Just like the original Jaws 2, this story features neither Richard Dreyfus nor Steven Spielberg.
It all started when Dan Kahan sent me the following puzzle:
Match the resonses of large nationally representative sample to supporting these policy items.

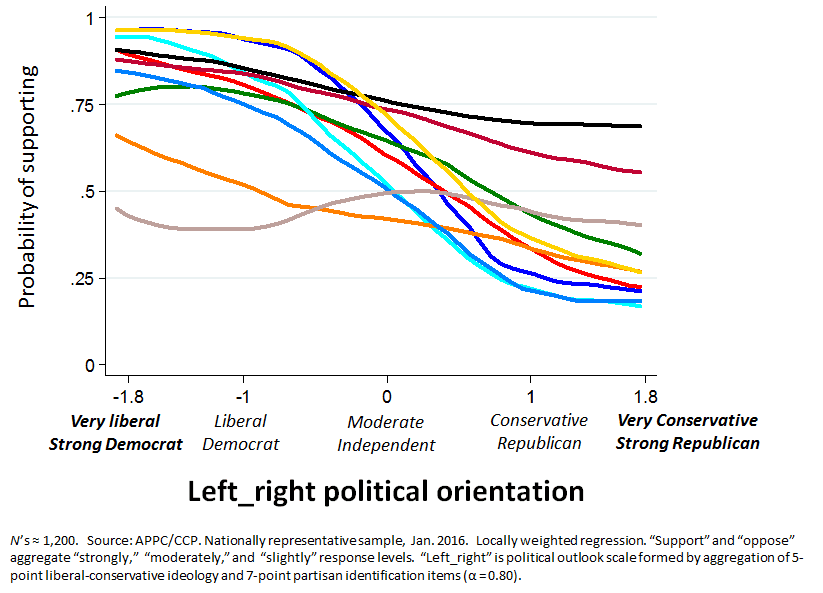
I let this languish in my inbox for awhile until Kahan taunted me by letting me know he’d posted the solution online.
I let it languish a bit longer and then one day Josh “Sanjurjo” Miller was in my ofc and we decided to play this latest game of MAPKIA. How hard could it be to match up the opinion items with the data?
Not so hard at all, we thought. We spent about 10 minutes and came up with our best guess. We attacked the problem crossword-style, starting with the easy items (sports betting, vaccinations, legalized prostitution) and then working our way through the others, by process of elimination.
But before I give you our guesses, and before I tell you the actual answers (courtesy of Kahan), give it a try yourself.
Take your time, no rush.
Keep going.
Scroll down when the proctor declares that the exam is over.
If you finish early, feel free to click on the random ass pictures that I’ve inserted to prevent you from inadverently spotting the answers before completing the test!
Time’s up!
Okay, here’s what I’m going to do. First, I’m going to start by showing you our guesses. Second, I’m going to show you the “answer key,” which consists of the original figure (actually, Kahan changed around some of the colors, I have no idea why) with labels.
OK, here’s what Josh and I guessed:

And here’s what the survey said:
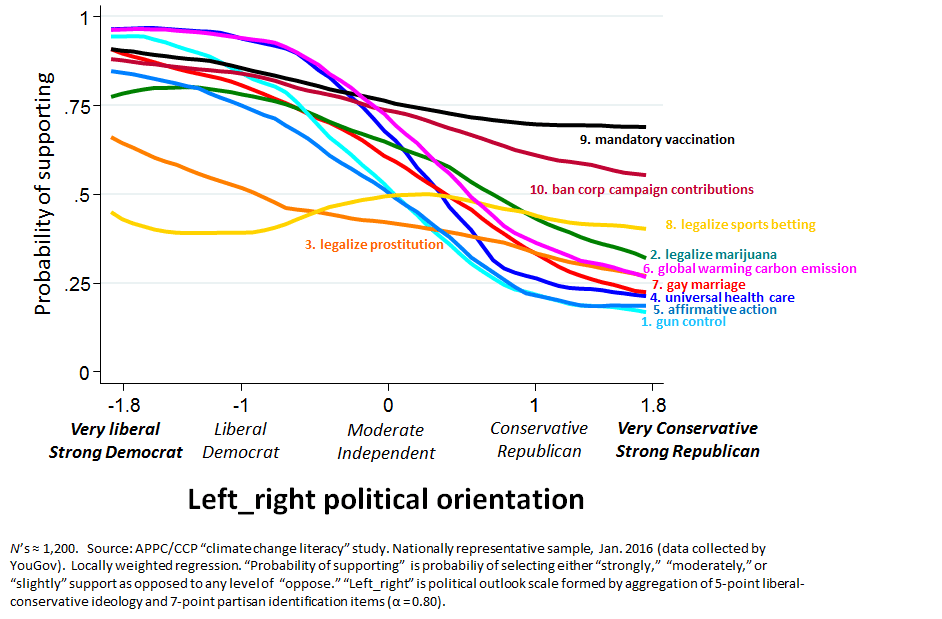
OK, as I said, it’s tricky to do the scoring because Kahan switched some of the colors on us, but if you go back to the top image and compare, you’ll see that we got 8 out of 10 correct! The only mistake we made was to switch #4 (“universal health care”) and #6 (“global warming carbon emission”). And, as you can see those two curves are pretty damn close.
