Mark Girolami sends along a new paper by Francois-Xavier Briol, Chris Oates, Michael Osborne, Dino Sejdinovic, and himself. The idea is to consider numerical integration as a statistical problem, to say that the integral being estimated is an unknown parameter and then to perform inference about it. This is related to ideas of Xiao-Li Meng, also in some general way related to the calculus of variations, I think.
In reading it I was also reminded of a remark of Don Rubin’s from many years ago, when he said that he considers whatever approximation he is currently using to be his posterior distribution. Rubin’s remark made sense to me, but I’ve always worried about the overfitting problem. Suppose, for example, we fit a big Bayesian model but using a crude, mode-based approximation. The posterior mode could well overfit the data, which then would not show up as a problem in a posterior predictive check. The usual Bayesian answer to the overfitting problem is that if you overfit you’ll get big standard errors, but that won’t happen if your approximation or simulation algorithm doesn’t fully explore the posterior distribution.
Anyway, that’s a bit of a side point, it’s not a criticism of the linked paper by Briol et al., of which I think this is the key passage:
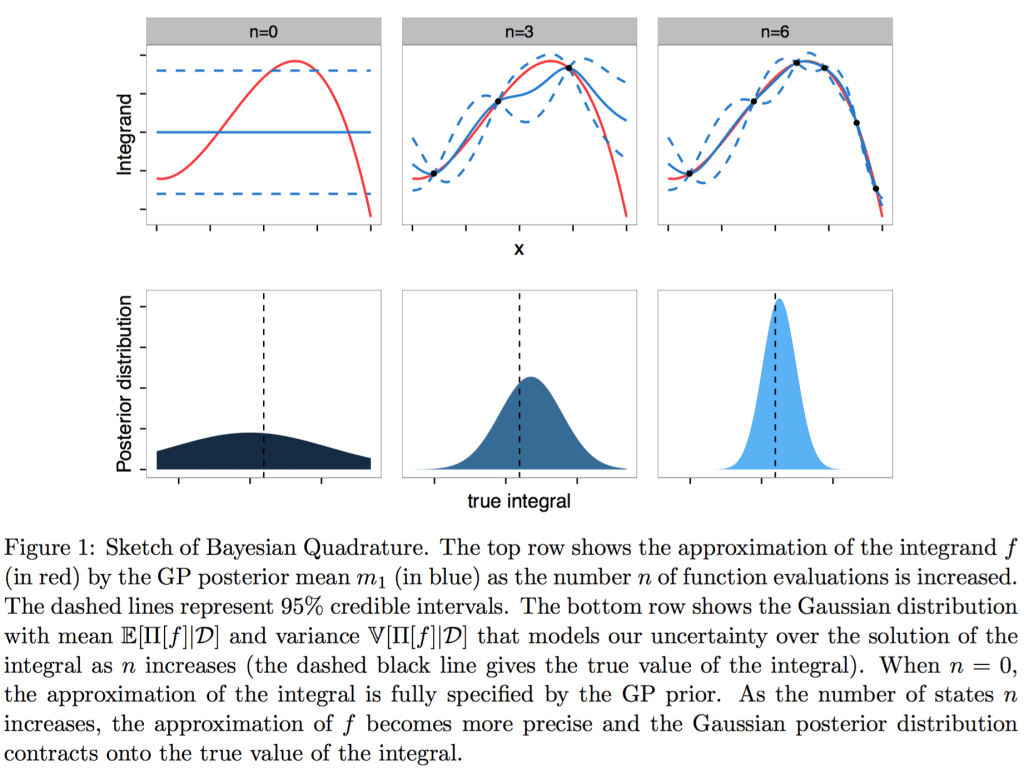
Bayesian Quadrature (BQ; O’Hagan, 1991) is a probabilistic numerics method that performs integration from a statistical perspective. Specifically, BQ assigns a Gaussian process prior measure over the integrand f and then, based on data D = {xi,fi}ni=1 with xi ∈ X and fi = f(xi), outputs a Gaussian process posterior measure f|D according to Bayes’ rule. In turn this implies a Gaussian posterior distribution over Π[f], since Π is a linear functional in f, representing a probabilistic model for uncertainty over the true value of Π[f]. The approach applies equally to a pre-determined set of states {xi}ni=1 or to states that are realisations from a random process, such as samples from a probability distribution which is often, but not necessarily, Π. In the latter, randomised case the method is known as Bayesian Monte Carlo (BMC; Rasmussen and Ghahramani, 2002).
Compared to non-probabilistic integrators, BQ has lacked rigorous theoretical foundations; this is addressed by the present paper.
So I guess that’s the point—they have some convergence proofs for this approach in which integrals are computed by fitting an underlying Gaussian process.
They also write:
The performance of probabilistic integrators is guaranteed to be no worse than non-probabilistic integrators and is, in many cases, asymptotically superior.
I assume when they refer to “performance,” here, it is scaled by number of iterations or number of simulation draws, not by wall time. I’d think that fitting a Gaussian process could be time consuming.
