A couple people pointed me to a recent paper by Josh Terrell, Andrew Kofink, Justin Middleton, Clarissa Rainear, Emerson Murphy-Hill, and Chris Parnin, “Gender bias in open source: Pull request acceptance of women versus men.”
The term “bias” seems a bit loaded given the descriptive nature of their study. That said, it’s good for people to gather such data, even if the interpretation of the results is more difficult than they might realize.
But I’m bringing up this example, not to talk about gender bias or open source, but to introduce a general point about variation.
Consider this table from the paper in question:
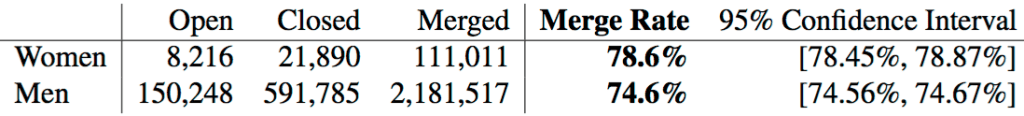
And here’s another:

Presenting estimates to fractional percentage points is silly. “78.6%”? Really??? And even sillier are the confidence intervals presented to the hundredths of a percentage points. “[78.45%, 78.87%],” indeed.
But let’s look at this more carefully. What is so wrong with giving a confidence interval with fractional percentage points? Why, exactly, is this bad practice? After all, N is 2 million here, so we really can be very certain about the proportion from which these data are a random sample.
I’ll give you two reasons why these interval doesn’t make sense. First the easy answer, then the more thoughtful answer.
The easy answer is that the data are not a random sample.
But that’s not the whole story, as we can see by considering a thought experiment: Suppose the data had been a random sample. Suppose Github had a database of a kazillion pull requests, and the authors were given a ransom sample of size 2 million. Then the confidence intervals would be completely kosher from a statistical perspective, but I still wouldn’t like them.
Why? Cos “78.6%” is hyper-precise.
Let me give an analogy. Suppose you weigh yourself on a scale, it records 62 kg. But it happens to be a super-precise scale, of the sort that they use to measure diamonds, or drugs, or whatever. So it gives your weight as 62.3410 kg, with an uncertainty of 0.004 kg. Should you report the 95% confidence interval for your weight as [62.3402, 64.3418]? No, of course not. Two hours later, after you ate lunch, your weight is much different. You’re getting a hyper-precise estimate of what your weight happened to be, right then, that’s all. But for most purposes that’s not what you’re interested in.
Similarly for this Github study.
But then what to do? For weights, you might get an an uncertainty based on your weight at different days and different times of the day. For Github requests, you can break things down in different ways. For example, here are some results for different programming languages:
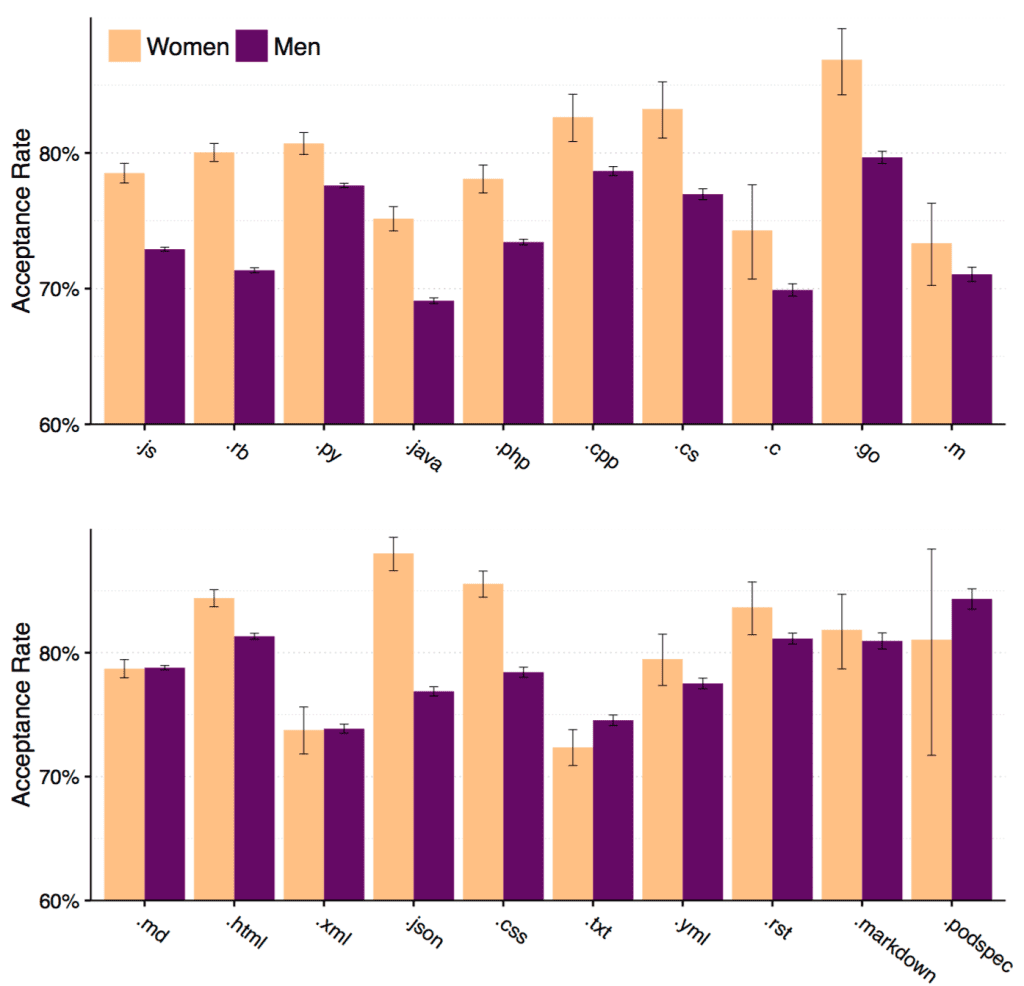
OK, the graph isn’t quite how I would do it. Regular readers know I hate this sort of comb plot; I’d think it would make much more sense as a dotplot or lineplot. But the point is clear: this is the sort of variation that is relevant.
There are other ways of slicing the data: Terrell et al. look at “the mean acceptance rate for developers on their first pull request, second pull request, and so on.” One could also break things down by size of project, by calendar date, all sorts of things.
