As an applied statistician, I don’t do a lot of heavy math. I did prove a true theorem once (with the help of some collaborators), but that was nearly twenty years ago. Most of the time I walk along pretty familiar paths, just hoping that other people will do the mathematical work necessary for me to fit my models (for example, taking care of all the intricacies of implementing differential equation models in Stan, or developing the mathematical tools necessary to derive algorithms to sample from difficult distributions).
Every once in awhile, though, I’m reminded that a baseline level of mathematical expertise allows me (and others with similar training) to see problems from a distance and resolve them as necessary. This sort of mathematical skill can be nearly invisible while it is being applied, and even afterward it’s not always apparent what was being done.
Mathematical understanding can be used not just to solve a well-formulated problem; it also helps us decide what problems are worth solving in the first place.
I thought of this general point after some back-and-forth regarding a recently published article by Anne Case and Angus Deaton on trends in death rates. If you haven’t been following this story on the blog, you can read my recent Slate article for some background.
The study was first summarized as an increase in death rates for 45-54-year-old non-Hispanic white Americans (see, for example, Ross Douthat and Paul Krugman), but after “age adjustment”—that is, correcting for the change in age distribution, standardizing to a common distribution of ages—the pattern looks much different. We then learned more by looking at other ages and breaking up the data for men and women. The biggest part of the story is a comparison to mortality trends in other countries, but I won’t get into that now. Here I’ll be focusing on the U.S. data.
First-order correction
What I want to talk about is the value of a mathematical understanding of different sorts of bias correction, a kind of thinking that is known by many statisticians but is rarely part of the formal curriculum—we learn it “on the street,” as it were.
Let’s start with a first-order bias. Here’s a graph of #deaths among 45-54-year-old non-Hispanic whites in the U.S., based on data taken directly from the CDC website:
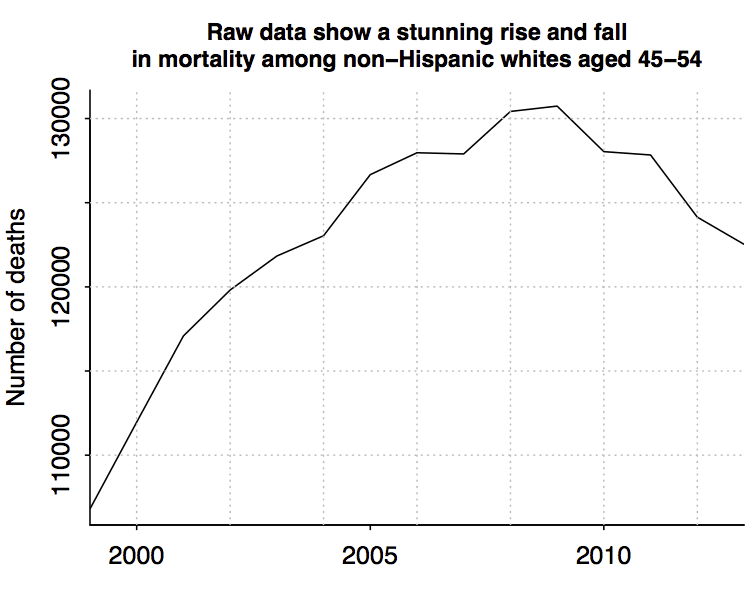
But that’s just raw number of deaths. The population is increasing too. Let’s take a look:

Hey—the population increased and then decreased in this age group! That’s the baby boomers entering and leaving the 45-54 category. Anyway, this population pattern tracks pretty closely to the #deaths pattern.
Looking at trends in number of deaths without adjusting for population is like looking at nominal price trends without adjusting for inflation. It’s a first-order bias, and (almost) everyone knows not to do it.
Second-order correction
So the natural step is to look at changes in mortality rate, #deaths/#people in this group:
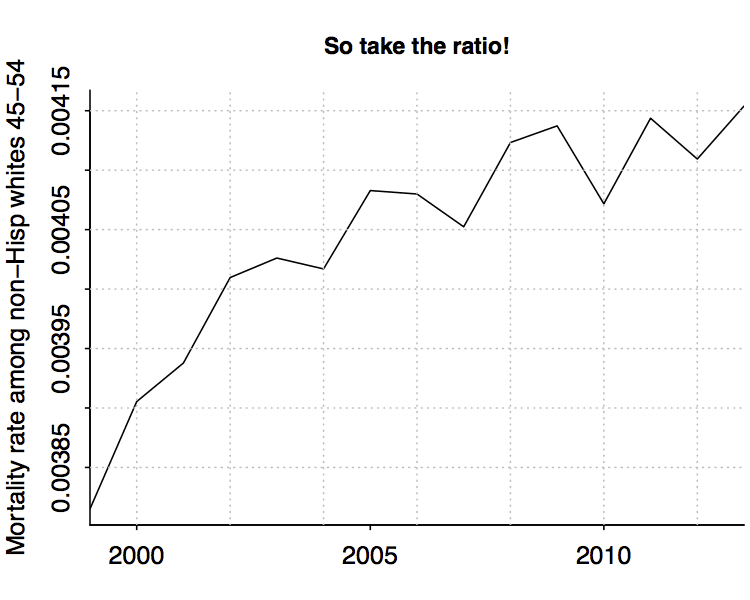
But then we have to worry about another bias. As noted above, the baby boom generation was moving through, and so we’d expect the average age among 45-54-year-olds to be increasing, which all by itself would lead to an increase in mortality rate via the aging of the group.