8 out of 10! Pretty good, huh? Especially considering that we couldn’t get 9 out of 10 since we knew that each item lined up with exactly one curve. So we made only one mistake.
Indeed, if you go with Kahan’s absurdly complicated scoring scheme, we got a perfect score of 14.75!
Josh and I high-fived each other (literally) when we found out we’d done so well. But then I thought . . . hey, I should be able to do well on this sort of quiz. After all, partisan polarization of U.S. public opinion is supposed to be my area of expertise.
Still, I’ll take the win.
> my area of expertise.
OK – so experts who do well – will blog about it ;-)
What if any policy positions, in your expert experience, would you hypothesize to have curves with pronounced local maxima/minima? None of the above do.
I wish someone could draw these curves with the confidence intervals around them.
How accurately do we really know these things.
your wish … my excuse not to grade exams!
That’s some damn awesome customer service. :p Thanks.
Okay: but here’s the $1M question: do you find my spikes “meh” or merely “not … awful”?
The spikes seem fine to me. Just that I’m more used to seeing the shaded envelope around the curve representation for CIs.
Sometimes one likes something for no better reason than familiarity.
Thanks! If you send me email w/ address, I’ll send you a cool CCP “customer appreciation” gift (& promise not to see your contact info to marketing firm)
Those CI’s seem very tight but how about a different question: Say you went to the same person twice in a short period, say within a week, and queried him how tightly correlated are his responses?
Isn’t this another way to read whether tightly clustered curves mean anything different from each other?
I’m not 100% sure what result I’d get if a re-tested in that way.
But I’m 99% sure that the results would be pretty much the same.
I’ve asked questions like these a gazillion times in the last few yrs & observed the same results. The same in the sense that the covariances among the items & between the items & various measures of people’s “values” or “identities” (partisan identification & liberal-conservative ideology; “cultural worldviews”; religiosity; “country or rock & roll?” [just kidding on last one]) are the same.
Here’s something sort of new, too: look at the near-identity of how these items, on the one hand, and ones that solicit related “risk perceptions,” on the other, covary w/ political outlooks. That’s even more miraculous than Josh & Andrews savant-level Political Polarization IQs!
Now you might ask– “why do you measure these things gazillions of times?”
The answer is related to the motivation, I gather, for your question about test/retest.
In fact, I *don’t* think that policy items or risk items that are this intimately connected to one another “mean anything different from each other.” (But note, of course, that *not* all the policy items are correlated with each other or with left-right outlooks as intimately as global warming, gay marriage, affirmative action, universal health care, & gun control are; so I assume those are what you are asking about.)
I think they are all just observable indicators of some unobserved disposition to form views characteristic of groups that play a pretty important role in people’s lives. I measure these kinds of things routinely in studies that I do — on, say, how people feel about vaccines or what sorts of things influence curiosity in science — so that I can combine them into “dispositional” scales that I can use to test hypotheses about how people with different identities will respond to one or another influence.
Whaddya think of that?
Yes, but none of this tells us about the *within-person* consistency of your measure right?
e.g. Say I want to buy a thermometer to precisely regulate a process the first thing I worry about is repeatablity of the instrument. If my thermometer has a repeatablity of only 10 degrees then there’s no point distinguishing between two process trend lines that are only 5 degrees apart on a chart.
Ergo, what I’m wanting to know is how repeatable is your measurement?
i.e. Same person, same questionnaire. Only different points in time: How correlated are individual answers?