Does this matter?
Yes, this makes a difference. It’s not just an expression of my aesthetic distaste for too many significant figures. We need to look at real variation in order to get a sense of the relevance of comparisons. For example, an observed difference of 4 percentage points: 79% of women’s pull requests were approved, compared to 75% of men’s. Is 4% a big deal? We can’t answer that by doing this: “This difference is statistically significant (χ2(df = 1, n = 3, 064, 667) = 1170, p < .001)." We need to understand 4% in context. One context is variation by file type. As the above graph shows, 4% is a pretty big deal. Breaking things down in other ways might show a 4% difference to be less interesting.
Here's another:

A difference of half a percentage point? That seems like zero to me. Statistical significance has nothing to do with it. Indeed, what surprises me is not the zero difference but rather how stable these numbers are! I’d expect that if you took just about any two groups—men and women, young people and old people, computer scientists and statisticians, whatever—that you’d see all sorts of big differences in submissions of pull requests, approvals of pull requests, and so forth.
What this means for you
I’m not trying to slam Terrell et al. here. They gathered some interesting data, they put in real work to align the information from pull requests and social media, and they did a lot of analysis. Some of their claims are speculative but they are labeled as such. And they tried to do their best with their statistics.
What they didn’t realize—no surprise, since it’s not really covered in statistics classes or textbooks—is that when assessing the importance of variation, you need some sort of comparison.
Sometimes this is stated this way: Statistical significance is not the same as practical significance.
It’s fine to put it that way but I’d prefer to be more focused. Instead of “practical significance,” I’d like to talk about observed differences (in this case, between men and women) in the context of of other sources of variation, over time, between programmers of the same sex, across programming languages and types of projects, etc. By choosing conventional statistical significance as your standard, you’re letting your sample size drive your analysis, which doesn’t make sense.
Remember Rubin’s question: What would you do if you had all the data?
Scott Alexander wrote a dissection of this study: http://slatestarcodex.com/2016/02/12/before-you-get-too-excited-about-that-github-study/
If reporting “78.6% [78.45%, 78.87%]” is silly, how would you present the results?
“79% [78.5% 78.9%]”?
“79% [78% 79%]”?
“80% [80% 80%]”?
Carlos:
The confidence interval here is essentially meaningless; I’d not give it at all. I’d just say 79% and leave it at that.
Actually, strike that. I’d present the result as a graph, along with other numbers so they can be visually compared. I’d ditch the table entirely.