Let’s check:
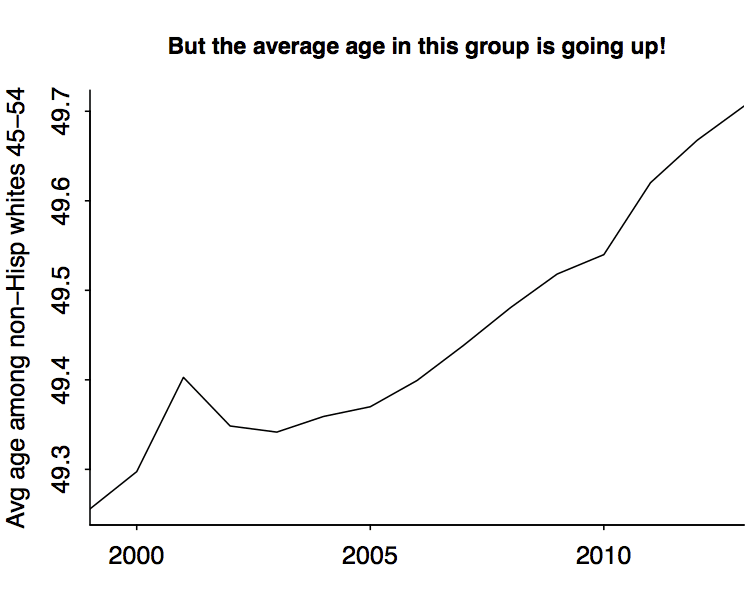
As expected, the 45-54-year olds are getting older. But what’s happening with 2001? Is that for real? Let’s just double-check by pulling off ages from another dataset:
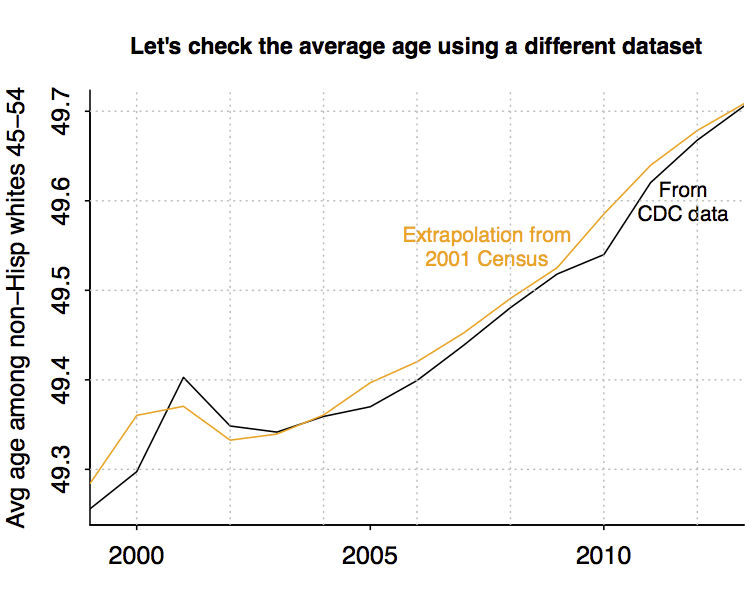
Yup, it seems real. Just quickly, let’s consider 2001. 2001-55=1946, and the jumpiness of the lines at the start of the above graph is tracking corresponding jumps in the number of babies born each year during the 1940s.
OK, the next question is: How would the change in age distribution affect the death rate in the 45-54 category? In other words, what is the bias in the above raw mortality curve, due to age composition?
We can do a quick calculation by taking the death rate by single year of age in 1999, and use this along with each year’s age distribution to track the mortality rate in the 45-54 group, if there were not change in underlying death rates by age. Thus, all the changes in the graph below represent the statistical artifact of age composition:
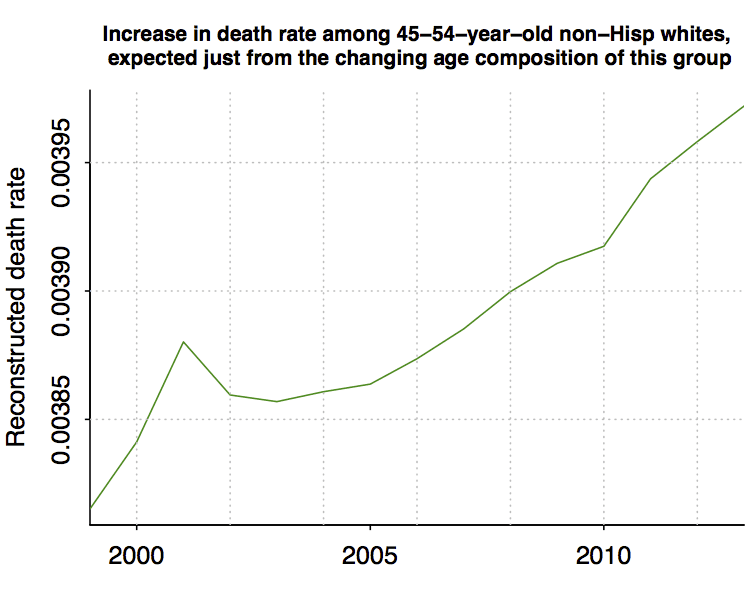
Now let’s line up this curve with the changes in raw death rate:
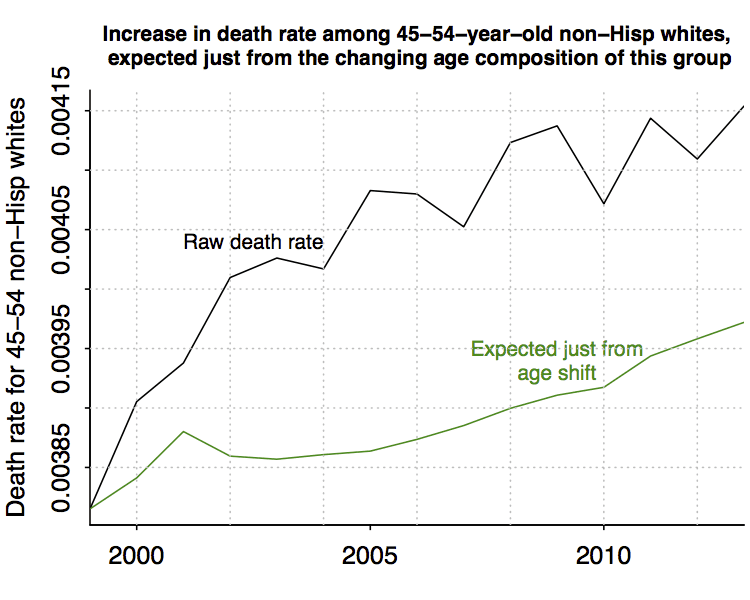
About half the change can be attributed to aggregation bias.
