variation. Soccer games would be pretty boring if you could predict the outcome ahead of time!
I didn’t say the gaol of 100% could be achieved, but it is the goal.
I agree with @anon here. The goal ought to be to be right as many times as possible. The more the better. How well you can actually do depends.
But I see no fundamental constraint as to why a Superman model could not be right 99.99% of the time some day. Theoretically at least.
I do not see what’s the downside with 100% accuracy if you could somehow achieve it.
Rahul:
If you could predict the score differential of a soccer game to 99% accuracy before the game occurs, I’m pretty sure they’ll change the rules. The point is that the game outcome is inherently uncertain.
Andrew:
Fair enough. What if I was predicting, say, a weather related outcome. Surely nature won’t change its game because I’m getting better at predicting it?
Even for sports maybe I made a 99% accurate model but didn’t announce it to the world, just used it to make money via small bets.
No doubt outcomes are uncertain but there’s no fundamental rule here a la Heisenberg that sets a strict bound on how much we can reduce the uncertainty.
Rahul,
I doubt whether a supermodel which can be right 99% exists. I would expect from such a supermodel,
if exists, to make an ‘ideal’ prediction based on the actual random process of the problem. Then
isn’t the best we can expect on average from such a prediction, be limited by the posterior cramer rao bound based on the actual
stochastic process of the problem?
@Sachintha:
Interesting; I wasn’t aware of this.
If this constraint applies, what would be the upper bound of accuracy for this particular application? Can you provide a number (80%? 90%? 95%?) or outline the procedure to estimate such a number?
“If this constraint applies, what would be the upper bound of accuracy for this particular application? Can you provide a number (80%? 90%? 95%?) or outline the procedure to estimate such a number?”
I think it’s impossible to say (or even guess) what the real upper bound is, but bookmakers (and they are pretty good…) have accuracy of 50-60% for major European soccer/football leagues. So at least that is the some kind of “lower upper bound” estimate.
And by that 50-60% accuracy I mean the predictions for home/draw/away (ie. 33% by randomly guessing).
@germo:
But that’s only an empirical bound. Something like Heisenberg or Cramer-Rao sounds more fundamental.
So is Cramer-Rao not applicable in any sort of quantitative manner to such situations?
Rahul, it is not possible to find the Posterior Cramer Rao Bound (PCRB) for the actual stochastic process underlying the problem,
since we don’t know what the underlying actual random process is. However, it is possible to find (or at least approximate using Monte Carlo) the PCRB for the measurement and data model “assumed” by Andrew (but that is a not what we want).
“If you could predict the score differential of a soccer game to 99% accuracy before the game occurs, I’m pretty sure they’ll change the rules. The point is that the game outcome is inherently uncertain”
Andrew striving to be wrong 5% of the time doesn’t embrace uncertainty any more than striving to be right 100% of the time.
That would be doable, but it’s not what’s plotted. Well, getting arbitrarily close to 100% would be possible (i.e. 99.99% coverage).
I think you’d find that near 100% coverage would give such wide intervals that they’d be less helpful in predicting outcomes. Soccer games between closely-matched teams are going to be intrinsically hard to predict.
If the actual coverage of your intervals is wider than the model-predicted coverage (in this case, 95%), it means your model overestimates the variance, no?
Isn’t that trivially easy? e.g. I assign prediction intervals {-20 to +20} goals for 95% games. And an interval {49 to 50} for 5% games. 95% of time intervals will contain the true values.
My point is that the width of the prediction intervals ought to somehow matter.
PS. I loved your practical exposition save that I’m still unclear on how you validate the model’s performance at each refinement.
yes, and there are lots of intervals that achieve the gaol.
Finding some that are useful, and whose rightness can be known ahead of time, is what people like you, Andrew, and Fox (but not Mayo!) get paid for.
Put it this way. Finding intervals that are known to be right 95% of time (which is somehow known without knowledge of which ones are right) might be one way to achieve that goal.
It’s far from the only way however, and even farther from being the most practical.
Rahul:
Yes, this is a well known issue. Calibration is desirable but is not enough by itself. Sometimes this is expressed in terms of the goal of having the intervals be as short as possible while retaining the desired coverage. From a Bayesian point of view it’s simple enough: posterior intervals should have, on average, the desired coverage, and the width of the intervals depends on how much information is available at each prediction.
Seems this discussion is conflating two issues:
1. We want to give reasonable guarantees about the precision of our estimates: a 95% interval, in which the true value should fall into ~19 out of 20 times, is an accepted approach (okay, maybe not) and lends itself to confirmation as with Andrew’s posterior predictive checks. Andrew should be concerned if his prediction intervals were far from 95%, as his results would be giving a false sense of certainty/uncertainty –> not cool! I think that is why he expressed being happy with the final results he came to: they were being honest about accuracy (according to in-sample fit anyway).