Isn’t is possible to do a similar “hyper=precision” mistake using graphs too? e.g. Take this graph by Dan Kahan you blogged about recently:
http://statmodeling.stat.columbia.edu/wp-content/uploads/2016/05/everything.png
The graph conveys that you can discriminate between various closely spaced lines. Unless your measurements are of the required precision, can you?
Isn’t measurement error supposed to be automatically accounted for by confidence intervals?
http://stats.stackexchange.com/questions/12002/how-to-calculate-the-confidence-interval-of-the-mean-of-means
Confidence intervals are explicitly about repeated sampling. So, they can’t possibly “automatically” account for all forms of measurement error. They can only account for measurement error that “looks like” a stable random distribution. That might seem pedantic but it isn’t. For example, the “Faster than light” neutrinos from a few years back were ultimately a measurement error (due to damaged cables and drifting clocks etc). Also, even “random” measurement errors that drift in time, or have frequency distributions different from what is assumed in the model are all not automatically taken care of.
+1
This is something that confuses people so much.
That’s where I wish we’d change our communications practices: When I see a confidence interval declared in a report I usually don’t care about merely the narrow statistical interpretation based on repeated sampling. I care about the *actual* confidence that the author honestly has, given what he knows, in his number.
I’m not sure how to technically define the relevant confidence interval but e.g. if your load-cell only has a reported accuracy / repeatablity of 10 kg then any confidence tighter than that in your reported value, irrespective of how many gazzilion samples you took, matters little to me.
Just like with the term “significant” I think we have a schism between the statistical and common usages of “confidence interval”.
Daniel: “explicitly about repeated sampling”
Mostly agree, but would locate it as explicitly about your model for how the data was generated (and summarized/reported).
That is where the “after prior” (or sans prior) uncertainty needs to be adequately/credibly defined.
(Remember reading a chapter in Mosteller and Tukey called “Hunting for the real uncertainty” and wondering why it was the least discussed topic in the statistical literature rather than most discussed. Also, when W.G. Cochran first started writing about observational studies, he did seem a bit startled about how useless standard measures of variability in statistics were.)
Would things be better or worse if they had less data? Let’s imagine they had reported “78.6% [ 78.1% 79.1% ]”. I guess we could also say that 78.6% is silly in that case, and that they should leave it at 79%. Maybe the confidence interval would also be meaningless (but why?). I wonder if there is actually any situation where it would be a good idea to present the results as a table.
Carlos:
I’ve seen very few cases where it makes sense to report fractions of a percentage point.
Understood. I think it may be relevant that in this case, as in the eBay case the other day, we are looking at the mean value of a variable that is a percentage itself. The acceptance rate would be like a winning rate or similar in sports. Taking for example batting averages, even if we thought that having the third digit for each player is hyper-precision it might still make sense to report three digits when looking at the average batting average by season or by league, for example.
The confidence interval is wrong for estimating the average gender difference because it’s not a random sample. Agreed. But if you don’t report uncertainty, how do you know how precise the estimates are?
Would you not care about that, and instead understand the precision in the estimates by looking at variation across gender differences in different subsets of the data?
Yup.
This is some hope that “variation across gender differences in different subsets of the data” will pickup the real uncertainties (but then it only treats it as being haphazard or random).
> A difference of half a percentage point? That seems like zero to me.
I don’t understand what you mean here. If you cut the difference up a bunch of different ways and it’s almost always positive, there’s a difference, and it’s not zero. What do you mean .5pp “seems like zero to me”?
Lauren:
Not literally zero, just close enough to zero to be uninteresting given the variation that we will see across people and across scenarios.
Just wanted to say that, as a lowly humanities layman, I learn more from this blog than I have from most standard textbooks/classes. The analogy of the hyper-precise scale was great. Thank you for taking the time to write so often.
“Statistical significance is not the same as practical significance.”
I make this point to someone at least once a week. Thanks for the excellent post.
Andrew:
I like the lunch analogy, but here’s a variation: Suppose you have a pretty crappy, ancient scale that reads accurate only to 10 kgs & has even very poor repeatability. So even if you didn’t have lunch but just stepped off the scale & on again it might give you an answer different by 10 kgs.
Now you use this very crappy scale to sample a million people each in various nations. \
Is it now acceptable / correct to display a Table “Average weights of People of various Nations” with a hyper-precise (for our crappy weighing scale) one decimal accuracy.
i.e. USA=80.5 kg. Japan=65.3 kg etc.?
