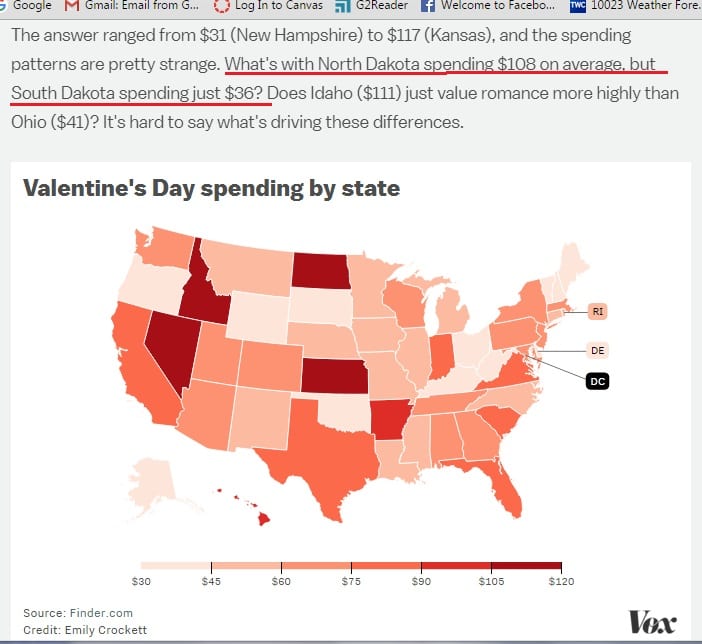
Today’s story starts with a bit of statistically-related fluff, a news report from Emily Crockett entitled, “Here’s how much people in your state spend on Valentine’s Day gifts”:
A survey by Finder.com asked 3,121 Americans how much they spend on Valentine’s Day gifts for their loved ones, and figured out which US states spend the most on average.The answer ranged from $31 (New Hampshire) to $117 (Kansas), and the spending patterns are pretty strange. What’s with North Dakota spending $108 on average, but South Dakota spending just $36? Does Idaho ($111) just value romance more highly than Ohio ($41)? It’s hard to say what’s driving these differences.
Hard to say, indeed. As Jay Livingston points out:
The sample size was 3,121. If they sampled each state in its proportion of the US population, the sample in the each Dakota would be about n = 80. The source of the data, Finder, does not report any margins of error or standard deviations, so we can’t know. Possibly, a couple of guys in North Dakota who’d saved their oil-boom money and spent it on chocolates are responsible for that average. Idaho, Nevada, and Kansas – the only other states over the $100 mark – are also small-n. So are the states at the other other end, the supposedly low-spending states (SD, WY, VT, NH, ME, etc.). So we can’t trust these numbers.
The sample in the states with large populations (NY, CA, TX, etc.) might have been as high as 300-400, possibly enough to make legitimate comparisons, but the differences among them are small – less than $20.
It’s actually quite a bit worse than this. US population: 321 million. North Dakota population: 760,000. Let’s do the math:
3121*(760 thousand)/(321 million) = 7.3.
So you’d expect about 7 or 8 survey respondents in North Dakota, not 80. But Livingston’s point is clear enough, even if he seems to have dropped a zero in his arithmetic.
In any case, Emily Crockett, the author of the above-linked piece, is in good company. According to Howard Wainer, this is the exact same error that the Gates Foundation made when deciding to pour millions of dollars into small schools. (The best, and the worst, performing schools in tests were small schools: they had smaller sample size, thus more variability in their averages.)
Or, as Phil and I put it, all maps of parameter estimates are misleading:
Bring on the Stan
OK, that’s all fine but can we estimate this quantitatively? I don’t see the raw survey data anywhere but the averages by state are here at Finder.com. They give no other details except that the data come from “a finder.com.au survey of 3,121 Americans.”
If someone doesn’t tell you how they conducted their survey you shouldn’t be reporting on it at all, so let me say right now that everything that follows is more of a numerical illustration than anything else.
But here goes.
I downloaded the data, the reported average spent on Valentine’s Day among survey respondents in each state. No individual-level data seem to be available so we have to work with these averages. Let’s assume the sample size in each state is proportional to the state’s population, which we can download from the Census. So we just allocate n = 3121 in proportion to those state populations.
The model then goes like this: for state j, the state average in the sample, ybar_j, is normally distributed with expectation equal to the state mean if everyone in the state were surveyed, theta_j, with sd sigma_y/sqrt(n_j).