We can sharpen this comparison by anchoring the expected-trend-in-death-rate-just-from-changing-age-composition graph at 2013, the end of the time series, instead of 1999. Here’s what we get:
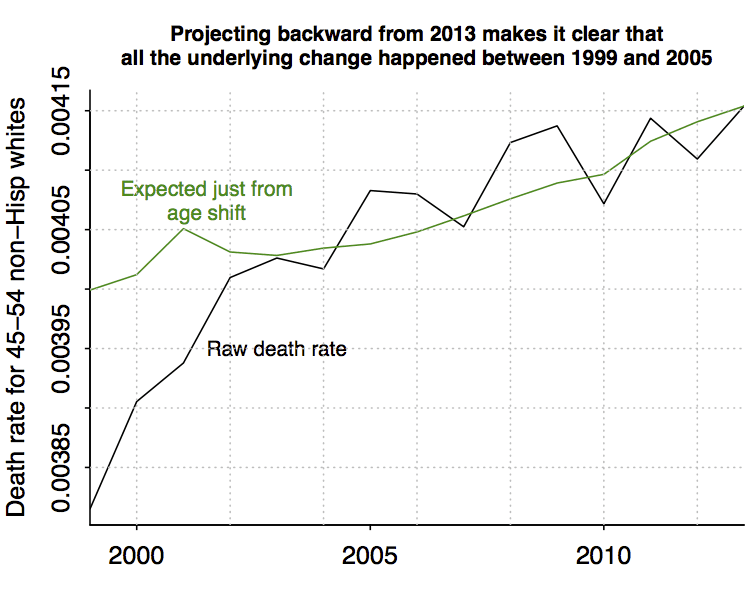
And here it’s clear: since 2003, all the changes in raw death rate in this group can be explained by changes in age composition.
The much-heralded increase in death rates among middle-aged non-Hispanic white Americans happened entirely in the first part of the series.
In summary so far: this adjustment for changes in age composition is a second-order bias correction, less important then the first-order correction for raw population changes but large enough to qualitatively change the trend story.
Third-order correction
Now that we’ve identified the bias, we can correct by producing age-adjusted death rates: for each year in time, we take the death rates by year of age and average them, thus computing the death rate that would’ve been observed had the population distribution of 45-54-year-olds been completely flat each year.
The age-adjusted numbers show an increasing death rate until 2003-2005 and then a steady state since then:

But this is only one way to perform the age adjustment. Should we be concerned, with Anne Case, that “there are a very large number of ways someone can age-adjust this cohort” and that each method comes “with its own implicit assumptions, and that each answers a different question”?
The answer is no, we need not be so concerned with exactly how the age adjustment is done in this case. I’ll show this empirically and then discuss more generally.
First the empirics. I performed three age adjustments to these data: first assuming a uniform distribution of ages 45-54, as shown above; second using the distribution of ages in 1999, which is skewed toward the younger end of the 45-54 group; and third using the 2013 age distribution, which is skewed older.
Here’s what we found:
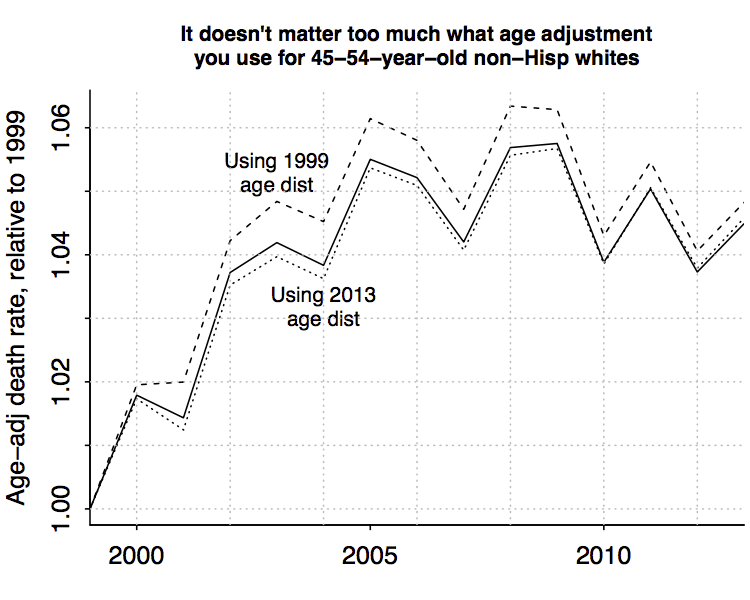
The results don’t differ much, with no change in the qualitative trends and not much change in the numbers either.