I’m very impressed. Curves 9 and 10 are very similar; so are 2 and 7; so are 6, 4, and 1. Only 3 and 8 don’t have a nearby counterpart. (Hmm, I guess this is probably covers in Kahan’s scoring scheme, which I haven’t looked at).
8 out of 10 correct, that’s just amazing.
In honesty, the only thing I was particularly interested in was gay marriage.
Or maybe a little bit vaccines, since I know people grossly overestimate the degree of public ambivalence about universal immunization & often form one or another unsupported idea that opposition to that policy is correlated with political views.
But on gay marriage, it seems to me, there is a narrative on the left that asserts the legalization of gay marriage occurred as a result of an “astonishing transformation in public opinion” etc. I discuss this in the blog that goes through answer.
It’s “common wisdom” that partisans form exaggerated perceptions of strength & uniforming of opinion within their party & strength & uniformity of opposing position in other party.
I suspect that does’t hold on gay marriage. My guess is that people on the left are likely to underestimate division on this issue as a result of biased information exposure, compounded by social influences that connect reputation within the group to forming beliefs that it’s views are “progressively triumphing” etc.
But am just guessing/conjecturing.
And obviously I would never generalize from Andrew & Josh’s reactions. On anything.
Where is the 5 point liberal-conservative scale defined? I couldn’t find it despite a fair amount of Googling. Depending on how that axis is defined this could be tautological. Being a liberal isn’t the cause of supporting gay marriage, but the label (classification) applied to people who support gay marriage.
This graph appears to show that certain attitudes are clustered together. It doesn’t answer the much more interesting and difficult question, why? What causes this phenomenon?
The x-axis is standardized sum of standardized responses to
(1) “How would you describe your political views?”
1 = very liberal
2 = liberal
3 = moderate
4 = conservative
5 = very conservative
(2) “Generally speaking, do you usually think of yourself as a Republican, a Democrat, or an Independent?” plus follows ups: w/ followups “Would you call yourself a strong Democrat/Republican or a not very strong Democrat/Republican” or “As an independent, do you consider yourself to lean Democrat, lean Repubican, or not lean either way?”
1= Strong Democrat
2 =Not very strong
3= [Independent] Lean Democrat
4 = Independent
5 = [Independent] Lean Republican
6= Not very strong Republican
Standard items.
The responses to items correlate at r=0.67, so the resulting index is a pretty reliable of some underlying “political identity” disposition.
Tautology … well, one would expect policy items that reflect left-right to correlate w/ an index like this; one can thus use the index to compare how intensely divided partisans are or whether in fact a particular policy divides them.
Or if you like to think about these things as all just issues of measuring unobserved things– like underlying political idendeity dispositions — based on observable ones (responses to survey items), you can figure out which sorts of policy items you might combine w/ these response to form an even better scale. (For sure one can treat items on “climate change” as measures of “left-right” political outlooks in this way & form HGH-engorged political ideology scales.
Or if you prefer form a scale with just the policy items (perhaps two– one for “social conservative” & another for “economic”).
All pretty standard stuff!
Agreed that the graph doesn’t show what *causes* the dispostions that are being indicated in this way by the items. You tell me & we’ll split the Nobel Prize.
erratum/addendum:
“… 7 = Strong Republican …”
With respect to our shared Nobel Prize, if I knew what pattern of neuronal connections caused liberalism or conservatism that would be impressive indeed. Sadly that is way beyond my capabilities. In any event I had more modest goals in mind. I find the standard left/right axis unsatisfactory and am looking for something with more explanatory power, perhaps something like the Big 5 in psychology.
Gay marriage is a good example of why I don’t like the standard left/right dichotomy. There were(and are) communist governments that prohibited gay marriage. Wouldn’t a communist be considered on the “left”? On the other hand, there are some right libertarians who are pro gay marriage. These are people who self-identify with the “right”. So, to me, that shows that it isn’t as simple as leftists support gay marriage and rightists are against it (not that this is what you are claiming). I think explaining this phenomenon requires something more.
Here is my attempt. I think we can split the gay marriage topic into at least two independent factors: attitude towards homosexuality and attitude towards the role of government. With the former we might create a scale that runs from strong approval to strong disapproval. I wouldn’t label this attitude “political” but I’m not sure what to call it. For the second factor, we might ask something like “Should the government be allowed to prohibit consenting adults from getting married?” This, to me, is the actual political factor. I suppose responses to this question could range from always to sometimes to never.