We’re interested in how the theta_j’s vary so we give them a normal(mu_theta, sigma_theta) population distribution. This is not ideal—we know the values must be positive—so if any problems arise we can go back and move to the log scale.
Finally, we need priors on the hyperparameters, mu_theta, sigma_theta, and sigma_y. I’ll just slap on weak normal(0, 100) priors (that’s the sd of 100, not variance of 100)—for the sigmas these are half-normal as they are constrained to be positive—again with the understanding that if necessary we’ll go back and add more information.
So here’s the Stan program, which I save in the file valentines.stan:
data {
int J;
vector[J] ybar;
vector[J] sample_size;
}
parameters {
real mu;
vector[J] eta;
real sigma_theta;
real sigma_y;
}
transformed parameters {
vector[J] theta;
theta <- mu + sigma_theta*eta;
}
model {
vector[J] sigma_ybar;
for (j in 1:J)
sigma_ybar[j] <- sigma_y/sqrt(sample_size[j]);
ybar ~ normal(theta, sigma_ybar);
eta ~ normal(0,1);
mu ~ normal(0, 100);
sigma_theta ~ normal(0, 100);
sigma_y ~ normal(0, 100);
}
Here's the R code to load in the data and fit and display the model:
## Read in data and extract state names and average dollars spent according to survey responses
raw <- matrix(scan("valentines_data.txt", what="character", sep="\n", skip=1), ncol=3, byrow=TRUE)
state <- raw[,1]
dollars <- raw[,2]
dollars <- as.numeric(substr(dollars, 2, nchar(dollars)))
## Read in state populations from Census (http://www.census.gov/popest/data/state/totals/2015/index.html)
census_raw <- read.csv("NST-EST2015-01.csv", skip=9, header=FALSE, nrows=51)
census_state <- census_raw[,1]
census_pop <- census_raw[,9]
## Clean the data
census_state <- as.character(census_state)
census_state <- substr(census_state, 2, nchar(census_state))
census_pop <- as.character(census_pop)
census_pop <- as.numeric(gsub(",", "", census_pop))
## Get population for each state in the dataset
J <- length(state)
pop <- rep(NA, J)
for (j in 1:J)
pop[j] <- census_pop[census_state==state[j]]
## Guessed sample size in each state
sample_size <- round(3121*pop/sum(pop))
## Fit the Stan model
library("rstan")
rstan_options(auto_write = TRUE)
options(mc.cores = parallel::detectCores())
ybar <- dollars
fit_1 <- stan("valentines.stan")
## Display the fitted model
print(fit_1, pars=c("mu", "sigma_theta", "sigma_y", "theta"))
library("shinystan")
launch_shinystan(fit_1)
And here's what we get:
Inference for Stan model: valentines.
4 chains, each with iter=2000; warmup=1000; thin=1;
post-warmup draws per chain=1000, total post-warmup draws=4000.
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
mu 65.04 0.08 2.75 59.68 63.14 64.99 66.93 70.36 1185 1.00
sigma_theta 10.95 0.28 4.35 1.95 8.08 10.90 13.77 19.90 249 1.01
sigma_y 99.86 1.29 20.30 59.58 86.33 99.55 113.67 140.75 248 1.01
theta[1] 63.39 0.14 8.74 46.09 57.68 63.81 69.11 80.63 4000 1.00
theta[2] 62.81 0.26 10.91 39.93 56.17 63.43 69.63 83.04 1712 1.00
theta[3] 66.69 0.12 7.69 51.54 61.83 66.70 71.49 82.26 4000 1.00
theta[4] 73.34 0.37 10.43 55.22 66.20 72.42 79.99 95.54 793 1.00
theta[5] 77.85 0.20 5.55 66.60 74.02 78.32 81.74 87.73 806 1.00
. . .
The estimates for sigma_theta and sigma_y seem reasonable enough, unsurprisingly with a lot of uncertainty in each case.
Most of the interest is in the theta's, so let's plot them.