In short, does averaging give you a license to claim hyper-precision even when having crappy individual measurements?
In this case the “crappy measurement scale” error, if it is truly random and uncorrelated with the actual weight, will cancel out, and you can indeed get hyper-precise unbiased estimates of group differences with N in the millions. But in smaller samples, you have an unacknowledged source of variation in the data – it’s usually working against you but in low-power settings it can contribute to spurious results (which is why it is not okay to say that “hey, if there was measurement error then my statistically significant result is even better than I said it was.”).
A second consideration is that the precisely measured group difference is not necessarily a measure of a process. Sticking with weights, let’s say Americans weigh 1.325 kg more than Canadians based on massive surveys. It is so easy then to slip into asking “What is it that adds the 1.325 kg to an American over a Canadian?” There is no such process that adds 1.325 at the individual level. What is responsible for that net population difference would be a host of heterogeneous processes and factors, none of which could be measured to anything like that level of precision, which is especially obvious when you think about the intraindividual variation in weight across a week let alone a year. Hyper-precision on the net effect is not the same thing as hyper-precision on the process or reason for the difference.
I think this depends a lot on what you’re interested in. Suppose you’ve got the crappy 10kg scale. And you take a 100.000 +- 0.001 carefully standardized weight and you repeatedly place it on the scale and remove it from the scale, 100 times. After doing this you have a reasonable dataset to fit a measurement error distribution to, and calibrate your scale. It still doesn’t repeat, but you at least understand the way in which it has errors.
Then, you use it to measure cereal boxes, each box gets measured 10 times, and you measure 1000 boxes each coming out of two different factories. Each is supposed to have 100g of cereal in it.
Wouldn’t you be interested if you could detect from these several thousand measurements that one factory is shipping boxes with only 90g of cereal on average? People are getting cheated out of something they believe they’re buying (based on the printed 100g label).
So, sometimes repeated averaging of an inaccurate measurement can give you the precision you need to determine something useful, other times it’s a pointless exercise. The main question is whether the average is really something you care about, or whether the individual measurements are what you care about. It’s no good to know that a manufacturing plant that makes 100kg standardized weights puts out weights that really do have an AVERAGE value of 100kg, you need to know that each individual one has between say 99.999 and 100.001 kg of mass.
I’m a bit puzzled about why you say that the percentages and confidence intervals can’t be from a random sample. One could quibble about sampling biases that might affect the “random” part, sure, but the results they present *are* from a sample, not the complete population, in three senses:
1. They take results from the “GitTorrent” dataset as of “April 1st, 2015”. First of all, it’s not clear how much of Github the GitTorrent project actually covers, and how far back into the past it goes. More concretely, the database only covers *public* Github projects, so they are missing information about pull requests for private projects. (And for pull requests made since April 1, 2015, of course.)
2. They only look at pull requests for which they could obtain gender info by linking emails with Google Plus accounts that had gender self-identification. They mention a total of 4 million users with publicly listed email addresses, which can be compared with the claimed “over 12 million collaborators” that Github advertises.
3. Out of those 4 million, they found linked Google Plus accounts with gender identifications for 1.4 million; the analysis in the paper is largely restricted to that subset.
So I think it’s pretty clear that this *is* a case of sampling from a larger population.
Peter:
We’re in agreement. The data are being analyzed because we are interested in generalizing to other cases. The data are a subset (i.e., a “sample”) from the population of interest. But not a random sample, certainly not a simple random sample, hence the inappropriateness of these confidence intervals.
> We need to understand 4% in context. One context is variation by file type. As the above graph shows, 4% is a pretty big deal. Breaking things down in other ways might show a 4% difference to be less interesting.
I agree with the theme of finding the relevant variation. At the same time, just because there is variation by a grouping variable (e.g. file type) does not mean the aggregate effect (or uncertainty thereof) is meaningless. It could be if the variation was wild (extreme positive or negative depending on group, then just happens to average to say 4%), but that is not the case here. So here and in other cases, we still may desire a measure of uncertainty of the aggregate effect. Indeed, Andrew examines this particular case, and based on the *visual* patterns gender by file type, concludes, “As the above graph shows, 4% is a pretty big deal.” Given that this conclusion of the aggregate effect is made anyway, how do you formalize that process, as in provide a better interval that takes into account variation by the most important grouping variables for which you have data?