It’s important to do some age adjustment, but it doesn’t matter so much exactly how you do the age adjustment. In math jargon, age-adjustment corrects a second-order bias, while the choice of age adjustment represents a third-order correction.
That’s why, when I did my analysis a week or so, I performed a simple age adjustment. Based on my statistical experience and general mathematical understanding, I had a sense that the choice of age adjustment was a third-order decision that really wouldn’t have any practical implications. So I didn’t even bother to check. I did it here just for the purpose of teaching this general concept, and also in response to Case’s implication that the whole age-adjustment thing was too assumption-laden to trust. Case was making the qualitative point that any adjustment requires assumptions; I’m making a quantitative analysis of how much these assumptions make a difference.
Lateral thinking
So far I’ve been focusing entirely on the headline trends in mortality among 45-54-year-old non-Hispanic whites. But there’s nothing stopping us from grabbing the data separately for men and women:
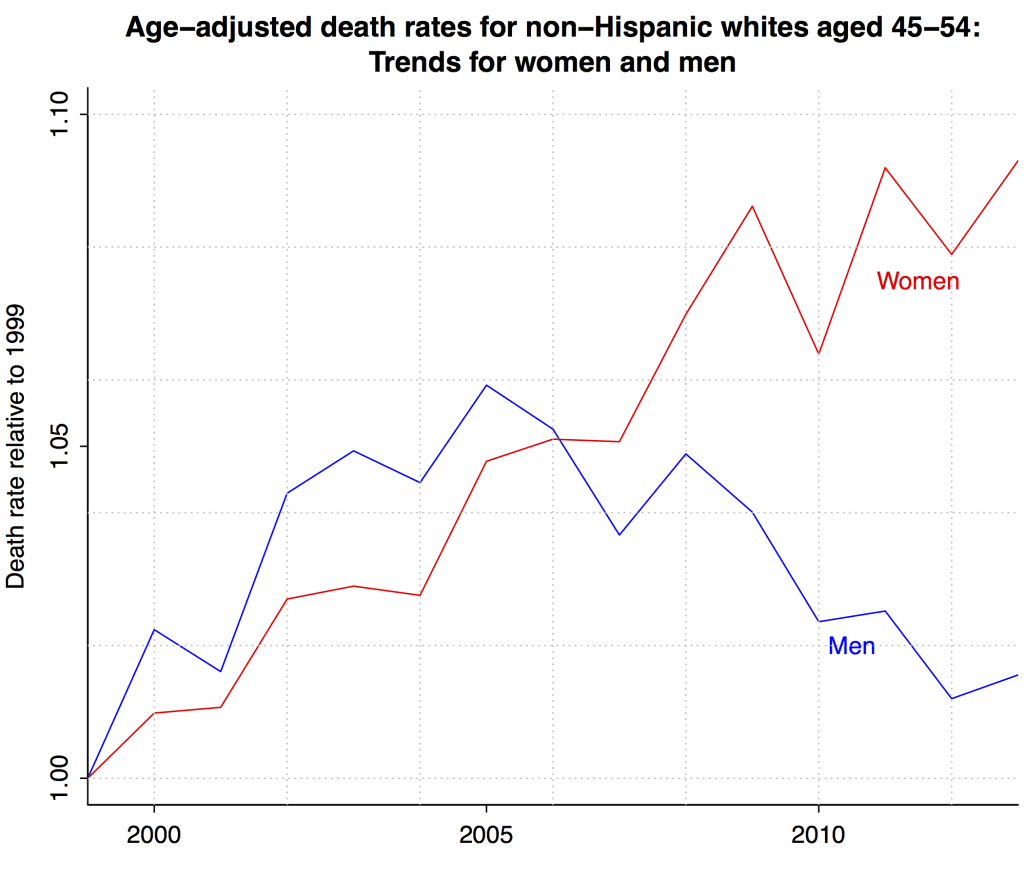
These separate age-adjusted trends tell a new and interesting story. All the bias correction in the world won’t get you there; you have to pull in new data.
To put it another way: Age adjustment was a necessary first step. But now that we’ve dealt with that, we can move forward and really start learning from the data.
We can also look at other ages and other groups; see here for some graphs.
Concerns about data quality
When I first heard about Case and Deaton’s paper, I didn’t think about age adjustment at all; I was alerted to the age aggregation bias by an anonymous commenter. More recently this commenter has raised skepticism regarding the ethnic categories in the CDC data. I haven’t checked this out at all but it seems worth looking into. Changes in categorization could affect observed trends.
Turtles all the way down.
Asking the question is the most important step
As I wrote the other day, the point of bias correction and data inspection is not “gotcha!” Rather, the point of correcting biases and questioning the data is that the original researchers are studying something interesting and important, and we want to help them do better.
And here’s the R script
I put my R code and all my data files here. You should be able to run the script and create all the graphs I’ve blogged.
Warning: the code is ugly. Don’t model your code after my practices! If any of you want to make a statistics lesson out of this episode, I recommend you clean the code. Meanwhile, perhaps the very ugliness of the script can give you a feeling of possibility, that even a clunky programmer like me can perform an effective graphical data analysis.