Here's the R code:
## Plot the results!
library("arm")
theta <- extract(fit_1)$theta
state_mean <- apply(theta, 2, mean)
state_sd <- apply(theta, 2, sd)
ordering <- sort.list(state_mean)
pdf("valentines_1.pdf", height=8, width=5)
par(mgp=c(1.2, .3, 0), tck=-.01)
coefplot(state_mean[ordering], sds=state_sd[ordering], varnames=state[ordering], main="Estimated avg amount spent on Valentine's Day", xlim=c(0,100), mar=c(0,7,5,2), cex.main=.9)
dev.off()
Which produces this:
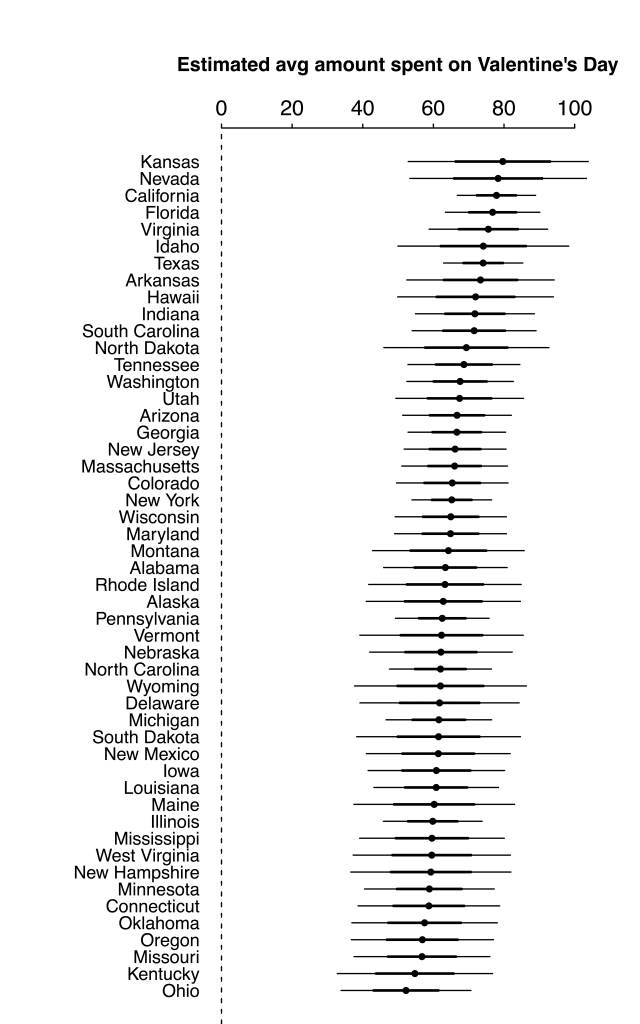
Not much information to distinguish the states. For example, "What's with North Dakota spending $108 on average, but South Dakota spending just $36?"
According to the fitted model, the posterior mean estimate for North Dakota is $69 with a standard error of $12. For South Dakota, the posterior mean is $61 with a standard error of $12.
Here's some R code for comparing the Dakotas:
## Let's compare North and South Dakota dakota_diff <- theta[, state=="North Dakota"] - theta[, state=="South Dakota"] round(mean(dakota_diff)) round(sd(dakota_diff)) round(mean(dakota_diff>0), 2
And here's what we get: the difference has posterior mean of 8 and posterior standard deviation of 17, and there's an estimated 67% chance that average spending is higher in North Dakota than South Dakota.
Soooo . . . we got nuthin'.
In this case, no surprise: small sample, no way to learn much from noisy data. But I was gratified at how direct and how easy it was so set up this model and fit it in Stan. It was just so straightforward. Previously this sort of applied work would've required more effort (see this article from 1994, for example); now we can just directly model what we want to model. Also I'm liking the rhythm of informative priors.
Another win for Stan.
Data and code are here.
P.S. Livingston was disappointed that this story appeared at the serious news site Vox. But all news sites are looking for content, I guess. If the Washington Post can publish a sensationalistic claim such as "Here’s how a cartoon smiley face punched a big hole in democratic theory" (see here for follow-up), then it's no surprise that Vox will publish a silly piece on Valentine's Day. This kind of stat-mangling is par for the journalistic course. That said, I do think the Vox editors are trying to do their best, I think they're more committed to truth than is David Brooks, for example, so I'll drop them an email and see what they say about this one. It's hardly worth a correction, but maybe next time they can do better and avoid this sort of embarrassing fooled-by-the-press-release story.
P.P.S. Are we just overreacting to a silly Valentine's Day story? I don't think so. The same problems arise in more serious reporting, and we have to grab our examples where we can. Just as the Monty Hall puzzle and the hot hand fallacy fallacy can help us grapple with our erroneous intuitions about probability, so can this Valentine's Day survey help us grapple with erroneous intuitions about statistical variation, intuitions that can affect reporting on politics, science, and economics as well.