In any case, I think this is a valuable perspective. I agree with their basic idea that computational problems should be framed statistically.
Wow. I hadn’t seen this before. I like it.
Off-topic: I came across “Sloppiness and emergent theories in physics, biology, and beyond” last Friday – http://scitation.aip.org/content/aip/journal/jcp/143/1/10.1063/1.4923066 My initial take, based on a quick review, is that the authors have discovered truths well-known in other fields, e.g., low effective dimensionality and low-d manifold structures in data. Again, that’s based on a quick review not a detailed read. Also, model selection addressed extensively and they allude to Bayesian methods in Section VI but don’t specifically address them. Perhaps I’m not seeing the forest for the trees. Thoughts?
Chris:
I followed the link and read the abstract and saw this:
This pretty much rules out any relevance to any problem I’ve ever seen. In the problems I’ve worked on, we sometimes have simple data, but there’s never any simple hidden theory. But I suppose physics is different.
This is truly puzzling for me too (see if that paradox makes sense at all): why are the rules of physics so simple but the actual configuration of particles so complex? Is there anything any statistical principle can explain? I mean, from the anthropic point of view, it seems to me we might as well have had a super complex system of rules and only handful of particles generating life and the universe.
Is this a related idea to conventional Monte Carlo integration?
Been a while but I think the basic idea was outlined in this paper.
Sampling from Gauss Rules
M. Evans and T. Swartz
http://epubs.siam.org/doi/abs/10.1137/0909066
I really like this paper. In the land of “probabilistic numerics” papers, I think it’s my second favourite (after the one on solving ODEs that Mark Girolami and Patrick Conrad wrote).
That being said, there are a few traps in the paper.
– The contraction bounds say that, asymptotically, the credible region is *at most* the same size (order of magnitude) as the actual error. Except in the case where the bounds are minimax (given that they miss by a whole “Monte Carlo”, Bayesian MC does not hit this rate!), this means that the credible regions can be much too narrow to quantify risk appropriately.
– I’m not sold on the epistemic uncertainty argument. Given that the authors jettison it as soon as things get complicated (see for example, section 2.2.1 and the associated footnote, where they specify the wrong GP prior [i.e. the one that doesn’t represent their knowledge], or the section on control functionals and the associated example, where they are unable to interpret the RKHS and the a priori assumptions about the epistemic uncertainty, so they just jettison it and use the mean.). Without the uncertainty, BQ basically reverts to known numerical quadrature schemes.
– The means of these models form known quadrature schemes which are commonly used because numerically, calculating the optimal weights w = K^{-1}z is hard. These types of linear systems have an awkward tendency to be exponentially ill-conditioned, which limits the achievable accuracy and forces us to use much more expensive solution methods than the usual solve(K,z).
– I don’t buy the argument that the probabilistic interpretation adds new things to the existing deterministic RKHS integrations schemes. They have a complete theory based on the idea that “f \in H”. This paper claims, incorrectly (and they know this because there’s a footnote), that this is roughly the same as f is a priori a GP with covariance function K. The prior knowledge encoded in that prior is more of the form that “if I see i.i.d. measurements of a “smooth enough” function, the posterior mean will be in H”. Draws from the posterior will be rougher (they will have d/2 fewer square integrable derivatives). I can’t really see that this assumption is easier to follow than the simple “what are the optimal weights under this assumption” route that has been traditionally taken. So the power of this method comes in using the posterior, which really calls for the sequential or Frank-Wolfe BQ, which they weirdly (and again, probably incorrectly) dismiss being “matched in terms of accuracy by a [non-adaptive] quadrature rule”. I can’t imagine this being true – minimax rates have to do with worst case over all potential integrands, whereas adaptive quadrature only works on one specific integrand. For that to be true, the worst case error must be attained by every function in the RKHS, which strikes me as unlikely.
– My favourite result in this paper is Lemma 1, which strongly suggests that there is very little to lose by re-weighting, for example, Monte Carlo samples. They even give an optimal (but maybe hard to compute exactly) weights. It would be fun to see exactly how well you have to solve that linear system in order to still get a meaningful improvement…
I actually mis-remembered the result about poor conditioning. (it’s still bad, but there are smoothness assumptions!). I learnt about all of this from the Radial Basis Function literature, that usually uses infinitely smooth functions, so exponentially large condition numbers occur. It’s only polynomial (with a power depending on dimension) if you use a Matérn Kernel. So, by the usual rule-of-thumb, a Matern with smoothness nu will have lose up to O(d*log_{10}(1/h)) digits accuracy, while an squared-exponential covariance function will lose up to O(d^2/h^2) digits. (Here d is the dimension and h is the minimum distance between two points in the interpolation set.)
This turns out to be the standard story for these sorts of things – GPs with infinitely smooth sample paths are numerically catastrophic, whereas there is more hope with limited smoothness.
The paper “Error estimates and condition numbers for radial basis function interpolation” by Robert Schaback has details.
I think by “performance” they mean quality of the integrand: “The performance of quadrature rules is usually quantified by the worst-case error”