I have the feeling that Hadley could’ve done all of this analysis in about an hour using something like 20 lines of code.
There’s lots more that can be done; I’ve only looked at a small part of the available data. The numbers are public; feel free to do your own analyses.
Well, sure, it could perhaps be done in 20 lines of code.
But that’s hardly the point, is it? This was exploratory code where you didn’t quite know where you were going until you got there (which is why there were several blog posts on different days).
Exploratory code is almost always messy. That’s why we have production programmers to come after us and neaten up what needs to be run multiple times.
Zbicyclist:
The real point is not so much that Hadley’s code would be cleaner, it’s that:
(a) I think he could’ve done it faster. I’m working with a hand drill and he’s got a power drill.
(b) Messy code can have errors. I think everything I did was correct—as you can see in the above post, I calculated things from various directions and I think this sort of triangulation will catch major mistakes—but I’m guessing that Hadley wouldn’t have to work so hard to check his code.
Yes, not to take anything away from a really well done series of posts, just to reiterate your point
0.0 < P(coding mistake | experienced developer using choice of version control, IDE, and style guide) <
P(coding mistake | skilled practitioner using common scripting language) <
P(coding mistake | some guy did it in excel) <
P(coding mistake | won't even discuss methods) <= 1.0
Of course, the objective isn't always to minimize the probability of a coding mistake, and you won't ever get it down to zero in any non-trivial exercise anyways. But it's a good thing to keep your own level of coding skill in mind (like knowing to put in the cross checks), and to remember that nothing convinces quite as well as transparency.
Yes, well put. There’s also the possibility of deliberately trying to mislead, but we won’t get into that here. Even when the work is done with the utmost sincerity, we get errors. And just as we try to use methods of data collection that maximize reliability and validity, and just as we try to use estimates that minimize variance and bias, we should be using workflows that enhance rather than impede the discovery process.
Who the hell has production programmers? That might be a luxury in certain industries, but not in academia.
Don’t stats departments lend out people to liberal arts departments all the time to get published on the same papers? Why not a collaborate with CS departments?
At some point some stats departments did have “consulting” hours but that has been dying out for a while now. There really isn’t a valid comparison — computer science these days focuses on computation theory not software architecture, so there often isn’t the correct expertise. Not to mention that rarely is there the motivation in the first place if the paper was already written with messy, exploratory code.
Production programmers are not a LUXURY in industry. They are a necessity.
Since the goal of the study was a comparison between countries, shouldn’t you “de bias” all countries data?
It would make sense that all countries exhibit the same bias, so that comparisons between countries will be biased if only one country is ‘de biased’. no?
Sam:
Different countries have different baby booms. For better or worse, most of the discussion of the Case and Deaton paper in the U.S. focused on the U.S. results and so I think we should get these right.
I think it also makes sense to fix the analyses in other countries. Not really my job, but Case and Deaton might want to do it. I don’t know which of these countries has deaths by single year of age, but it wouldn’t be hard to do some sort of approximate bias correction simply using the age distribution of births. Just for example, a quick google gave me this page with births in the U.K. by year. The pattern looks much different from the U.S. There’s a peak in 1947 and then a decline in births through the 1950s.
So, no, it’s not at all the case that all countries exhibit the same bias. Best to correct for the bias in each country, even if only approximately.
The British didn’t have anything much like the sustained American Baby Boom of 1946 to roughly the mid 1960s. There was a quick burst of births right after the war, but times were grim in Britain — food rationing continued into the 1950s — until the economy picked up in the 1960s, by which point The Pill was coming into circulation. The explosion of British pop culture in the 1960s — the Beatles, James Bond, Carnaby Street fashions, etc. — were a reflection of the Brits finally having the money to celebrate.
+1 for this beautiful explaination of the boom of pop culture in UK in those days – reminded me of a great exhibition I saw at the Vistoria & Albert museum a few years ago.
You can see the single year comparisons in Figure 3 at http://analytics.loras.edu/blog/, along with some other assorted factors and commentary.
Dale:
Thanks. I recommend redrawing your graphs relative to the rate at the start of the time series, as I did for the grids of US men and women near the end of this post. Also I recommend high-resolution pdf. As it is, there’s so much variation in each of your graph, and the images are so blurry, it’s hard to see what’s going on at all!
Andrew
The graph isn’t so blurry if you click on it, but admittedly only a cursory overview is possible with so many small multiples. I have another version where I did indeed index things to the 1990 starting value – in fact, I added in smoking rates on that one. I have been wondering whether smoking rates are part of the explanation of the differences between countries. US smoking rates declined earlier than smoking in most rich countries. Indeed, if you index smoking rates to the 1990 value, for most countries the percentage decrease in smoking almost perfectly matches the percentage decrease in mortality (the US is still the outlier). But I abandoned that line of reasoning because contemporaneous smoking and death rates are not really sensible to compare- there is a long time lag between smoking and mortality. Unfortunately, I have not found any data on smoking rates prior to 1990. Perhaps someone knows of a source?
Dale, there’s Preston & Wang (2006) as one example; see pages 634-638 for their description of sources/work-arounds.
http://www.jstor.org/stable/4137209
That’s U.S. data only, of course — gathering similar data for other countries would be a lot of work. There are sources out there (e.g., Funatogawa, Funatogawa, & Yano [2013] for Japan, at at http://www.who.int/bulletin/volumes/91/5/12-108092/en/ f) but if there’s a comprehensive source out there it’s avoided me.