2. We want more accurate results. So yeah, this is where the Superman model comes in, and improved accuracy has no downside. Of course, a ‘Superman model’ (i.e. tiny predictive intervals and perfect point estimates in Andrew’s posterior predictive checks) created with just the small amount of data available from the world cup would have to be fitting noise, and so the in-sample fits (as Andrew presents) would likely be a bad gauge of the out-of-sample fit (which is probably what we want to know).
Andrew:
To ask a concrete question, why do you consider your fit in “worldcup8.png” better than “worldcup5.png”?
Sure the latter iteration has more points that fall within your 95% intervals (i.e. fewer outliers) but OTOH the intervals in the latter model seem (on average) at least twice as big as the earlier model.
How do you decide if this tradeoff is worth it? Won’t you want to evaluate every iteration of your model by predictive-accuracy or AUC or some such metric?
http://statmodeling.stat.columbia.edu/wp-content/uploads/2014/07/worldcup5.png
http://statmodeling.stat.columbia.edu/wp-content/uploads/2014/07/worldcup8.png
Rahul:
There was clearly something wrong with my first model because the predictions weren’t close to calibrated. It’s fine to give narrow intervals but then I want to label them correctly. I could, for example, give narrow 50% predictive intervals and wider 95% predictive intervals.
The World Cup example did make me download and install Stan and get the code running. Without that incentive I would have kept putting it off as being too hard – so that’s a win for increasing the user base.
And I hacked around trying a different transformation, a different prior and using some covariates. So I’m pretty pleased at how it worked out for me.
This example also pushed me to finally download and install Stan. I have not had time to run the World Cup model.
It is interesting, that some folks download and ran it and no one (yet has claimed they) found the error.
When I looked at the code “(step(dif[i]) – .5)*sqrt(fabs(dif[i]));” I just thought it was a way to calculate signed square root in STAN and probably conjectured Andrew would not get that wrong.
Doing things a number of different ways is likely the only way to ensure seeming obvious things were not somehow in error.
Wouldn’t it be better just to code (I actually this was the case in the original model): step(dif[i] – .5) instead of multiplying by two?
Or even better: ifelse(dif[i]>=0, 1, -1)
I like the ifelse version. Andrew learned to code models like these in BUGS and still speaks with an accent.
Andrew asked for a signum function, but we’re reluctant to add it because it’s not differentiable and we don’t want to encourage those kinds of functions applied to parameters. There’s been ongoing discussion on our dev list about not only this case, but fabs(), floor(), ceil(), and round(), as well as allowing parameters in conditionals. We could make signum() a data-only function.
This example illustrates that we are going to have to build some kind of testing framework for Stan functions and then urge users to treat them more like software and less like the math in papers. That is, test each piece thoroughly before slotting it into the bigger picture.
Bob:
I’m surprised you say you like the if_else version. In the manual you discourage both if_else and step, instead recommending a multi-line conditional statement. I would’ve liked to just have a sign function.
Also it seems weird that the absolute value function is fabs rather than abs, but I guess that’s some C thing?
abs for ints & fabs for floats. I think.
Thanks so much for blogging about a mistake. It’s heartening to see that even my heroes slip up sometimes. I shall remember this next time I drop a clanger in my R code.
I agree. The last post and this one might actually be far more enlightening and encouraging for some of us than many other interesting and well thought out stuff.
+1 I really loved the hands on part of this post. And the willingness to get hands dirty with actual code & data.
Also liked Bob’s post about D&D dice for the same reason. I’d love to see an increase in the fraction of posts that have actual code in them.
As a counterpoint, I’m a bit tired of the posts on plagiarism, journalists-who-wont-admit-they-are-wrong & graph critiques. Let’s bury Wegman, Potti, & Brooks finally!
PS. I do realize that beggars can’t be choosers. :)
As an other beggar I beg to differ. I like those, too. ;-)
I’d love to see more posts like these two. It’s really instructive to have someone talk through rationale and dealing with issues as they arise.
I completely agree. Sheepishly, I was always slightly loose about what Andrew meant by posterior predictive checks, but this makes it very explicit.
Interesting that your model adds hardly any value over a simple constant (across matches) prior that most world cup games will be within +-4. There are a lot of determinants of the score difference other than some kind of “skill” clearly. (and the match fixers have realized that one of the big determinants is the referee calls, see http://www.nytimes.com/2014/06/01/sports/soccer/fixed-matches-cast-shadow-over-world-cup.html?_r=0 )
I like the idea of modeling simultaneously two “qualities” an “attack” and “defend”. Then matches that wind up like 7-1 would indicate a bad mismatch between the attacking power of the first team and defending power of the second team, etc.