These still aren’t that great. Maybe the attitude towards homosexuality is part of a more fundamental traditionalism factor. And maybe the government question I posited above could be captured by an authoritarianism scale.
what do you think correlations are between
a. legalize gay marriage prohibit interracial marraige; and
b. prohibit interracial marriage & left_right index featured here?
I don’t know how they correlate. If the preferences expressed in (a) do correlate, then I would ask why do they correlate? Or more generally, why do certain social and political preferences (as expressed in responses to survey questions) tend to cluster the way they do?
The graph above does show well that certain preferences correlate but it doesn’t tell me why they do. So, all I am suggesting is that a model with greater explanatory power would not be based on a simple liberal/conservative axis; an axis which is not even comprehensive as many people do not identify as liberal or conservative.
I wandered over here from Dan Kahan’s place to see what all the Gelman fuss was about.
So far I’ve read through some very interesting material: Will Public Opinion about Inequality Be Packaged into Neatly Partisan Positions?, The Mythical Swing Voter, Increasing Transparency through a Multiverse Analysis, and Reviews of Red State, Blue State, Rich State, Poor Stat, plus Gelman’s excellent 14.5 minute podcast at the book website (Note: If you want people to actually buy your books, twitterstorms are great, detailed informative analysis that makes the reader think that they can skate along without reading the actual book, not so much. But maybe life in the ivory tower diminishes the financial urgency). I’ve also read smatterings of Gelman website power point presentations and statistical papers (I’m an analytical chemist, never heard of STAN). I say all this to accentuate how presumptuous it is of me to express an opinion in the presence of so learned a statistician as Gelman, on how Dan Kahan’s statistical analysis is performed. Which I will then proceed to do anyway. (Dan has equal academic stature, but then, as a regular commenter on his blog, he’s used to me by now)
So given the above post, it seemed like a good idea to me bring my comment from Dan’s blog to this one for further discussion:
There wouldn’t be a point to political parties if some things weren’t polarizing, and some of those things ought to define the parties themselves. So the polarizing things are confounded with the definition of left and right. Individuals can have multiple tribal identities. Individuals can also express opinions on things regarding which they have little actual interest or minimal expertise.
Rahul seems to me to be interested in the reproducibility of peoples opinions of their own opinions. I think that misses the key issue. I am closer to agreeing with Samedi, the left to right scale needs to be defined, and in some policy instances, could be tautological. Once “liberal” has been summed with “Strong Democrat” I think that the line can become ambiguated. And that means that the ability to see some issues as polarizing has been obliterated. Debbie Wasserman Schultz for example, as chair of the Democratic National Committee, would undoubtedly see herself as a very strong Democrat. Her opponent, Tim Canova, is also a Democrat and strongly to the left. IMHO, the two of them do not want to end up standing right next to each other in this lineup. Run a test on the polarization of payday loans and they’d cancel themselves out as if it were not a significant issue at that end of the scale.
Political party affiliation is a lagging tribal indicator. Ronald Reagan ran for President as an outsider. He was able to convince many people that the policies of the Democratic Party, of which they were still nominal members, no longer spoke for them. In my opinion, something similar is happening today.
On the issues of childhood vaccination. Dan Kahan has pointed out that we have broad cultural consensus that favors vaccination. The actual short term decision making on this is relevant to only one small subset of the population at any point in time, those that have infants and small children. Given the idea that vaccination has wide acceptance, where is the large groundswell of bi-partsan popular support for an aggressive program to contain the Zika virus, for which developing a vaccine might be an important component? I assume that it is not near the top of many people’s list of items of importance.
