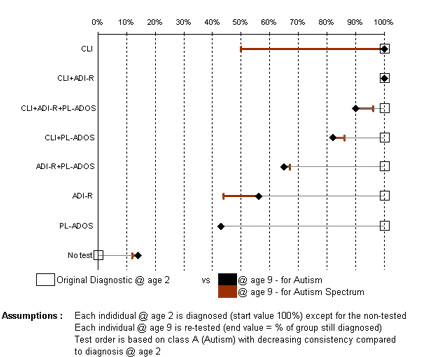
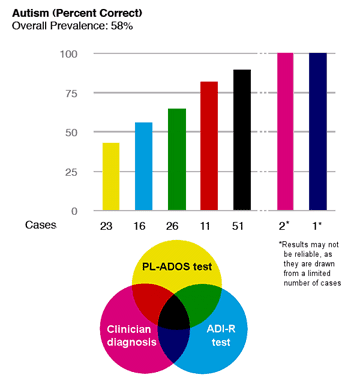
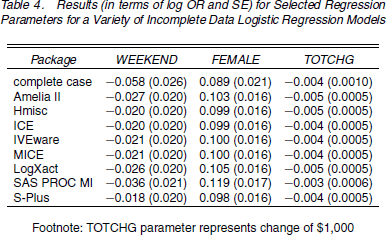
Masanao: Aleks and I did a PCA analysis on 2008 Presidential Election Candidates on the Issues data and plotted the 2 principal components scores against each other and got this nice result:

The horizontal axis is the 1st primary component score; it represents the degree to which a candidate supports Iraq War and Homeland Security (Guantanamo), and opposes Iraq War Withdrawal, Universal Healthcare, and Abortion Rights. The vertical axis is the 2nd primary component score which represents the degree to which a candidate supports Iraq War Withdrawal and Energy & Oil (ANWR Drilling), and opposes Death Penalty, Iran Sanctions, and Iran Military Action as Option.
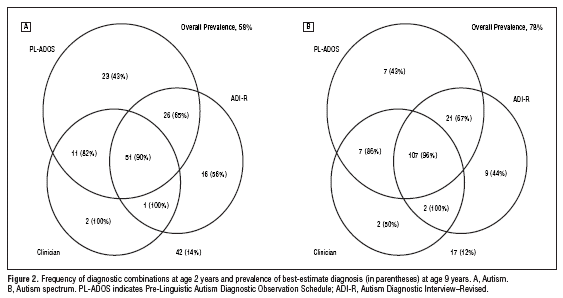
The first principal component is the dividing axis for the Democrats and the Republicans. When we reorder the loadings according to the 1st component we get the following:

So for the first principal component, Republicans generally support red variables and the Democrats the blue colored variables. Ron Paul appears to be the only candidate that does not deviate much from the middle.
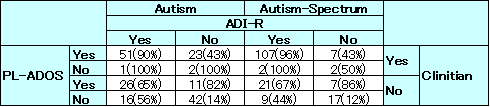
The second principal component is a little more difficult to interpret. Here most of the candidates are clustered around the middle except for candidate Ron Paul who supports Iraq withdrawal, Energy & Oil (ANWR Drilling), Immigration (Border Fence) but does not support other issues.
Here are the loadings ordered by the 2nd component:

Aleks: With the exception of Paul, there is a lot of polarization on the first component. To some extent the polarization is a consequence of the data expressing candidates’ opinions in terms of binary supports/opposes. When a candidate did not express an opinion, we have assumed that the opinion is unknown (so we use imputation), in contrast to a candidate refusing to take an opinion on an issue. When it comes to the issue of polarization: Delia Baldassarri and Andrew have suggested, that it’s the parties that are creating polarization, not the general public.
In fact, I think polarization is a runaway consequence of political wedging: in the spirit of Caesar’s divide et impera, one party wants to insert a particular issue to split the opposing party. This gives rise to the endless debates on rights of homosexuals, biblical literalism, gun toting, weed smoking, stem cells and abortion rights: these debates are counter-productive (especially at federal level), but the real federal-level problems of special interest influence, level of interventionism, economy, health care get glossed over. It just saddens me that the candidates are classified primarily by a bunch of wedge issues. A politician needs a wedge issue just as much as a soldier needs a new gun: it’s good for him, but once both sides come up with guns, the soldier loses. In the end, it’s better for all politicians to get rid of wedge issues every now and then by refusing to take a stance on a wedge issue. In summary, it would be refreshing if the candidates jointly decided not to take positions on these runaway wedge issues on which people will continue to disagree on, and delegate them to the state level, while focusing on the important stuff.
Masanao: Although the candidates’ opinions in the spreadsheet are probably not their final ones, it’s interesting to see the current political environment. If there was similar data on of the general public, it would be interesting to overlay them on top of each other to see who is more representative of the public.
Details of methodology:
We recoded the other/unknown as NA. Iraq War withdrawal was converted into 3 category variable: support -> 3, Supports phased withdrawal -> 2, and Opposes -> 1. Supported before / Opposes now was recoded as opposes.
We used R and pcaMethods package for PCA calculation.The method we used is Probabilistic PCA to handle the missing data.
Since the 4 Democratic Candidate on the left bottom corner were extremely close together, we manually separated them to make them distinguishable so all of the 4 are supposed to be around where “Edwards” is currently at.
Here is the data and the source code. When you run the code it will ask for the data so just tell it where it is.
Raw Principal Component score:
| ?? | PC1 | PC2 |
|---|
| Biden | -1.52 | -0.86 |
| Brownback | 1.32 | 1.13 |
| Clinton | -1.58 | -0.92 |
| Cox | 1.79 | 0.53 |
| Dodd | -1.58 | -0.90 |
| Edwards | -1.58 | -0.87 |
| Giuliani | 0.89 | -1.31 |
| Gravel | -2.34 | 1.51 |
| Huckabee | 1.73 | -0.42 |
| Hunter | 2.38 | -0.15 |
| Kucinich | -2.45 | 1.03 |
| McCain | 0.63 | -0.81 |
| Obama | -1.61 | -0.41 |
| Paul | 0.10 | 2.63 |
| Richardson | -1.54 | -0.66 |
| Romney | 2.25 | -0.33 |
| Tancredo | 2.27 | 0.49 |
| Thompson | 2.08 | -0.76 |








{kind=link}
{kind=link}