Smoking Prevalence and Cigarette Consumption in 187 Countries, 1980-2012:
http://ghdx.healthdata.org/record/global-smoking-prevalence-and-cigarette-consumption-1980-2012
If you email them, you can get the data for each country broken out by sex and age too. Lots of interpolation, though.
I’ve been following this discussion with interest. And while there are some interesting statistical issues I can’t help feeling that there really isn’t much of a change in the grand scheme of things. Of 1000 people aged 45-54 in this demographic, in a year 4 may have died in 1999 compared to 4 or maybe 5 in 2010. The graphs above have a y-axis scaled to exaggerate this change, and the graphs showing multiple groups side by side in previous posts show a y-axis showing change from baseline which may also emphasize the change. I don’t want to detract from the interesting statistical discussion but I think it may be worth considering.
Sam:
Conditional on the original paper (which reported a small increase in death rates in this group) being newsworthy, I think it’s equally newsworthy that there was no such increase—or more precisely that there was a small increase for women balanced by a small decrease for men.
Arguably none of this should be headline material—but if the original claim was worth all that attention, then I think the fact that it’s not happening should be made clear, too.
P.S. But, sure, much of this continued posting comes from my general attitude that a good way to learn and to teach is by following specific stories in depth, whatever the importance of the topic.
Andrew,
I couldn’t agree more: I personally learnt a lot thanks to this post of yours. As a matter of fact, I had been following your posts on this paper, which have been also linked by other statistics-themed blogs. However, up to now I hadn’t really understood the discussion, because I didn’t know how to remove this aggregation bias in practice, what “assuming a uniform age distribution” exactly meant in this context, and so on. Thanks to your hands-on, step by step explaination, I’mean now understanding both the problem and the solution. I’m still studying the post, but I think it is directly related to a problem in my job. So thanks again for taking the time to lay this down.
I think that’s a good strategy.
In general, on blogs, comments etc. there’s too much abstract arguments & espousing of philosophy & hand waving but too little practical, specific, get your hands dirty sort of posting.
I really like this post for several reasons. First, the didactic approach with which you lead us along your own thought process. Second, the visual presentation. Third, the quote “a baseline level of mathematical expertise allows me (and others with similar training) to see problems from a distance and resolve them as necessary.”
The concept of first-, second-, and third-order corrections are immensely valuable throughout applied math and statistics, and as you’ve shown here they can also guide exploratory analysis. From interpolation schemes to numerical solutions of integrals (the trapezoid rule versus Simpson’s rule), often a good way to understand a problem is to start with a simple first-order method. After the basic ideas are clear, you can more to higher-order methods IF there is reason to suspect that more accuracy is required or that the simple method is, well, overly simplistic.
Rick:
Thanks. One thing that motivated me to write this post was that interview with Case, where she first downplayed the need for any adjustment at all, and then implied that she wouldn’t trust just any adjustment because different adjustments would give different results. This suggested to me that she hadn’t internalized the idea of different orders of correction. On one hand, yes, the age adjustment here is a second-order correction so I could see how at first glance she hadn’t thought it necessary. But uncertainty regarding the age adjustment is third-order; it can’t trump the need for the correction in the first place.
Economists are of course well trained in mathematical methods, but it struck me that this was an example where the idea of different orders of correction—something that statisticians learn “on the street” by hearing people talk about it—was powerful. It was an intuition I had here that I hadn’t even realized I was using, until I was careful about writing it all down.
Nice post! My ‘well actually’ contribution is – actually you are thinking qualitatively, just in the manner that mathematicians think qualitatively. You’re constructing asymptotic approximations of increasing order and using ‘analysis’ style thinking – more inequalities than equalities. And you’re focusing on the key features preserved under variations – quite topological style thinking!
What I really like about this analysis is this. As I was reading around about adjustment some of the textbook type advice on line was that for 10 year groups adjustment wouldn’t matter much and probably isn’t worth doing. But, in fact, it does matter, these small changes in mixtures have potentially important ramifications in looking at data. Just like other small, seemingly meaningless shifts become very important. And just to show how everything is connected, it’s just like low probability events are not the same thing as 0 probability events, and if you are doing risk analysis you better never forget it (or assume that because one low probability event happens that another one won’t happen at the same time).
Elin:
What stunned me when i reread the Case and Deaton paper was this line: Their numbers “are not age-adjusted within the 10-y 45-54 age group.” So they thought about age adjustment and decided not to do it! I have no idea why, but this perhaps gives some insight into why they have been so defensive about the whole thing.
One suggestion I’d make is that age-group graphs are hard to wrap your head around since the individuals in, say, the 45-54 year old cohort keep changing over time, so other ways to graph the data might be helpful in pattern recognition.
Also plotting the graphs with the average birthyear of the 45-54 year old cohort could be informative, since Americans are pretty well informed about generational trends among white Americans.
A bigger change would be to plot the average death rates for a single birth era cohort over time.
I don’t know if either change would drum up improved hypotheses, but they might.
You raise a useful point about the importance of age-adjustment even within age classes, but essentially the upshot is that while the crude numbers suggest the death rate for 45-54 year old non-hispanic whites is increasing at a decreasing rate, the age-adjusted numbers show an increase followed by a steady state. Either way, that doesn’t sound like good news. One might even characterize the disagreement as academic.
Notmarkt:
Yes, as I’ve emphasized throughout, the big story of the Case and Deaton paper is the comparison to other countries and other groups, and those comparisons stand.