Dan:
The model doesn’t add a lot of predictive power for most individual games, but it can rank the teams. The key is that each team plays multiple games. So for the purpose of estimating team ability, it’s ok if the model doesn’t predict individual games well. Similar to psychometrics: one exam question doesn’t discriminate well among students, but if you ask a lot of questions you can get a pretty good test.
Regarding scores such as 7-1: I’m inclined to think there’s some positive feedback here, which is one reason I’m not particularly interested in Poisson-type models that try to leverage some model of independence during the game.
In the absence of predictive power how does one distinguish a crappy methodology of rankings from a good one? Is it an open ended exercise?
> but it can rank the teams
Mostly from the prior as seen in the Team Quality graph.
Keith:
Sure, but the coefficient for the prior rankings was estimated from the data. So what we’re saying is the data, sparse as they are, are still dense enough to allow us to see that they are consistent with the prior ordering.
Yes, the data is doing something, I was just wondering if there might be a direct way to see exactly what …
And perhaps I should have worked on that a bit more before commenting ;-)
Yes, I agree with you about non-independence. I think the overall ranking of the team is less interesting to me than the attack and defend ranks. I saw some amazing games, like Germany vs Algeria where Germany clearly outranked Algeria in attacking but Algeria had tremendous will to resist them on defense compared to what you’d expect. Similarly for the Brazil vs Chile game. Maybe I’ll start with your zip file and see if I can come up with something interesting.
The really important question here is wether the Stan model does better than an octopus in predicting the outcome of each match.
Thus far my money is on the octopus ;-)
PS If the interest is on team ability the octopus won’t do. The question then is whether Stan does better than Joe the football fan in ranking.
The best outcome might be for Joe and Stan to have a conversation. Man + machine is a winner.
Fernando:
Yes, defnitely. Indeed the Stan model includes “man” in the form of Nate’s predictions. But there’s a lot more information it could include, indeed it’s pretty explicitly a bare-bones model.
Lets make some money: http://www.loteriasyapuestas.es/en/la-quiniela/como-se-juega/como-jugar-a-la-quiniela.info
BTW if everyone uses the (same) best model, then prizes might be very small since there are many winners. I wonder whether it is best to bet E[y] or Y_rep. Sure, you’ll loose more often with the latter but you might win bigger.
Looks like we have a case study for the Stan book!
And a challenge in writing up predictive intervals and what they mean, and in particular sampling error versus residual model error. There must be some good writeups of this somewhere in the regression literature, I’d think.
+1 I’d love to see a post on such stuff too. Overall this discussion has made me totally confused about what constitutes a good predictive model.
To sum up my (probably naive) confusion:
(1) When a model has wide predictive intervals how do we tell if the model is just weak or the uncertainty is due to the data itself?
(2) How do we penalize models purporting good accuracy just by using unduly wide intervals?
(3) I’ve seen metrics like root mean square error, absolute error, false positive rates, accuracy, specificity, AUC etc. but is it possible / reasonable to do an iterative model improvement exercise without using any such quantitative metric?
(4) What’s the best way to translate the goal difference intervals in Andrew’s model into binary win / loss predictions? Midpoints? Is probability symmetrically distributed within the intervals? Normally? Uniformly?
(5) Does it make sense to validate a sports model based on its win / loss predictive accuracy or goal differential accuracy? e.g. Model A predicts a German win with 6 goal lead and Model B predicts a German loss with a 1 goal lag. Germany actually wins but with only a 1 goal lead. Which model is better?
What’s interesting to me is that a true philosophical bayesian would try to answer all of these sorts of questions with priors, posteriors etc, but what’s doing the problem solving work in the model building and debugging above seems, to me, to be not very bayesian at all. It seems a minor point that the modelling language used is bayesian statistical in flavour.
For one it’s very informal but for two (is that a phrase?) even if it was formalised I don’t think it would fit the bayesian philosophical mold. Now Andrew ‘it’s in my book/papers’ Gelman would probably say it fits in with his form of (popper-lakatos) bayesian but even in his paper with Cosma Shalizi it’s not very clear what that actually is (I did really enjoy the paper; needs a version 2.0 though imo).
The moving goal posts of the current bayesian movement are frustrating – is it more philosophically convincing (I’d say no, when you actually look at it carefully), does it enable a fairly flexible and easy to use statistical modelling language (yes), does it give you all these things you just can’t get from frequentist style stats (again I’d say no, freq stats is not just pvalues and point estimates). These factors make it seem like it’ll just be another passing fad which had some good points but was massively overhyped.
For now though I’ve downloaded and installed Stan so I can keep up with the kids :-)
Hjk:
I have no problem with people who’d like to use other methods to solve problems like this and this and this etc etc etc. As I’ve written many times, there are lots of ways to solve statistical problems. I use the methods that I’m familiar with and that work for me.