I believe that the partisan political significance of gay marriage (or transexual bathrooms) is that they could serve as a wedge issues. Following after Kansas and Connecticut, I think that the next state in the “What’s the Matter With” series could be North Carolina. North Carolina has a bubble of high tech culture concentrated in Research Triangle Park. RTP was placed there to take advantage of the local institutions of higher education in North Carolina, at UNC, Duke, North Carolina Central, and NC State. Charlotte has leveraged it’s position as a banking center. Both attract considerable numbers of outsiders. (I’ve been one such for a while). We drop in, delighted to find McMansions on acreage are easily affordable. This seems to make some of the white locals feel like a whole way of life is being challenged by a bunch of incomprehensible aliens. In my experience, out from the big cities, the concentration, and cultural dominance of, evangelical Christians, both black and white, is quite high, and that seemed foreign. If Dan wants to be the author of the NC edition of What’s the Matter? book, I think he should, as mentioned above, test the correlation between support for gay marriage as opposed to interracial marriage and and also plot that against race and additionally the level of evangelical Christian religiosity. I don’t think “left_right index featured here” is an adequate metric. Trump is ruining this for the Republicans in this election cycle, but my belief is that white liberals could be separated from black evangelicals who now vote Democratic. This would take a union of Evangelicals separated mostly only by skin color and past bad experiences. But this could leave North Carolina as a very conservative place, collectively bitter that the good times of RTP were never really delivered to them.
Gelman does a good job dissecting the politics of inequality. He notes that “Our main argument throughout is that efforts to force public views about inequality into conventional partisan politics do violence to the foundation of these public views. “ In my opinion, this analysis would benefit from adding a differentiation of “Warren Buffet” style corporations from “Elon Musk” ones. I’d also add the analysis of our future digital economy as given by Jaron Lanier in “Who Owns the Future?”. In my opinion, coping with job loss in this round of “industrial revolution” is as important to humans as coping with climate change. (Actively addressing the later could help with the former). As noted by Thomas Frank in his latest book, “Listen Liberal”, reactions to a class-ism of professionals can be as significant as reactions to an economic oligarchy.
What you have here is some sort of highly polluted, mucky swamp. Sure there are individual components in there, but pulling them out for analysis requires an understanding of the phase changes they may be capable of in the dynamic equilibrium of their native environment, and how that affects sampling.
For Dan Kahan’s next contest, WSMD?, JA, I think that the first issue is what can be done with the existing data. For starters, I’d like to see a plot that separates liberal/conservative from strong Democrat/strong Republican. In the categories of things that might have to wait for the next funding round, I’d also like to see the respondents evaluate where they’d put various political candidates on these scales relative to themselves. (With a special award for those who can place Trump!). And I’d like to see the respondents order the issues by their significance, as they see it. I think a multivariate analysis would be appropriate, but then there is the matter of how to visually display it.
I’m also very interested in knowing what Andrew Gelman would do.
RAhul–
I can’t give you test-retest on these items. I could oncultural worldviews, if that is of interest. (I might have to hunt a while for data!)
But tell me: why do you think test-retest is a distinctively informative way to get at reliability here?
There are alternatives.
The “left_right” index featured assumes that there is some common unobserved variable — some shared general attitudinal dispositon — that is “causing” responses to the two items the index comprises. I could add more items — maybe ones from the policy battery. Cronbach’s alpha is a reliability index, derived from the covariance of items combined in this way, that then allows me to gauge how much variance in the composite scale is due to true variance in the disposition as opposed to measurement error. From alpha I can determine how useful the scale will be in helping me to measure covariance between the latent variable measured by the scale & other things in the world it might be related to.
Now you might say, “how do you know that the covariance measured cross-sectionally like that is stable– that it isn’t an artifact of scome weird, transient thing that was happening at tiime you made your measurements?”
Test-retest is one way to figure that out; but it is *not* the only way!
I can administered the items to another sample drawn from the same population. If I observe the same covariance structure in the items, then that’s more reason to think they are covarying *because* they in fact are measuring some sort of latent disposition that exists in that population. All the more reason to think, that, too, if the disposition measured in that way covaries w/ other things in the same way over time.
And all the more if I do this over & over & over.
But there could be a reason to care about test-retest notwithstanding all of this. I might care about it, e.g., if instead of trying to explain dynamics of public opinion, I were trying to predict performance of particular individuals in tasks that they will perform over & over, etc.
But tell me why you prefer test-rest reliability here?
@Dan
Sorry, didn’t notice your reply earlier.
I’m not expert at this. I just assumed test-retest would be a gold-standard of pretty much any measurement.
e.g. To offer an analogy: If my thermometer is only accurate to 10 degrees at best, I’d view any conclusion predicated on a 2 degree empirical temperature difference between males and females with a bit of skepticism.
In other words, how do we measure the reliability of your measuring instrument, the survey questionnaire, at measuring whatever it purports to measure unless you can demonstrate a good test-to-retest stability?