Of course given that my full-time job is college professor, you shouldn’t be surprised that I think “academic” work is valuable.
As a statistician I like to get the numbers right. I can allow others to make the interpretation. In this case I will just say that various interpretations such as those of Krugman, Douthat, etc., were explaining what they thought were steady increases. Actually no increase for 10 years, actually an increase for women and a decrease for men—that’s a different pattern.
I’ve seen this attitude that “getting the numbers right doesn’t really matter” is quite popular, which is rather depressing. Trying to explain inaccurate numbers with imprecise theories is a great way to get zero advancements in a field for 1500 years (eg Ptolemy to Brahe). Accurately describing the data is not an academic exercise, without that you get pseudoscience and proliferation of wild speculations as people try to understand nonsensical evidence.
+1
I share the concern about taking care to get the numbers right. Perhaps imagine the mea culpa that Case-Deaton might pen for you based on your initial rough-and-ready claim of no increase:
http://statmodeling.stat.columbia.edu/2015/11/06/correcting-rising-morbidity-and-mortality-in-midlife-among-white-non-hispanic-americans-in-the-21st-century-to-account-for-bias-in/
Noah Smith: “Gelman is dramatically overstating the importance of what he found! To say that the increase in death rates “isn’t actually happening”, first of all, is not quite right – Gelman’s rough-and-ready composition adjustment removes all of the increase, but more careful examination shows that some portion of the increase remains.”
http://noahpinionblog.blogspot.com/2015/11/gelman-vs-case-deaton-academics-vs.html
You’ve certainly moved the ball forward by showing that the rate increase was short-lived (although the inflection point is uncertain considering uncertainty about the age-adjustment) and focusing attention on sex differences within the demographic. BTW, I imagine Krugman could readily conjure up a partisan “just so story” to explain the leveling off – hope if the inflection precedes 2008 and change if thereafter.
Notmarkt:
I think we’re basically in agreement here. In my post that you link to, I wrote, “After we correct for this bias, we no longer find an increase in mortality among whites in this category. Instead, the curve is flat.” I could’ve added “since 2005.” I think “isn’t actually happening” is correct given that I was referring to the present tense.
In any case, the patterns among U.S. non-Hispanic whites are still notable in comparison to other countries and other groups. Moving the ball forward is all I’m trying to do here; as I wrote the other day, Case and Deaton got the game going, which is the most important step.
My question would be:
If the effect size is so large and obvious, do you really need to fine tune and age adjust numbers?
My sense is if you are simply pointing out a massive disparity between groups (i.e. substantial obvious declines in mortality for foreign peer groups and no noticeable US decline– with possible increase– in mortality) then you don’t need to fine tune. It depends on your goal.
I suspect the apparent (but not real?) conflict between AG and Case-Deaton is due to different goals.
Cheese:
I think no big conflict. But the Case and Deaton paper did begin, “This paper documents a marked increase in the all-cause mortality of middle-aged white non-Hispanic men and women in the United States between 1999 and 2013.” And this statements are not really true: for men, it was an increase followed by a decrease, not a “marked increase.” As I’ve emphasized throughout this discussion, the main finding of comparison to other groups and countries still holds up. But when the first sentence in a paper is wrong, it’s worth a correction.
In an ideal world, Case and Deaton would’ve done the age adjustment right away, then their paper would’ve been more clearly focused on the comparison, and that would’ve been fine. As it is, they slightly overstated their claims and so a correction was needed.
As to the fine-tuning: Those third-order corrections, comparing different age adjustments, really aren’t needed. I just did them in response to Case’s apparent distrust of any age adjustment because of this sensitivity. I thought it was worth pointing out that these third-order effects are really minor and that it would be mistake to just use raw numbers, just cos different adjustments give very slightly different results.
Thanks… I guess this is kinda feels par for the course in economics.
If someone ‘only’ slightly overstated their claims in econ, it feels like progress to me. I’ve gotten used to people wildly overstating claims in econ, particularly when looking at macro level considerations…
>simply pointing out a massive disparity between groups”
Cheese, the disparity isn’t that massive, it is equivalent to shifting age-specific mortality rates by a few years. The largest discrepancy in 2013 was between US whites and Sweden, this is about the same as between age 50 and 45 year old US whites.
I wouldn’t be surprised if fine tuning can account for the entire difference between countries. Especially after learning that a huge percentage of race and hispanic origin information is being determined by a process amounting to using the last digit of the death certificate number. This is used as a random number, with the lower values assigned to white.[1]
Are certificates due to suspected suicides/overdoses filled out earlier/later in the day/week? Or maybe people fill them out first for those who die in a hospital vs elsewhere. Is it somehow related to socioeconomic class? Until, we have some idea of how accurate this process is, it is extremely bad news for the race and hispanic origin info.
Anyway what is the purpose of pointing out a disparity if you are not going to later attempt to explain and do something about it?
[1] http://www.cdc.gov/nchs/data/dvs/Multiple_race_docu_5-10-04.pdf
hmmm… some interesting points.
1) “the disparity isn’t that massive, it is equivalent to shifting age-specific mortality rates by a few years.”
I feel like I’m looking at the wrong graph here or we are referring to different things… I’m looking back at the original graph in http://statmodeling.stat.columbia.edu/2015/11/06/correcting-rising-morbidity-and-mortality-in-midlife-among-white-non-hispanic-americans-in-the-21st-century-to-account-for-bias-in/
and seeing death rates approx. cut in half in peer countries but approx. flat in the US (after adjustments) over ~ 2 decades. (I know the original graph is scaled arithmetically, but I am thinking about it geometrically.)