Oh I know, I’m just been annoying really. You’re one the most frustratingly reasonable voices around. I think you have a nice way of approaching things – I’m just trying to unpick what exactly that amounts to and occasionally throw in an overly cynical comment,
hjk: > “does it enable a fairly flexible and easy to use statistical modelling language (yes)”
But grasping how its worked, in what sense and how well may be much much harder to make easy.
Absolutely.
We’re pragmatic Bayesians here at Stan headquarters. People may not realize this, but Stan can give you penalized maximum likelihood estimates, too.
1. You can run simulations where the parameter values are known in order to see the power of the method in terms of how sampling error there is (i.e., how much your uncertainty is due to small data sizes vs. intrinsic uncertainty given the model).
2. The point is that you want the intervals themselves to be accurate with respect to the model. That’s why you want 95% intervals to have 95% coverage and 50% intervals to have 50% coverage. It’s called calibration. Given two well calibrated models, the one with narrower intervals is better predictively.
3. Bayesian posterior means minimize expected square error and posterior medians expected absolute error. But this is all assuming the model’s right. We like cross validation for model improvement; WAIC is the estimate of that which Andrew and Aki are promoting at the moment, but you can also do it directly. If you go back to Bayesian theory, you can also evaluate by betting — whose model lets you place better bets in the long run?
4. You want to do posterior inference and evaluate Pr[goals for team A > goals for team B]. That gives you the probability that team A wins, and evlauate Pr[goals for team A = goals for team B] gives you the tie probability. It’d be interesting to calculate these (easy to do in Stan — there are examples in the manual) and see how well they matched the oddsmakers odds. Note that if you want to make book on sports, you better get the odds right, not just be good at predicting who will win. Getting the odds right is a kind of model calibration. If you offer 9:1 odds for team A over team B, but team A’s chance of winning is more like 70% than 90%, then you’ll go broke over time. (Of course, in real life, bookmakers adjust their odds to minimize risk, just like other financial market makers — you can’t have all your customers betting on the longshot because you’ll get blown out if it hits.)
5. Depends what you want your model to do. If you want to use it to make book, you better get the odds right. Note that this is different than predictive accuracy. You may have odds of 3:2, which isn’t much predictive accuracy, but may be the correct odds given all that’s known (a very nebulous and pragmatic concept — let’s not get into knowing the position and trajectory of every particle in the universe kinds of arguments). Alternatively, if you’re the kind of betting house that offers points to one team rather than odds, you better get the point differentials calculated. But what Andrew was trying to do is rank the teams, not predict games.
Thanks Bob!
Perhaps the fad comment was too harsh – people still use neural networks and genetic algorithms right? We just don’t hear about them as much every day anymore.
Neural networks are probably more popular than ever, thanks to deep learning/object recognition. Some pretty impressive results, like: http://www.image-net.org/challenges/LSVRC/2013/results.php
Sure, but to quote from authority – “There has been a great deal of hype surrounding neural networks, making them seem magical and mysterious. As we make clear in this section, they are just nonlinear statistical models” – Hastie et al in ESL.
I think anthropomorphism explains a part of our fascination with neural networks. Even in applications where other approaches might be a lot cheaper.
Fuzzy logic? Expert Systems? Cold fusion? Simulated annealing? Speech recognition?
Trying to think of other keywords for that set.
The hype around fuzzy logic was eerily similar to the hype around bayes as the ‘real logic of science’. Too bad Jaynes dissed it…
That’s about like saying “the hype surrounding Google Glass is eerily similar to the hype surrounding electricity”
So bayes = google glass and fuzzy logic = electricity? Which is more important?
Well Bayes = electricity, but it wasn’t that great of analogy since the “fad” of Bayes as the logic of science predates the widespread adoption of electricity by a century.
So I guess Bayes is up there in age with those other fads, like “flying”, or “America”, or “antibiotics”.
Fair point. Disregarding my promise below – Bayes-as-the-logic-of-science (and its critiques!) has indeed been around for a long time. I’d argue, though, that it’s gone in-and-out of fashion and is back at fad-ish levels at the moment. History/fashion/etc repeats itself, yadda yadda.
PS to me “America”, at least in its ‘f-yeah’ incarnation is/was/will be a bit of a fad, or is a bit overrated anyway, and “antibiotics” have been great but could have done with a bit less hype so they weren’t so over-prescribed. Not sure how I feel about “flying”.
Anyway, don’t want to lead these comments too off track, sorry!
The interesting next step is to take international competitions in the four years before the world cup and use that as training data. Then build predictions for the world cup. Hopefully you have a model that ranks Germany above Brazil :). Although, as noted above, the variance in sports is great, so testing it on just 62 World Cup games would not necessarily give meaningful feedback.