If the measurement does fluctuate a lot how do I know that’s dynamics of public opinion and not just measurement noise?
@Rahul–
Screw expertise. The only currency of exchange here should be making arguments that an open-minded critical people can see the strength of. If I said, “trust me I’m an expert,” or “look — here’s a bunch of experts who disagree with you, so shut up,” then you should just tune out. I tune out when people carry on that way…
So,.like I said, test-retest is one way– but only one.
To elaborate, here’s an answer that builds on last one I gave but take on board your analogy.
I sample what I identify “thermometers” from around NYC, first in June, then in Jan. They covary in way that makes me think they are measuring the same thing.
I know based on “theory” that it’s hotter in June than in Jan. The mean temperatures for my two my JUne sample was higher than my Jan. one. Good!
But I decide I’d like to externally validate w/ some idependent data, too, that I have reason to think is good indicator of the latent varaible “temperature” outside. So I sample thermometers in NYT — an entirely different set from either of the last two times — in Jan & in June & see same relationship. I also collected data on mitten wearing & notice that there is a correlation between tempeerature — in my two data sets — & wearing mittens (it has the right sign even!).
Well, there you go. I think the criteria I have for identifying things as “thermometers” is a decent indicator of unobserved variable of “temperature” in NYC– even though I’ve never test-retested any individual thermometer. NOr did I test-retest mitten wearing–which I’m treating as another observable measure of the latent variable “tempeature in NYC.”
BTW, your thermometer might suck. And you might be insane & wear mittens or not for who knows what reason. Test-retest would be better for that. But I’m not certifying your thermometer or you! I’m trying to learn something about the weather in NYC…
So again …
If I show you w/ multiple data sets that putatitive indicators of latent political orientation dispositoin covary in stable way over time across different samples that’s evidence that the thing I’m measuring is a real thing in the population I”m sampling. If I show you that it has same relation over time to issues that I have reason to think such a disposition should correlate with, I’m externally validating the scale. Having done that, I can then try to use the scale to learn something about how the dispositoin relates to other issues or changes w/r/t them over time or across place.
I’m not necessarily telling you about the consistency of individuals inside the groups, though. It’s possible that I’ll do a pretty mediocre job predicting individuals.
But I’m not in the job of predicting indiciduals– any more than I was, in my “analogy” in the job of certifying thermometers.
Individuals are, for my purposes, *noise*. I’m interested in how big aggregations of them shape cutlure & politics. I don’t have to have precision measurement at individual level to do that so long as the imprecision at individual level doesn’t deteract from the validity & reliability of measures at group level. I can track how large groups of people who share the latent disposition being measured, consistently, with the scales react to particular issues even if I might be pretty mediocre at diagnosing individuals.
As I adverted to earlier, I’d be more focused on test-retest if I were trying to measure apptitude of an individual for, say, a job (like being your individual thermomenter). In fact test-retest has well known problems in that too– in part b/c when people do tests more than once, they are “learning” the test.
But leave that aside– the point is that there’s no “gold standard” for measurement reliability. There’s a bunch of things we can do. They give us more evidence than we would have otherwise.
How much? You decide! But let’s not make mistake of thinking that only any particular thing is “the right one” or that any of the various things in the class of “right things” is by itself decisive.
BTW, what does your thermometer say today?… And are you wearing mittens?
Thanks Dan.
To stretch the analogy further: I’d totally agree that even the untested “thermometer” is a decent indicator of “hottness”.
But is it valid to take an untested thermometer (which in reality is no more than 10 degrees accurate) & plot your readings to a 0.1 degree accuracy on a graph of temperatures? Even if we are clear that what’s being plotted is not any particular individual location but only an aggregate of the NY area.
In other words, I don’t question that the survey does measure the probability of supporting. But are we overselling how accurately it measures it? And drawing fine-grained conclusions that would require an accuracy our measurements don’t have? Those CI’s you plotted for me were so tight it made me wonder…..
+1
Oy!
1. I plotted the CIs only b/c you asked! As I explained when I did so (look & see!), I think the CIs are uninteresting here. The lowess lines are sufficient for the inferences that I was extracting & inviting others to extract form the data: the point was to sort the issues into groups based on relative polarization — not make claims about point estimates, something I never did. Now you say you agree the measures are fine for what I said *could* be done w/ them! I’m taking back the t-shirt I never sent you!