2) Using the last digit of death certificate as a random number, definitely is quite interesting. It caused me to dust off notes on Benford’s law, which I then I failed to apply here. I’m a bit skeptical about this impacting the conclusions, but I am probably even more appreciate of some of the challenges in constructing pseudo-random number generators, so I don’t know… this is interesting.
3) “Anyway what is the purpose of pointing out a disparity if you are not going to later attempt to explain and do something about it?”
I recognize that this is the way most people think about politics and economics but I cringed a bit when I read it. High level, I’ve become quite skeptical of explanations that aren’t explicitly tied to useful predictions. I’d like it if people seize on things with large effect sizes and think about them, generate multiple hypotheses (solutions), including (a) “i don’t know” and (b) some generated from AI applications and basically one way or another they find sub-markets and groups to test them in. Barring that, at least generating many hypotheses and submitting them to decision markets / Tetlock’s Superforecasters, would be of interest.
1) Check out figure 3 from here: http://www.cdc.gov/nchs/data/series/sr_02/sr02_148.pdf
Using their methods of correcting for death certificate misclassification they shift the hispanic/non-hispanic mortality ratio right by 10 years in the range we are looking at. I didn’t look closely at was going on, so do not vouch for those methods. This is just to get an idea of the magnitudes we are talking about relative to the sources of error.
2) I agree, this is very interesting. I have been unable to find out how these death certificate numbers are generated (who/when/how/where), so to me the race and hispanic origin categories are essentially a black box. In my experience people like grouping things into sets of ten, they also like performing tasks in some rational sequence (eg hardest to easiest, longest to shortest). Also there will be correlations in race estimated between adjacent death certificate numbers, whatever that may mean. But the choice of random number may be less important than how they are using “county of residence and other covariates”.
3) I don’t really follow here. If you are going to model something and make predictions you will want accurate estimates of any effect sizes rather than just knowing there is a discrepancy.
3)
I have a question for Andrew. All the data published here (and by casey/Deaton) are based approximately on the CDCwonder that shows data from 1999. How do we know that it is a correct datum for making any sort of conclusions. I can extract on an annual basis the data from CDC, but not to that fine detail, and it appears that 96-99 is a low point for white death rates. Can you give me some idea of what would happen if you extend back the data to, say, 1980, and would the 2000-2005 also be an artifice. I attempted to do such an analysis but failed because big blocks of data are unavailable.
In your linked slate piece, you write, “The number of births in this country increased from 2.9 million in 1945 to 3.6 million in 1950 and peaked at nearly 4.3 million in 1959,…”
I am of the 1957 birth cohort, and I have long heard that that year had the most births in the US until then and for some years after: it may still hold the record for all I know (see below).
The chart that you link to there seems to show that the birth rate peaked a bit before 1959, perhaps 1957. Furthermore, this table, ostensibly from USDCommerce data, does indeed indicate that 1947 was, is and may it ever be so, the reigning champ of births in U.S History.
’57! ’57! ’57!
The moral of the story: statistician, check yer data before describing it!
PS: I don’t know if my embedded links will survive pressing the submit button, so I am listing them in order below:
http://www.slate.com/articles/health_and_science/science/2015/11/death_rates_for_white_middle_aged_americans_are_not_increasing.html
http://www.pewresearch.org/fact-tank/2013/09/06/chart-of-the-week-big-drop-in-birth-rate-may-be-levelling-off
http://www.bbhq.com/bomrstat.htm
And the moral for this commenter is “Commenter, read yer comment before pressing submit!”
That should have been, “does indeed indicate that 1957 was, is and may it ever be so, the reigning champ of births in U.S History.”
Jeez!
Also, on another point:
“Economists are of course well trained in mathematical methods, … ”
Speaking as an economist, “Yes, but …”
Except when we want to linearize something because analytic solutions are not possible (e.g. a DSGE model), we rarely have any feel for 1st order vs. 2nd order importance; I suspect that that shows up as well in our solution methods for DSGE models, which are better explained less as a good feel for relative orders of importance than as “This here lamppost has a nice bright light on it; let’s hope the answer (like the pony) is somewhere around here.
I really like this as example of how these kinds of corrections are really just about fitting better models and examining the error.
First the constant model (no model). Then a model that number of deaths is proportional to the population size in the age group. Then a model involving population size and age. Along the way, examining the residual by age. Then not expanding the model, but learning something by looking at the error in a more nuanced way (breaking it out by gender too).
The model is just to factor out the effects you’re not interested in. You don’t need the model for the part you are interested in – the “model-checking” step is enough.
(Apologies if this point is too obvious for words! But I like how it unifies these kinds of ‘corrections’ with a bunch of other stuff we talk about.)
This is a great point.
Wait… so something is going on that’s weird about American white 45-54 year olds. After all the data manipulation, complicated by a 10 year age binning, it looks like it’s turning out to be an artifact of the US baby boom … except for females. (seems weird that the baby boom didn’t affect blacks, did they not have a similar baby boom shape?). Have all the sub-cohorts being treated the same at every stage of correction? Where is the data that you’ve been re- calculating on? (I’ve been looking for Case and Deaton’s and can’t find theirs, and the link to the data from the CDC is not necessarily the selection they made)
Mitch:
In my post I linked to a zipfile with the data and R script.