P.P.P.S. Some of the commenters seemed to be missing the point here, so let me emphasize: The data are crap and variation is huge. These numbers are essentially nothing but noise. No point trying to interpret the variation in the above graph: the point there was just that all the uncertainty intervals overlap in any case. It was a fun Stan demo and an instance of how some quick statistical analysis can confirm our initial impression that sample sizes are too small to learn anything here. Even setting aside issues of data quality.
I’d be interested to read more about that Gates foundation mistake. If small schools were both the best and the worst, why would they want to encourage small schools (even if they didn’t understand that both the good and bad were statistical artifacts)? Did they restrict their sample to high performing schools and then look to see what they had in common? Anyone know a good link describing their thought process?
I’m suspect the link says and Andrew thinks that the substantial noise in the measurement leads to disproportionate extreme values for small states. Here’s a random assignment of cancer at a 0.5% incidence rate to counties in proportion to their population (2010 census). It’s no surprise that the best and worst are small counties.
State County Population Cancer cases Incidence rate
Nebraska McPherson County 533 5 0.938 %
Texas Roberts County 887 8 0.902 %
Idaho Adams County 3,476 30 0.863 %
Montana Petroleum County 493 4 0.811 %
Montana Powder River County 1,858 15 0.807 %
· · ·
Texas Sherman County 3,186 5 0.157 %
Texas Shackelford County 3,302 5 0.151 %
Colorado Mineral County 831 1 0.120 %
Nebraska Arthur 444 0 0.000 %
Texas Loving County 67 0 0.000 %
Table 12.3: Simulated cancer distribution
Z:
Howard Wainer will know the full story, but it was my impression that the Gates people, or somebody, looked at a list of the best-performing schools and noticed that many of them were small, and then they went from there. . . . ummm, here’s a link: https://www.pdkmembers.org/members_online/publications/Archive/pdf/k0612wai.pdf
The link Andrew provides uses a distribution like the one I posted above to make its point. The source of the graphic there is Gelman and Noldan’s Teaching Statistics.
A recurrent pattern in ed reform philanthropy is that smart billionaires suddenly decide to enter the field to buy themselves some good PR (e.g., Mark Zuckerberg giving $100 million to Newark schools 2 weeks before the biopic “The Social Network” debuted). They assume that everybody who ever thought about improving education before them didn’t have their kind of IQ, so whatever the first or second current fad they hear about when they turn their attention to education is the one they pour money into initially. They don’t have the knowledge to realize there are very few new ideas in education. Most seemingly new ideas have been tried before, with, at best, mixed results. But the billionaires don’t know that. They assume instead that everybody who came along before them in the education reform business must have been an idiot.
Steve:
Indeed, that’s something we’ve been discussing recently with regard to charter schools. Charter schools can be ok but they’re often promising to give a much better education than is given by the public schools. But . . . doing much better than the pros, that’s hard. Lots of motivation to fudge or cheat to deliver the promised goods.
When Bill Gates decided to get into subsidizing education reform after the Clinton Administrations monopoly lawsuit against Microsoft, “small learning communities” was the current cutting edge fad idea. It was often promoted by aging 60s radicals who were now in positions of local power. For example, the Gates Foundation gave a million dollars to former on-the-lam 60s radical Rick Ayers, the brother of Bill Ayers, to reorganize Berkeley HS to allow for more intensive political indoctrination of students in “social justice academies” and the like.
Bill Ayers was in the education fad biz too (he famously got $50 mil from the Annenberg Foundation in the 1990s and recruited Barack Obama to be his figurehead in handing it out), but he didn’t get any small learning communities money from Gates, so he turned against Gates.
http://isteve.blogspot.com/2009/02/bill-gates-admits-hes-blown-2-billion.html
Amount spent on V-day divided by CPI for the state… dimensionless, and relevant to how generous in real terms the gifts were.
One could also include some information about income in the state. I would not be surprised if states with lower per capita income spent less on presents.
Interestingly Idaho is 40th in per capita income ($43K); Maryland is 1st ($70K). Estimates above have Idaho mean at about 70; Maryland at about 60.
Bob
Bob:
You guys are missing the point! (a) The data are crap, we have no idea where they came from and how if at all they were adjusted, (b) Sample sizes are tiny, all the uncertainty intervals overlap. You’re looking at noise.
You’re missing the point Andrew. Your exercise is a “teaching moment”. And, if you’re going to teach people about analyzing data, you might as well include important things in the model, such as the comparison between dollars spent and the cost of some basket of goods (CPI). Which is more relevant than raw dollars.