2. The CIs being “tight” is a consequence of nothing more or less than the size of the sample. You are perfectly right to wonder about whether the measures are valid — but nothing in the CIs can help us figure that out.
How can the CI’s ever be uninteresting?! I don’t mean CI’s in the narrow sense formulaic-ally computed. But in the sense of “when I plot this point how much wrong can I be?”
By ignoring issues other than the sample size, in particular measurement-accuracy issues, aren’t you exaggerating the confidence one should have in those lines? Especially when the lines are really close to each other.
I just find the approach dis-concerting: “Since I’m looking for an aggregate measure I don’t need to bother to measure the reliability / accuracy of my measurement tool at the individual observation level. Even though I will be taking individual measurements to compute the aggregate.”
I guess I’m just not used to working with un-calibrated instruments.
all you mathy CompSci types doing r , etc, can you please figure out some better defaults for graphs ?
even assuming normal color vision, it is a horrid graph
and we live with it cause the defaults in excel or whatever are so totally crappy beyond belief
(if you stop and think for even one second,and you are older then 50, you will realize that our graphing practice derives from the era of hand (human labor) set type, when it was $$ to do graphics, and $$$ to do things like adding labels at the end of the curve (hence the horrid practice of complex impossible to follow legends…)
is is as if you ran R code with punch card stacks….
isn’t anyone willing to take this on ??????
Not to mention, I think all you R stats compsci guys get like a D- for not promoting the universal use of disjoint cartograms (state level) for US national data….
Ezra:
Pay us and we’ll do that for you.
(I’m not completely kidding. It’s a lot easier for math/stat/CS people to get research grants to prove theorems than to make better graphics.)
Ezra– show me! I’m all ears/eyes. For incentive, I’ve even offered a friggin’ *amazing* prize.
I know am only “not … awful”; I aspire to “meh”– so help me out!
In my opinion, more attention needs to be paid here to how the partisan positions are depicted graphically, and not just with regard to presentation, such as color. One could imagine a system that worked by consensus, and then would be represented by how far voters were from converging on one point. The heavy use of the concept “to triangulate” in politics indicated that 3 way splits are possible. And obviously things could get much more complicated than that. We do have a 2 party system so a line seems as if it might be possible. A simplified model would have one side favoring “this” the other “that” and elections won or lost based on how well the candidates from either side drew in people willing to accept a little of “this” with their “that”. Polarization obviously then would involve introducing “something else entirely”.
Making a lineup out of people who say they are D or R in varying strengths for varying reasons and then adding to that people who say they are L or C to varying degrees and with varying rationales strikes me as having a potentially huge effect on what supposedly independent factors turns out to be polarizing. Because they are not necessarily independent. Additionally, this primary season shows us that there are other ways of depicting a politician spectrum. There are divides by age, or rural and city residents for example. I know you all get that, but as I noted in a comment above, I think it could be more specifically acknowledged and analyzed here.
There are also issues that are very significant but don’t map well onto the entrenched parties that we have. I think Andrew Gelman explores this well in his paper for this election season: Will Public Opinion about Inequality Be Packaged into Neatly Partisan Positions?.
Dan Kahan could help out by offering better prizes for his contests, Cray computers perhaps, so everyone could engage in elaborate multi-variant analysis.
But then there is sampling. In analytical chemistry, we had to adjust to a much more accurate regime in which industrial quality control (my example) could no longer be accomplished by going around collecting samples in Erlenmeyer flasks and running back to the lab with them, to identify things with wet methods using glassware like burets, but rather needed to be done with online, instream detectors and/or electronic instrumentation such as electron microscopy or mass spectrometry.
In my outside of social science opinion, much time seems to be spent on this blog and at Dan’s worrying about the equivalent of the quality and quantity of Erlenmeyer flasks other authors may or may not be using.
It has recently been demonstrated that Mark Zuckerberg was apparently quite responsive to complaints by Conservatives as to the impacts of the secret algorithms used to control information on the Facebook site. Andrew Gelman has a post up regarding transparency as applied to social science research. I think these thoughts need to be expanded to include Big Data in general. In my opinion, academics need to figure out how society gains access to analysis of the tools and corresponding databases which are robust enough to do all sorts of statistical analyses. Manipulation of these resources, especially in social media, are also quite possibly, or at the very least potentially, the deciders of how partisanship and polarization are shaped in modern society.