Daniel:
Sure, doing this adjustment would be fine too. In this case I don’t think it will matter, but it would be easy enough to expand the model to include this additional information. I was really reacting to Bob’s comment which was definitely reading too much into those noisy meaningless numbers.
Well, yes—it is reading too much into noise. But, another way to look at my comment is that, a priori, I would expect the average present in Idaho to be significantly lower than in Maryland.
Their data has the mean Idaho gift at $111; Maryland at $64. Hard to explain.
Bob
Bob:
Ahhh, but the difference is easy to explain, given the small sample size and high variability!
Sorry. I meant “Hard to explain if you believe that the data mean anything.”
Bob
I would argue that a more appropriate scaling reference for measuring love in dollars would be as a percent of discretionary income after monthly bills are paid.
Well, dollars spent/CPI for the locality is a measure of how valuable the gift is, whereas dollars spent/discretionary spending is a measure of how much of what was available to spend was spent… so they’re both interesting and slightly different.
Also, it’d be nice to see the comparison map. I realize that maps are problematic, because size of the state and population of the state are not the same. but the change in the map from raw dog food to cooked dog food would be interesting to see.
Go to
https://source.opennews.org/en-US/learning/distrust-your-data/
for a marvelous discussion and explanation as to why Kansas is an enormous outlier when it comes to porn per capita. Jacob Harris says, “geocoding is often rubbish. What happened here was that a large percentage of IP addresses could not be resolved to an address any more specific than ‘USA.’ When that address was geocoded, it returned a point in the centroid of the continental United States, which placed it in the state of—you guessed it—Kansas!”
Kansas leads in porn per capita as well as in average amount spent on Valentine’s Day per capita in either the original calculation or in the adjustment. Coincidence?
You try living on the prairie. Cattle feed ain’t cheap. Especially Valentine’s Day cattle feed.
In the model there are two sources of variability: the state level, and the country level. If the prior on the country level was so incredibly vague that the states could vary as much as they want, wouldn’t you end up with the original findings?
Anon:
No, the two sources of variability are between respondents within state, and between state. To get the original point estimates, you’d need to have the between-state variance estimated at infinity, which is not consistent with the data. Also, if you did have these point estimates, the uncertainty intervals would be huuuuge, so you would know essentially nothing about what’s going on in almost all the states. No way would the map presented above make any sense.
Here’s some code to recreate the map with the posterior means. Just tack it on to the end of the valentines.R script. Oh and I had to up the adapt_delta parameter to get a good fit, 0.9 worked well.
## map state_mean
require(maps)
require(data.table)
require(ggplot2); theme_set(theme_minimal())
require(scales)
all_states <- map_data("state")
# Align different state names
setkey(all_states, region)
sm <- data.table(region = tolower(state), state_mean)
sm <- all_states[sm]
sm[, SpendFactor := cut(state_mean, breaks = seq(30, 120, by = 15), include.lowest = T, ordered_result = TRUE, labels = paste(dollar(seq(30, 105, by = 15)), dollar(seq(45, 120, by = 15)), sep = '-'))]
ggplot(data = sm, aes(x = long, y = lat, group = group, fill = SpendFactor)) + geom_polygon() + scale_fill_brewer(palette = 'Reds', direction = 1, name = '', breaks = sm[, levels(SpendFactor)], limits = sm[, levels(SpendFactor)]) + coord_quickmap() + scale_x_continuous(name = '', breaks = NULL) + scale_y_continuous(name = '', breaks = NULL)
Three states with ample sample sizes, California, Florida, and Texas, are in the top 7 states. That’s probably not just randomness. My guess would be that Hispanics tend to spend a lot on Valentine’s Day. When I drove by the local high school on Valentine’s Day this month, I was struck by all the students arriving with balloons and flowers.
To the point of your article with Phil, is it that parameter maps of estimates are misleading, or is it that point estimates of estimates are misleading, and we haven’t figured out a good approach to parameter maps that show distributions or at least location and scale?
Yes, I do recall your putting histograms on top of each state in a map in some book or article, but that didn’t look nearly as nice as a chloropleth map. It did use the map effectively as a lookup function indexing into the set of histograms, but I lost the fluid spatial interpretation I may be lulled into thinking I get from parameter maps.
Just stumbled over this, so my comment comes late.
In the shown stan model the sigmas are not actually constraint to be larger than 0 ( is missing in the parameter block).
How much influence did the choice of prior SDs have on the final results?